NLP-Pipeline
本章主要讲述了 NLP 的语言结构和传统管道
语言结构
表示层次
自然语言是非常复杂的符号系统,其符号(单词、短语、句子等)比普通符号具有更多的内部结构。语言学家通常在语言符号中至少区分以下四个表示层次:
音位结构: 个别声音的层次,或在书面语言中,书写符号、字母;
形态结构: 词素的层次,即最小的有意义的语言单位,以及它们组织成单词;
句法结构: 单词组织成语法正确的句子的层次;
语义结构: 意义的层次,即语言符号所指的内容。
列出的表示层次并未涵盖语言符号的所有重要方面:
语义学,至少传统上,不处理非字面、依赖上下文的意义元素,这些元素属于语用学的范畴,而
对大于句子的单位(段落、整个对话等)内部关系的研究是话语分析的主题。
语法
依靠语言符号(简称 l. 符号)的概念,我们可以定义更多重要的概念:
语言 是一组 l. 符号。
语法 是一个由以下两部分组成的对偶:
一组 l. 符号,即语言的 词汇,以及
一组有限的操作,这些操作将一个或多个 l. 符号映射到一个 l. 符号。
当且仅当 $\mathcal G$ 语法生成 $\mathcal L$ 语言时,$\mathcal L$ 包含正好那些在 $\mathcal G$ 的词汇中或通过有限次应用 $\mathcal G$ 的操作从 $\mathcal G$ 的词汇中产生的 l. 符号。
换句话说,语言 $\mathcal L$ 中的所有符号要么直接在语法 $\mathcal G$ 的词汇表中找到,
要么可以通过语法 $\mathcal G$ 的规则和操作从词汇表中的符号生成。
语法操作通常分解为同时工作的音韵、形态、句法和语义操作。
例如,对于一个作用于语言符号的二元语法操作 $f$,存在相应的音韵、形态等操作,使得
对于 $f$ 的所有可能参数:
根据我们的定义,语法不仅涵盖语言的句法,还包括音韵、形态和语义。
在文献中也经常使用一种更有限的语法概念,它仅限于形态和句法,或者仅限于句法。
此外,语言通常被更狭义地定义为仅包含由语法生成的句子(作为声音或书面符号序列)的集合,而不包括它们的形态、句法和语义结构。
描述语法
语言学的一个核心目标是描述生成自然语言(或其片段)的语法:英语语法、西班牙语语法等。
语法通常通过以下两种方式描述:
显式地,通过描述词汇并定义从中生成语言元素的操作,或
隐式地,通过提供由语法生成的语言的代表性示例,即带有形态、句法等分析的语音或文本样本。
解析和生成
一些与语法相关的任务在 NLP 中尤为重要:
解析
决定一串书面符号是否属于由给定语法生成的语言:它是否由该语言的单词组成,是否在句法上是正确的,以及是否有意义。
确定由给定语法生成的语言中的一串书面符号相对应的形态、句法和语义结构。
生成
无条件生成: 生成语法语言的元素。
条件生成: 生成满足特定条件的语法语言的元素。这些条件通常是语义上的,即生成语义结构(意义)满足特定条件的语言元素。
解析和传统的 NLP 管道
解析任务在传统 NLP 中占据了核心地位,因为人们认为大多数 NLP 任务可以通过以下方式解决:
解析文本输入,并根据特定语法生成其表示结构,
使用生成的分析结果作为进一步处理的特征。
因此,传统的 NLP 管道是一个针对一种或多种语法的解析管道,其中每个组件生成输入表示结构的一部分。
传统管道中的处理任务
形态和句法
- 分词
- 句子切分
- 形态分析
- 词性标注
- (浅层或深层)句法解析
语义
- 命名实体识别
- 词义消歧
- 共指消解 / 实体链接
- 语义角色标注(浅层语义解析)
- (深层)语义解析
管道任务
分词
该任务是将输入字符序列分割成称为tokens的小的有意义的单位,通常是单词和标点符号:
‘This is a sentence.’ $\Rightarrow$ [‘This’, ‘is’, ‘a’, ‘sentence’, ‘.’]
使用 tokens 而不是单词有两个重要的优点:
允许更多的灵活性:标点符号、表情符号等虽然不是单词,但仍然是有用的分割单位;
暗示这些片段是某些类型的实例,这些类型共同构成一个词汇表。
什么应该算作一个 token?
