NLP-Zoo
模型介绍 神 TM 动物园
LLM Zoo
我们已经看到了动物园中的一些居民…

但还有更多!我们将看看一些最重要的语言模型。
(注意:大多数模型在发布时在许多 NLP/NLU 数据集上达到了最先进的水平。我们不会在每个模型下提到这一点。)
BERT 家族
BERT
提醒一下:BERT 是一种基于transformer encoder架构的上下文(子)词表示。它在两个自我监督任务上进行了训练:
- 掩码语言模型(MLM)
- 下一句预测(NSP)
它有几种尺寸:
- 基础版:12 个 Transformer 块,110M 参数
- 大型版:24 个 Transformer 块,340M 参数
BERT 催生了一整个模型家族,它们保留了架构并通过微调细节寻求改进。
超参数
Hyperparameters,BERT 带来了两个新的训练任务,但 NSP 被证明太简单了。
- ALBERT 用句子顺序预测替代了它
- RoBERTa 完全放弃了这个任务
RoBERTa 证明了训练更长时间和使用更多数据的重要性。
- 数据大小:16GB $\rightarrow$ 160GB
- 批量大小:256 $\rightarrow$ 8K
- 训练步骤:100K(相对)$\rightarrow$ 500K
- 动态掩码:
[MASK]标记的位置每次运行都会改变
这些变化在各种任务上带来了$3-4%$的改进(例如在 SQuaD 上减少了$60%$的错误率)。
跨距
Spans,BERT 的掩码方案([MASK]替换单个标记)使其在生成任务中难以使用(例如在问答中填充答案):
奥克尼群岛上最古老的定居点是什么?
最古老的定居点是[MASK]。最古老的定居点是[MASK] [MASK]。- …
(Skara Brae 实际上是 4 个标记:S ##kara B ##rae)
另一个问题是被掩码的标记被假定为条件独立的。
- 掩码随机长度的跨距(平均 3.8 个标记)
- 基于跨距周围的标记预测它们:
- 引入了跨距边界目标 $\mathcal{L}_{SBO}$,使得
- 完全不使用
[MASK]标记或 MLM - 自回归 autoregressive 训练任务在排列序列上(仍然是双向上下文)
- 可以建模上下文和目标之间的依赖关系
性能
训练类似 BERT 的模型速度慢且占用大量内存。ALBERT通过以下方式解决了这些问题:
将$V \times H$嵌入矩阵分解为两个矩阵:
$V \times E$ 和 $E \times H$;
($V$:词汇表,$H$:隐藏层大小,$E$:嵌入大小;在 BERT 中,$E = H$)层之间的权重共享
