数据库概念入门
所以说我们老师考这些的意义是什么呢
第一周
Data -> Database -> Data Warehouse都什么年代了还在用数据仓库
Physical Data 是储存在实体介质上的数据
Logical Data 是指数据的逻辑结构
有 Add / Modify / Delete / Merging / Breaking
这什么玩意写的乱七八糟的
数据独立性
物理独立性
- 程序与磁盘数据相互独立
- 程序不需要了解如何储存数据
- 数据如何储存由 DBMS 管理
- 物理储存改变,程序无需改变
逻辑独立性
- 程序与数据库的逻辑结构相互独立
- 数据逻辑结构改变,程序无需改变
数据独立性的重要性
- 数据质量
- 维护成本
- 安全性
- 结构化
- Implementation (Layers of data)
- 减少重复
- 备份
- 物理层面容易修改,提高性能
合着真就不说人话
三级模式结构
Physical Schema
内模式(储存模式),对应 物理(内部)级
描述了数据在磁盘上的存储方式和物理结构
Conceptual Schema
概念模式(逻辑模式),对应 概念(逻辑)级
是对数据库中全部数据的逻辑结构和特征的总体描述
是全局视图,由 Data Description Language 描述
External Schema
外模式(用户模式),对应 用户(视图)级
是用户所看到的数据库的数据视图
是概念模式的一个子集,包换特定用户使用的那部分数据
由 Data Manipulation Language 操作
关系模型
突然发现老师的 PPT 内容都是网上抄的
概念
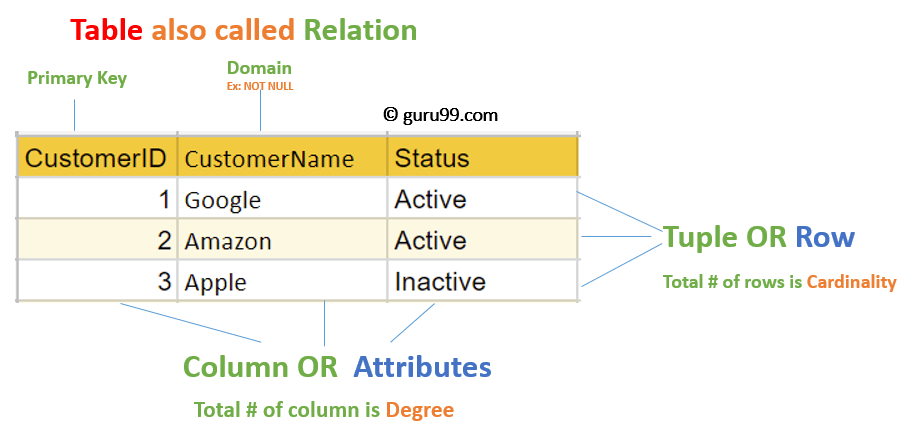
- Attribute: Column
- Table: Relation
- Tuple: Row
- Degree: Count(Column)
- Cardinality: Count(Row)
- Relation key: 比如主键
- Domain: 数据类型,约束等
- Relation Schema: 表名 和 其中的列
- Relation Instance: 表中的数据
完整性约束
Domain Constraints
1 | ... ColName INT CHECK(ColName = 3) NOT NULL ... |
Key Constraints
主键约束
Referential Integrity Constraints
外键约束
优势
- 简单
- 结构独立
- 易用
- 能够查询
- 数据独立
- 可扩展
第二周
- RDBMS: Relational Database Management System
关系型数据库管理系统
SQL
Why
- 方便存取数据
- 有助于描述数据
- 允许对数据库中的数据进行定义和操作
- 创建和删除表
- 创建和使用 函数,View,储存过程
- 设置权限
这些都是老师说的,我持保留意见
Types
DDL: Data Definition Language 定义
- CREATE
- ALTER
- DROP
- TRUNCATE
DML: Data Manipulation Language 操作
- INSERT
- UPDATE
- DELETE
