ITDS-简介
我又重生了,这一次我要拿回属于我的一切
什么是 DS
它的目标是:从数据中提取有用的信息
我们将 机器学习的算法应用于各种数据,以训练 AI 来完成通常需要人类进行的任务
这些 AI 会产生一些见解,以供用户将其转化为业务价值
关系
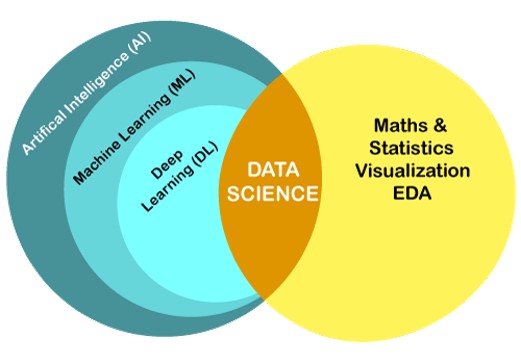
DS 与 ML 密切相关
DS 研究如何从原始数据中提取信息
ML 是 DS 的一种技术,使机器能够自动从过去的数据中学习
AI 使用指导思想,即让机器模仿人类的思维方式
DL 是 ML 的子集,它使用多层神经网络计算
数据科学家:分析数据,寻找模式,训练模型
数据工程师:收集,储存,处理,提供数据给科学家
生命周期
让我们来看看 DS 的生命周期
- 商业需求 Business Requirement
- 数据采集 Data Acquisition
- 数据处理 Data Preprocessing
- 数据分析 Data Exploration
- 建模,使用 ML Modeling
- 部署和优化模型 Deployment and Optimization
数据挖掘步骤
- 明确目标 Learn about the application
- 确定挖掘任务 Identify data mining tasks
- 数据准备 Collect data
- 数据清洗预处理 Clean and preprocess the data
- 数据转换与提取 Transform data or select valuable subsets
- 选择数据挖掘算法 Choose a data mining algorithm
- 数据挖掘 Data mining
- 评估、可视化和解释结果 Evaluate, visualize, and interpret results
- 应用结果 Use results for profit or other goals
数据
我们称数据表的 Columns 为 Features,Rows 为 Samples / Examples / Instances
数据的类型:
- Categorical
分类特征来自无序集合,如 City.{Viena, Paris} - Numerical
数值特征来自有序集合,如 Age.{0, 1, 2, 3, …}
我们偏向于把 Categorical 转化为 Numerical
例如
| Age | City |
|---|---|
| 20 | Viena |
| 30 | Paris |
转化为
| Age | City_Viena | City_Paris |
|---|---|---|
| 20 | 1 | 0 |
| 30 | 0 | 1 |
这样我们就可以将 instance 表达为空间中的一个点,如 (20, 1, 0)
我们可以使用 one hot 编码实现这种转化
随后我们可以:
- 把所有数据映射到空间中,称之为 Feature Space
- 使用 Euclidean Distance 来计算两个点之间的距离
- 用来查找相似内容…
质量
ML 算法需要干净的数据
原始数据有可能:
- Noise
Modicitation of original values - Outliers (异常 / 离群)
与大部分数据有截然不同的特征 - Missing Values
- Duplicates
如同一个人使用不同 ID

数据缺失可能是由于 未收集(拒绝回答),或不适用(未成年人的收入)导致的
可以使用以下方法处理:
- 删除
- 估计 Estimation
- 忽略
对于数据量,一般是越多越好,有一个流行的说法是 十倍于特征数量,但是要保证质量