结果模型的参数比相应的 BERT 模型少 18 倍,训练速度快约 1.7 倍。然而,更大的模型(xxlarge)在性能上超过了 BERT Large (如果它们能收敛的话…)。
新技术
DeBERTa 通过技术创新改进了常规 BERT:
- 解耦注意力(disentangled)机制为每个标记分配两个向量:
- 内容
- 位置
- 相对位置编码
- 在 softmax 层之前引入绝对位置
它在 SuperGLUE 中表现优于人类基线(90.3 对 89.8)。
全栈模型
T5
文本到文本转换 Transformer通过以下方式解决 NLP 任务:
- 将它们转换为带提示的 seq2seq 问题
- 用解码器替换 BERT 上的分类器头
它的训练方式为:
- 去噪 Denoising 目标:丢弃 15%的标记(类似于 MLM;优于自回归目标)
- 多任务预训练
- 在单个 NLP 任务上进行微调
最大的模型有 110 亿参数,并在 1 万亿个标记上进行了训练。
解码器模型
GPT 家族
GPT 家族是最著名的大型语言模型(LLM)。它们由OpenAI创建,规模不断增加:
| 模型 | 参数量 | 语料库 | 上下文长度 |
|---|---|---|---|
| GPT-1 | 110M | 1B | 512 |
| GPT-2 | 1.5B | 40GB | 1024 |
| GPT-3 | 175B | 300B | 2048 |
| InstructGPT | 175B | 77k | 2048 |
| GPT-4 | ? | ? | 8192 |
GPT-3.5 和 GPT-4 的详细信息尚不可用。有一些估计,但许多甚至无法正确描述之前的模型。
GPT-1
最初,GPT 被设计为一个自然语言理解(NLU)框架,类似于 ELMo 或 BERT:
- 它是第一个推广预训练 + 微调方法用于 NLP 任务的模型
- 自回归预训练并非出于文本生成的动机
结果:
- GPT-1 在测试的 12 个任务中有 9 个达到了最先进的水平
- 它展示了一些零样本能力
GPT-2
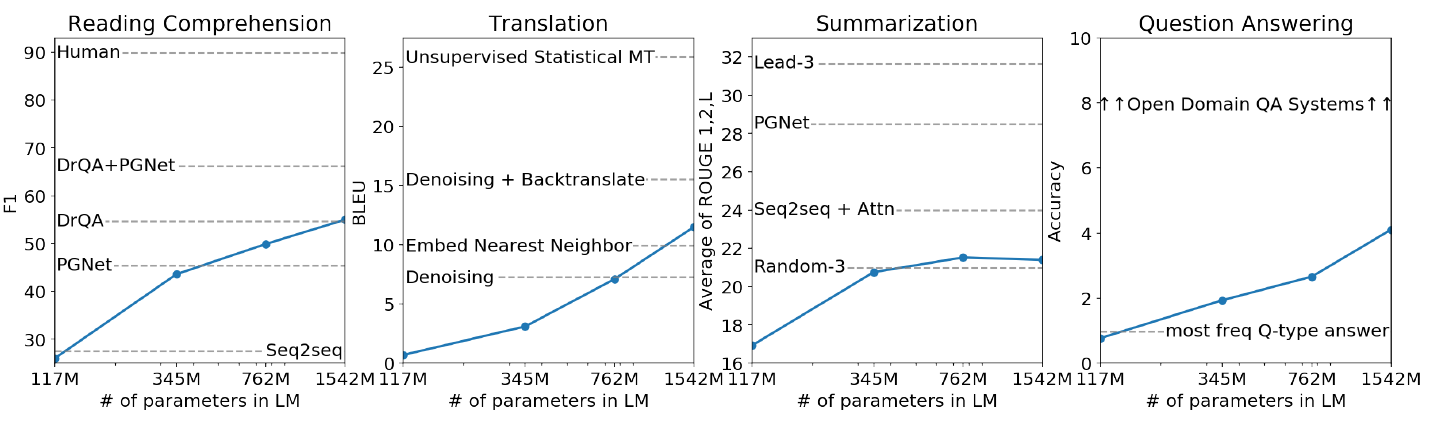
更大的模型尺寸带来了更好的零样本性能:

GPT-3
架构和训练的变化:
- 交替使用密集和稀疏(dense and sparse)注意力层
- 采样训练(并非使用所有训练数据)
在几个任务上的少样本性能非常接近最先进水平。
问题:
- 防止基准测试的记忆化
- 输出中的偏见(性别、种族、宗教)
- 训练期间的高能耗(通过相对较小的训练语料库缓解)
InstructGPT
增加了指令支持。
- RLHF(之前提到过)