答案取决于任务和模型:例如,对于某些目的,标点符号是无关紧要的,而对于其他目的,句子边界和标点符号是重要的。
尽管如此,一些有影响力的分词风格已经达到了“准标准”状态。对于英语来说,“Penn Treebank 规则”是最常见的,具有以下关键特征:
标点符号与单词分开并作为独立的 token 处理,
动词缩写(如“she’s”中的“’s”)和附加成分(如“don’t”中的“n’t”)被分开。
类型分配和标准化
分词还可以涉及确定 tokens 属于哪种类型。
例如,如果 ‘apple’ 和 ‘Apple’ 是同一类型的实例,那么我们的分词器会将这些标准化或规范化为一个共同的类型,不考虑大小写。典型的规范化实践包括
“纠正”拼写变体和拼写错误,将所有变体分词为同一类型的实例,
标准化数字或日期类型的表达
以及标点符号(例如,将“!!”视为“!”)。
更激进的策略包括将所有数字表达式或所有不在预定义词汇表中的单词分配给单一类型。
分词挑战
分词的挑战取决于任务和方法,还取决于输入的
- 书写/字母系统(例如,没有空格的书写系统!),
- 语言,
- 领域,
- 噪音量(例如,拼写错误的数量)。
对于欧洲语言和书写系统,特别的挑战包括
- 缩写(通常以句号结尾),
- 数字表达式(可能包含空格、逗号和句号),
- “多词表达”(MWEs),如“New York”。
句子切分
该任务是将(通常是预先分词的)输入字符序列分割成句子:
[‘John’, ‘entered’, ‘the’, ‘room’, ‘.’, ‘It’, ‘was’, ‘empty’, ‘.’]
$\Rightarrow$ [[‘John’, ‘entered’, ‘the’, ‘room’, ‘.’], [‘It’, ‘was’, ‘empty’, ‘.’]]
主要挑战是
句子和 token 切分的相互依赖性,例如分割形式为 ‘xxx yyy. Zzzz’ 的片段(’yyy.’ 是句子结尾还是缩写?);
标点符号不正确或缺失。
形态学
词素 (Morphemes) 是语言中最小的有意义单位。单词可以由几个词素组成,例如 unbearables = un + bear + able + s
词素之间的有用区分:
黏着词素 (Bound) vs 自由词素: 自由词素(例如 bear)可以单独作为独立的单词存在,而黏着词素(例如 -un, -s)只能与其他词素一起构成单词。
词缀 vs 词根: 词根 (roots) 是单词的主要部分,具有最具体的语义内容(例子中的 bear),其他词素,即词缀,可以围绕词根放置。大多数词根是自由的。
词缀类型
词缀 (Affixes) 可以根据它们与其他词素的(通常是位置上的)关系进一步分类:
| 词缀类型 | 关系 | 示例 |
|---|---|---|
| prefix 前缀 | 前置 | un-,anti- |
| suffix 后缀 | 后置 | -s 和 -ing |
| infix 中缀 | 中间 | Singabloodypore |
| circumfix 环缀 | 环绕 | 德语中的 ge...t(例如 gespielt) |
| stem 词干变化 | 变化 | 阿拉伯语 kitaab(’书’)$\rightarrow$ kutub(’书籍’) |
这远不是完整的列表,其他词缀类型还包括重复、音调/音高变化等。
一个关键的区别是屈折词缀和派生词缀:
屈折词缀 inflectional,创建同一个词的不同形式,可以表示语法方面如人称、时态等。英语中的例子包括复数 -(e)s 和进行时 -ing。
派生词缀 derivational,则形成新词,例如,bearable 中的 -able 将动词变为形容词。
词干和词元
一个词的 词干 (stem) 由词的基本部分组成,这部分在所有屈折形式中都是共同的。因此,词干通常不是一个有意义的词,例如,produced 的词干是 produc(因为有 producing 等形式)。
词元 (lemma) 与此相反,总是一个完整的词,即屈折形式的未屈折基本形式。继续上面的例子,produced 的词元是 produce。
形态分析任务
Morphological
决定一个字符串是否是一个格式正确的单词。
词干提取: 确定一个单词的词干。
词元化: 确定一个单词的词元。
形态标注: 根据词形变化等表达的语法信息标注输入单词。
形态分割: 将输入单词分割 (segmentation) 成词素。
完整的形态分析: 将单词分割成词素,并根据类型和它们传达的语法信息对每个词素进行分类。通常也包括词元化。
形态分析挑战
歧义 / 依赖上下文: 许多单词有多种分析,只有根据上下文才能消除歧义 (Ambiguity) ,例如 chairs 中的 -s。参见:
The president chairs the meeting.
There were hundreds of chairs in the room.复合词: 许多语言有由两个或更多简单词组成的复合词 (Compounds):例如,德语中的 Schadenfreude (幸灾乐祸) 由 Schaden(“损害”)和 Freude(“快乐”)组成。
形态丰富的语言: 英语的形态相对简单。其他语言,例如匈牙利语和土耳其语则复杂得多……
词性标注
词性(Part-of-speech)类别对应于单词在句子中可以扮演的基本句法角色。例如,在句子
Peter ate the apple.