DCL: Data Control Language 权限
- GRANT
- REVOKE
TCL: Transaction Control Language 事务
- COMMIT
- ROLLBACK
- SAVEPOINT
DQL: Data Query Language 查询
- SELECT
索引
查看索引
1 | EXEC sp_helpindex 表名 |
聚集索引
Clustered Index
- 表中行数据的物理顺序与索引的逻辑顺序相同
- 一个表只能有一个聚集索引
- Primary Key 默认
非聚集索引
Nonclustered Index
- 储存的是指向表中行的指针
- UNIQUE 默认
索引覆盖
Covering Indexes
- 索引中包含了所有要查询的字段
- 提高性能
第三周
维护
Maintenance
Repair
- 重组索引
- 重建索引
- 更新统计信息
- 一致性和完整性检查
Consistency and Integrity - 修复和清理
Normalization
数据库规范化
- 保护数据
- 消除冗余
- 消除不一致的依赖关系
不一致
用户在 Customer 表中查找 Address 是合理的
但是在这里查找 负责这个客户的 员工的 Salary 就不合理了
这应该去 Employee 表中查找
不一致的依赖关系 会使数据难以访问
非规范化表
| 学生编号 | 指导教师 | 咨询室 | 课程 1 | 课程 2 | 课程 3 |
|---|---|---|---|---|---|
| 1022 | Jones | 412 | 101-07 | 143-01 | 159-02 |
| 4123 | Smith | 216 | 101-07 | 143-01 | 179-04 |
1NF:消除重复的列
- 消除单个表中的重复列
- 为每组相关数据单独创建一个表
- 使用主键标识每组相关数据
| 学生编号 | 指导教师 | 咨询室 | 课程 |
|---|---|---|---|
| 1022 | Jones | 412 | 101-07 |
| 1022 | Jones | 412 | 143-01 |
| 1022 | Jones | 412 | 159-02 |
| 4123 | Smith | 216 | 101-07 |
| 4123 | Smith | 216 | 143-01 |
| 4123 | Smith | 216 | 179-04 |
2NF:消除重复的行
- 为应用于多条记录的值,创建单独的表
- 用外键连接这些表
Table Student
| 学生编号 | 指导教师 | 咨询室 |
|---|---|---|
| 1022 | Jones | 412 |
| 4123 | Smith | 216 |
Table Course
| 学生编号 | 课程 |
|---|---|
| 1022 | 101-07 |
| 1022 | 143-01 |
| 1022 | 159-02 |
| 4123 | 101-07 |
| 4123 | 143-01 |
| 4123 | 179-04 |
3NF:消除与主键无关的数据
指导教师和咨询室是与学生编号无关的数据
Table Student
| 学生编号 | 指导教师 |