- 与增加预训练分布对数似然的更新混合,以防止模型退化
- 1.3B 的 InstructGPT 比 175B 的 GPT-3 更受欢迎
- API prompts 比 FLAN 或 T0 数据集更好
- 降低了毒性(toxicity),但没有减少偏见(bias)
GPT-4
更大、更好、多模态(视觉)。在考试中表现达到人类水平(前 10%)。
指令:
- 对考试没有帮助
- 扭曲(Skews)了置信度校准(calibration)(答案的对数似然与实际表现的相关性)
两种安全方法:
- RLHF
- 基于规则的奖励模型(RBRMs)
其他模型家族
GPT 并不是唯一的 LLM 模型“家族”。还有一些竞争对手,包括开源和闭源的。
其他模型
仅解码自回归模型已成为事实上的 LLM 标准,并且提出了许多其他模型。以下是一些值得注意的例子。
- Megatron
- GPT(8.3B)和 BERT(3.9B)版本。训练于 174GB 文本
- 引入了模型并行(parallelism)
- Gopher
- 280B,训练于 MassiveText,但仅在 2350B 中的 300B 标记上(12.8%)
- 使用相对位置编码,允许对比训练期间看到的更长序列进行推理
- GLaM
- 一个稀疏模型,具有 1.2T 参数,训练于 1.6T 标记
- 使用专家混合(Mixture of Experts)层与 transformer 层交错
- 每个标记仅激活模型的 8%(96.6B)
训练成本是 GPT-3 的 $\frac{1}{3}$
- LaMDA
- 137B,训练于 1.56T 标记
- 一个专门用于对话的模型;训练语料库的 50% 由对话组成
- 针对质量、安全性和基础性(“基础指标”)进行微调
- 端到端模型,包括调用外部 IR 系统以确保基础性
- FLAN
- 基于 LaMDA。使用数据集成方法进行指令微调,来自 62 个 NLP 数据集
- 比 LaMDA、GPT-3 或 GLaM 更好的零样本性能
- PaLM
- 最大的模型之一:540B 参数,训练于 780B 文本
- 使用Pathways技术在 2 个 Pods 中的 6144 个 TPU v4 芯片上训练
- 不连续的改进:在某个模型大小之后准确性急剧跳跃(而不是连续的幂律)
- 突破性表现。在几个任务上,它比
- 平均人类表现
- 监督系统
更好
负面趋势
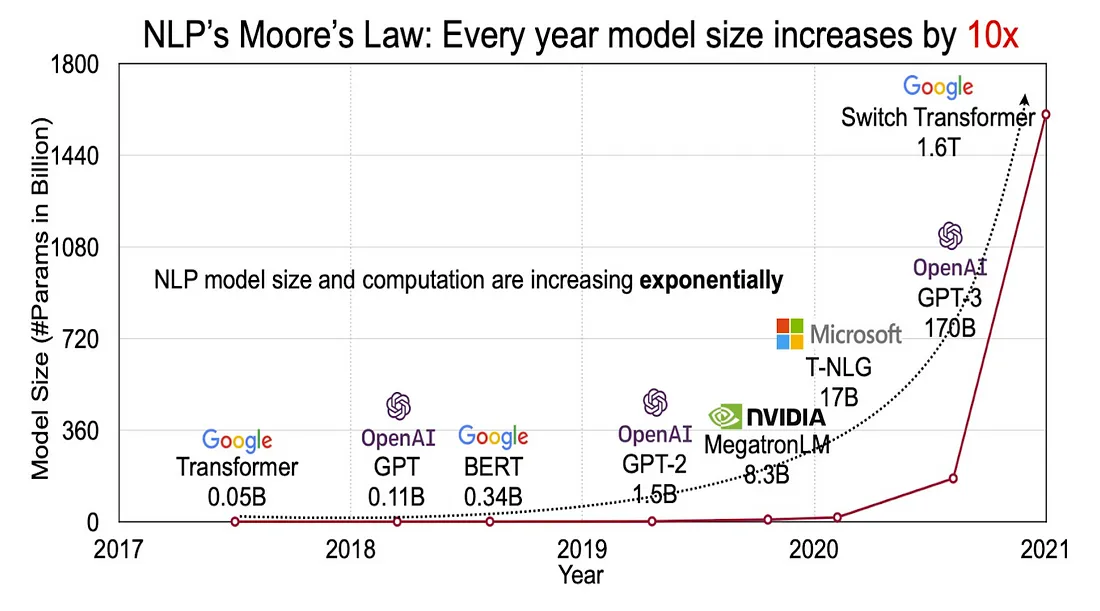
扩展法则
已经证明,增加模型规模会沿着幂律曲线提高性能。这导致了越来越大的模型被发布。
问题
大型模型有几个问题:
- 它们的训练和推理成本很高