中,Peter 和 apple 是名词,ate 是动词,the 是限定词。词性标注任务是确定已分词(并可能已句子切分)的输入文本中每个单词的词性类别,例如:
[‘Peter’, ‘ate’, ‘the’, ‘apple’, ‘.’] $\Rightarrow$
[
(‘Peter’, [‘名词’]), (‘ate’, [‘动词’]),
(‘the’, [‘限定词’]), (‘apple’, [‘名词’]),
(‘.’, [‘标点’])
]
同样地,词性的类别也是依赖于上下文的。例如,比较以下句子:
John hit the ball.
His first song was a huge hit in Europe.
具体的词性类别列表及其划分也取决于所使用的语言和特定的语法理论,尽管有些类别是相当普遍的,例如,[名词]、[动词]、[形容词] 和 [副词] 几乎总是存在。
开放 vs. 封闭词性类别
封闭词性类别,例如英语中的限定词,由相对较小的词集组成,这些词集不会轻易改变:添加一个新的限定词到一种语言中是一个罕见的现象。
开放词性类别,例如英语动词,包含大量的词,并且每天都会添加新成员。
一个相关的区别是功能词和内容词之间的区别。属于开放词性类别的词通常是内容词:它们自身具有明确的语义内容。封闭词性类别包含的功能词则没有太多独立的内容。
词性标记集
在 NLP 中,词性类别通常用简写编码,称为词性标记。即使是英语,也有几种标记集在使用;一个非常重要的、与语言无关的标记集是为 Universal Dependencies 项目 开发的:
开放类标记
| 标记 | 描述 | 示例 |
|---|---|---|
| [adj] | 形容词 | big, old, green, African, first |
| [adv] | 副词 | very, well, exactly, tomorrow |
| [intj] | 感叹词 | psst, ouch, bravo, hello |
| [noun] | 名词 | girl, cat, tree, air |
| [propn] | 专有名词 | Mary, John, London, NATO |
| [verb] | 动词 | run, eat, runs, ate |
封闭类标记
| 标记 | 描述 | 示例 |
|---|---|---|
| [adp] | 介词 | in, to, during |
| [aux] | 助动词 | has, is, should, was, must |
| [cconj] | 并列连词 | and, or, but |
| [det] | 限定词 | a, an, the, this, which, any, no |
| [num] | 数词 | 0, 1, 2, one, two |
| [part] | 小品词 | not, ‘s (as in “Andrew’s table”) |
| [pron] | 代词 | I, myself, who |
| [sconj] | 从属连词 | that, if |
其他标记
| 标记 | 描述 | 示例 |
|---|---|---|
| [punct] | 标点符号 | . , ; |
| [sym] | 符号 | $, ¶, © |
| [y] | 其他 | 用于无法分析的元素 |
句法解析
句法理论旨在描述“支配单词如何组合成短语、形成良构 (well formed) 词序列的规则或原则集。”
在这个背景下,最重要的“良构词序列”是句子:句法理论的核心目标是为特定语言找到描述/划定该语言中良构句子的结构规则或原则。
一个句子是良构的,如果它具有结构描述或句法解析,并且满足所讨论理论的句法约束。句法上的良构性并不保证连贯性或有意义性。引用乔姆斯基的著名例子:
Colorless green ideas sleep furiously.
在句法上是良构的,但毫无意义,而
Furiously sleep ideas green colorless.
甚至不是良构的。
成分句法(也称为短语结构)和依存句法理论对 NLP 尤为重要。
成分 (constituent) 是单个单词或一组连续单词,形成一个“自然单位”。例如,短语 a nice little city:
可以放入各种句子框架中,如 I wanted to visit ...,Budapest is ...;
可以作为问题的答案:What did you visit?;
可以用代词替换:I have visited a nice little city. $\Rightarrow$ I have visited it.