|---|---|
| 1022 | Jones |
| 4123 | Smith |
Table Teacher
| 名称 | 咨询室 |
|---|---|
| Jones | 412 |
| Smith | 216 |
主键
- 不能为空
- 唯一
- 几乎不会改变
- Composite Key
复合主键是指由多个字段组成的主键
外键
- 可空
- 不唯一
- 依赖完整性
ER 图
实体 Entity
用矩形表示,也就是表属性 Attribute
用椭圆表示,也就是列关系 Relationship
用菱形表示,也就是表之间的关系派生属性
可以由其他属性计算得出,虚线
比如Age可以由Birthday计算得出多值属性
可以有多个值,双椭圆
比如书有多个作者复合属性
由多个属性组成
比如名字由姓和名组成可选属性
复合实体
用于多对多联系,矩形内加一个菱形弱实体
必须依赖另一个实体存在
比如学生是强实体,成绩单是弱实体
必须是一对一或者一对多的关系
用双层矩形表示
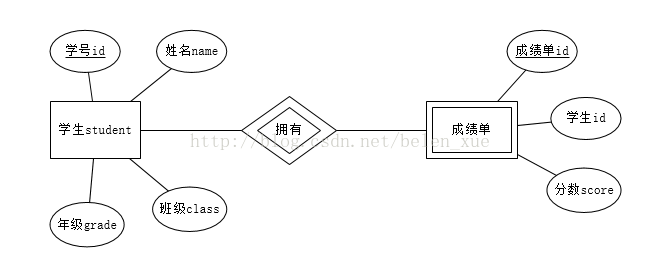
- 一对一
- 一对多
- 多对多
需要复合实体帮助
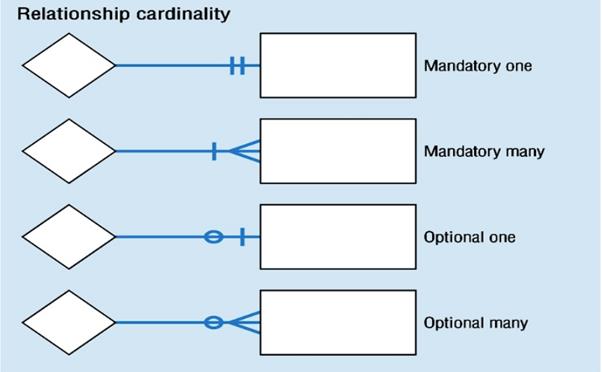
步骤
- Entity Identification
找实体 - Relationship Identification
找关系 - Cardinality Identification
一对多之类的 - Identify Attributes
找 Column - Create the ER Diagram
画图
数据仓库
数据仓库,OLAP,使用数据库系统来帮助洞察业务
典型的有 Redshift,主要用于数据分析
比如,20~30 岁女性用户在过去五年的第一季度化妆品类商品的购买行为与公司进行的促销活动方案之间的关系
数据库是为读写优化的,而数据仓库是为只读优化的
事实表
主要特点是含有大量的数据,并且这些数据是可以汇总,并被记录的维度表
分析数据的窗口,包含事实表中事实记录的特性星形模式 Star
一张事实表和多张维度表组成雪花模式 Snowflake
每一个维度表都可以向外连接多个子维度表星系模式 Galaxy
多个事实表版本的星型模型,多张事实表共用模型中的维度表
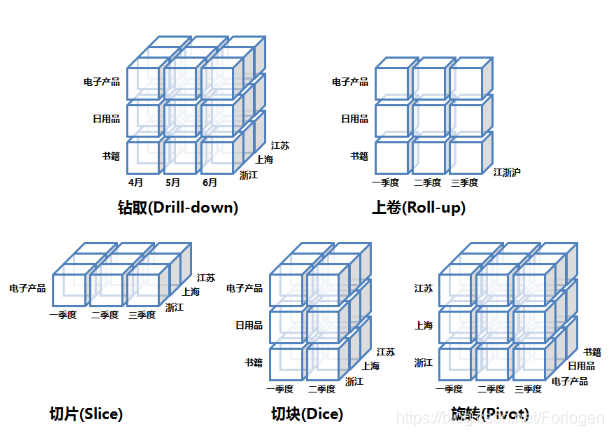
Data Cube
专指那些远大于内存的数据集合,它用来存储和表示多维度数据
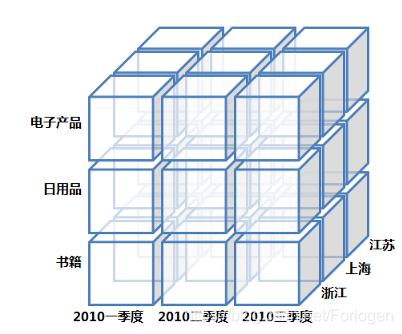
钻取 Drill Down
从高维度到低维度
比如,对第二季度的总销售数据进行钻取
可以得到第二季度中每个月的销售数据上卷 Roll Up
从低维度到高维度
比如,将 4,5,6 月的销售数据进行上卷
可以得到第二季度的销售数据切片 Slice
对特定值进行分析
比如,只选择电子产品的销售数据切块 Dice
对特定范围进行分析
比如,选择第一季度和第二季度的销售数据旋转 Rotate
交换维度
比如,通过旋转实现产品和地域的维度互换
元数据
元数据通常包括有关数据仓库中数据的描述信息、数据的属性和结构、以及数据之间的关系等
元数据可以帮助人们更好地理解和使用数据仓库中的数据,并且在数据仓库的管理和维护方面也起着重要作用