- 只有少数参与者能够负担得起训练它们
- 即使在“低端”设备(例如 8 个 A100)上运行它们也是有问题的
- 它们有相当大的碳足迹,以至于论文现在通常会报告它
- 大多数模型是专有的和闭源的
新趋势

Chinchilla
最近出现了一种新趋势,即在更多的标记上训练较小的模型,以实现可比甚至更好的结果。这是可能的,因为
- 上述模型通常训练不足
- 指令微调非常有效且便宜
Chinchilla
- 70B 参数,训练于 1.5T 标记
- 使用与 Gopher 相同数量的 FLOPs 和相同的训练集
- 性能优于 GPT-3 和 Gopher
LLaMa
Chinchilla 是闭源的。LLaMa 是基于开放数据源创建类似 Chinchilla 模型的尝试。
- 最大的模型是 65B,训练于 1.4T 标记
- 包括架构上的“最佳实践”
- 预归一化(GPT3):在输入而不是输出上归一化
- SwiGLU 激活(PaLM)
- 旋转位置嵌入(GPTNeo)
- 即使是 13B 模型也优于 GPT-3
注意:不能用于商业用途。
LLaMa 变体
LLaMa2
- 更大(70B 参数,2.0T 标记,4k 上下文)
- 聊天指令
- 可以用于商业用途
Alpaca
- 斯坦福基于 LLaMa 7B 的指令模型。便宜($600)
- 基于 ChatGPT 的 Self-instruct(不可商业使用)
Vicuna
- 基于 LLaMa 13B + 来自 ShareGPT 的 70k 交互,成本 $300
- 比 Alpaca 好 90%,在 GPT-4 评判下接近 ChatGPT 10% 以内
多语言模型
上述大多数模型仅在英语数据上训练,或最多包含 10%的非英语文本。然而,有几个模型有多语言版本。
mBERT:
- 一个多语言的 BERT 基础模型
- 在 104 种语言的维基百科上训练
XLM-RoBERTa
- 在 2.5TB 的 Common Crawl(CC)数据上训练,涵盖 100 种语言
- 在低资源语言上比 mBERT 高出 23%
- 性能与单语言的 RoBERTa 相当
XLM-RoBERTa 证明了维基百科不足以训练一个有竞争力的模型。
mT5
- 在包含 10,000 页或更多页面的 101 种语言的 CC 数据上训练
- 单语言性能接近 T5
- 跨语言零样本性能是最先进的,但偶尔会意外翻译成英语
BLOOM
- 一个在 46 种自然语言和 13 种编程语言上训练的解码器模型
- 1.61TB 的 ROOTS 语料库由国际研究人员合作编译
- BLOOMZ 变体经过多语言多任务微调
- 迄今为止最强大的多语言 LLM