基于成分的句法
基于成分的句法理论
对成分进行分类,并且
制定规则,根据这些规则可以将成分组合在一起构建更大的成分,最终构建一个完整的句子。
一个良构句子的句法结构就是它的成分结构,例如,对于句子 The students love their professors:
$$
[
[
The_\mathrm{D} \space students_\mathrm{N}
]\mathrm{NP} \space
[
love\mathrm{Vt} \space
[
their_\mathrm{D} \space professors_\mathrm{N}
] _\mathrm{NP}
] _\mathrm{VP}
] _\mathrm{S}
$$
在更透明的成分树形式中:
1 | S |
这是基于成分的解析器输出的结构。
基于依存的句法
与此相反,依存语法将单词之间的依存关系 (dependency) 视为基本关系。
具体标准因理论而异,但通常在一个句子中,如果一个 $d$ 单词依赖于一个 $h$ 单词(等价于 $h$ 支配 $d$),则
$d$ 修饰 $h$ 的意义,使其更具体,例如 eats $\Rightarrow$ eats bread,eats slowly 等;
并且它们之间存在不对称的可省略关系:可以从句子中省略 $d$ 而保留 $h$,但反之则不行。
依存语法对一个良构句子中的依存关系施加了重要的全局约束,例如:
恰好有一个独立的词(句子的根)。
所有其他词直接依赖于一个词。
由于这些约束,句子的直接依存图是一个树。
大多数依存语法使用类型化的直接依存关系:存在有限的直接依存关系类型列表,并对它们何时可以成立施加特定的约束。
一个依存解析树的例子:
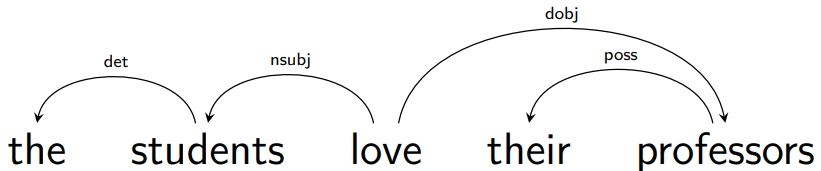
与成分树相比,它包含更少的节点(每个单词一个),但边缘标有相应的依存类型。
命名实体识别
命名实体识别 (Named entity recognition) 是在输入文本中找到命名实体的表达并将其标记为相应实体类型的任务:
](/AI/NLP/NLP-Pipeline/NER.jpg)
通常使用的实体类型有人名、组织和地点,但许多 NER 模型涵盖了其他类型,如日期、事件、艺术作品、法律等。
共指消解
NER 确定名称所指实体的类型,但不决定它们是指相同还是不同的实体。相反,共指消解 (Coreference resolution) 任务是定位输入中的更广泛的指称表达,包括普通名词和代词,并将它们聚类到指向同一实体的组中:
](/AI/NLP/NLP-Pipeline/coref.jpg)
实体链接
与共指消解类似,实体链接也关注引用的身份,但在两个重要方面与之不同:
- 像命名实体识别一样,它仅限于类似名称的表达,
- 它通过将名称连接到外部知识库中的实体记录来确定实体的身份,例如:
](https://upload.wikimedia.org/wikipedia/commons/thumb/7/7d/Entity_Linking_-_Short_Example.png/400px-Entity_Linking_-_Short_Example.png)
词义消歧
词义消歧 (disambiguation) 也将表达与外部词汇表中的意义/词义连接起来,但
它关注普通名词和其他类型的内容词:动词、形容词和副词;
词义集合通常是专门构建的词汇资源——准标准是使用 WordNet 词汇数据库。
例如,一个基于 WordNet 的词义消歧系统应该将句子
The scroll wheel in my mouse has stopped working.
中的 mouse 名词消歧为 WordNet 词义
[Mouse]#4: ‘一种手动操作的电子设备,用于控制光标的坐标 [...]‘。
WordNet 中的其他可能性:
[Mouse]#1: ‘任何数量众多的小型啮齿动物 [...]‘
[Mouse]#2: ‘一个肿胀的瘀伤 [...]‘
[Mouse]#3: ‘一个安静或胆小的人 [...]‘
语义角色标注
语义角色标注 (Semantic role labeling) 是识别输入文本中的谓词 (predicate) 和论元 (argument) 表达,确定哪个论元属于哪个谓词,以及它们之间关系的任务。在这个背景下,
谓词 是指代事件/情况的表达(例如,指代动作的动词),
论元 则指这些事件/情况的参与者,
而任务中的角色标注部分是确定与论元对应的参与者在谓词所指的情况中扮演的角色类型。
一个相对简单的例子,使用宾夕法尼亚大学认知计算组的SLR 演示。
语义解析
这是完整或深层语义解析的任务,它不仅涵盖共指消解、词义消歧和谓词-论元结构,还旨在提供一个完整的形式语义表示,其特点是:
- 表示输入文本的意义的形式结构,
- 表示字面意义,
- 尽可能消歧,
- 在某种程度上是规范的,即一个文本意义有一个唯一的表示,
- 有高效的算法来确定它们与其他语义和知识表示的逻辑和语义关系。
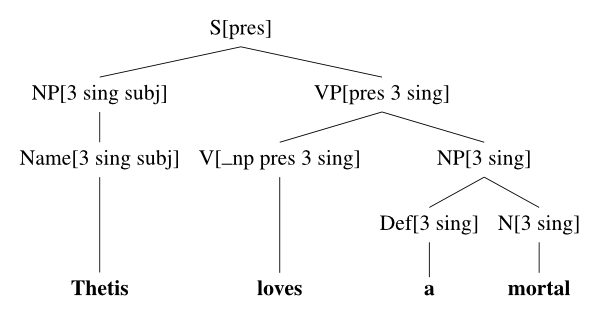
句子 Thetis loves a mortal 的基于一阶逻辑的语义表示:
NLP-Pipeline