编码

许多 LLM 在预训练语料库中使用了一些源代码。这有助于推理,并允许它们进行一定程度的代码生成。而编码模型则明确为后者任务进行训练。
Code Llama是基于 LLaMa 2 的模型。它有相同的尺寸。由于编码模型还需要理解自然语言(NL)指令,因此基于常规 LLM 的模型表现更好。
它有三个版本:
- Code Llama:基础模型
- Code Llama - Instruct:微调版本
- Code Llama - Python:进一步在 Python 代码上训练
Code Llama 详情

训练语料库(500B):
- 85% 来自 GitHub 的源代码
- 8% 与代码相关的 NL 讨论(如 StackOverflow 等)
- 7% NL 批次以保持 NLU 性能
Python 模型使用额外的 100B 个 Python 代码标记进行训练。
训练特点
Code Llama 有两个额外的训练目标:
- 填充:在给定上下文的情况下预测程序的缺失部分
- 用于代码补全、文档生成等
- 仅较小的模型进行训练
- 长输入上下文:以实现库级别的推理
- 将最大上下文长度从 4096 增加到 100,000
- 在专门的长上下文微调阶段进行训练
指令微调通过自我指令完成:
- 生成单元测试和代码
- 添加通过测试的第一个代码片段
结果
](/AI/NLP/NLP-Zoo/code_llama_results.png)
指令:LLaMa 2 + 自我指令。生成单元测试和代码,并添加通过单元测试的代码。
其他模型
闭源:
- Codex/copilot
- AlphaCode
- phi-1
- GPT-4
开源:
- SantaCoder
- StarCoder
多模态
图像-文本模型
与 GPT-3 相比,GPT-4 的主要创新是其多模态性;特别是其使用图像输入的能力。然而,它并不是第一个具有图像到文本能力的系统。
主要的视觉机器学习目标是图像分类:给定一张图像,系统必须返回描述其内容的标签(集)。这通常通过在数百万标记图像上训练的监督系统来完成。
使用大型语言模型(LLM),可以在大型未标记的文本+图像语料库(网络数据)上预训练具有良好零样本性能的通用模型。以下是两个例子。
CLIP
CLIP 通过将图像和文本编码到相同的嵌入空间来执行图像分类。
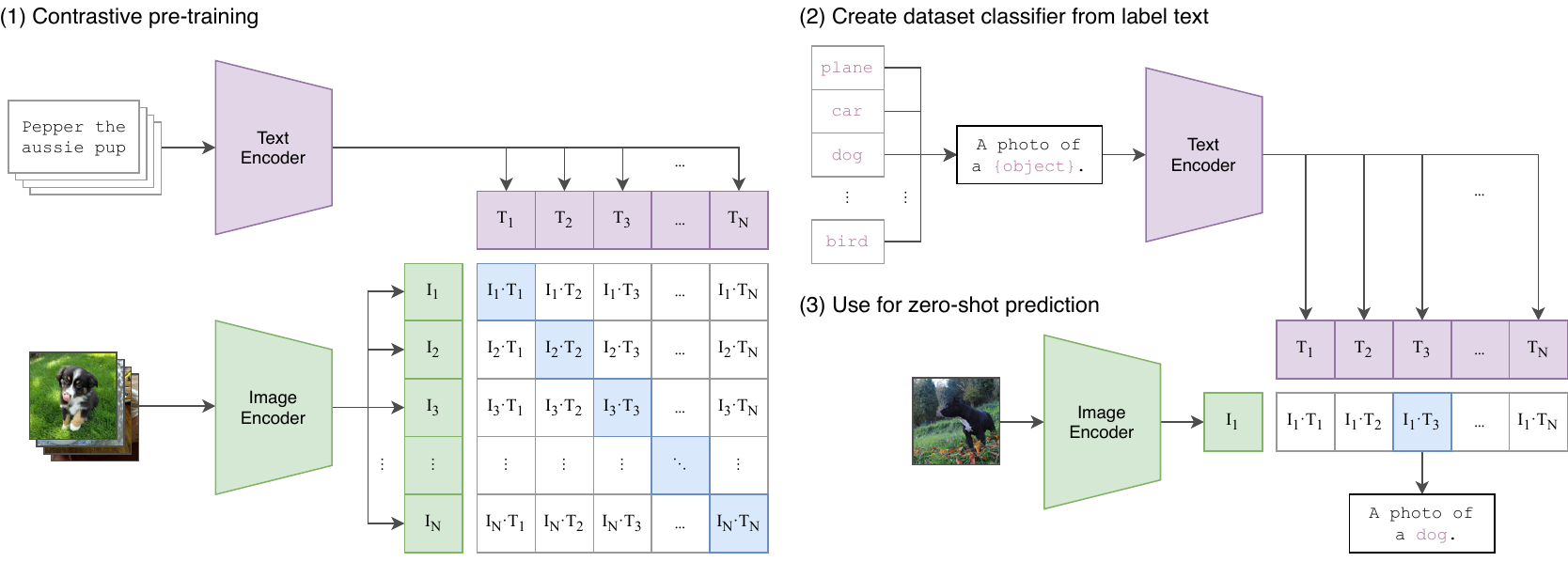
在训练期间,编码器使用对比目标进行训练。在测试时,类标签被编码,并返回与图像最(余弦)相似的标签。
Flamingo
Flamingo 是一个“视觉语言模型”,可以基于混合的文本和视觉输入生成文本。
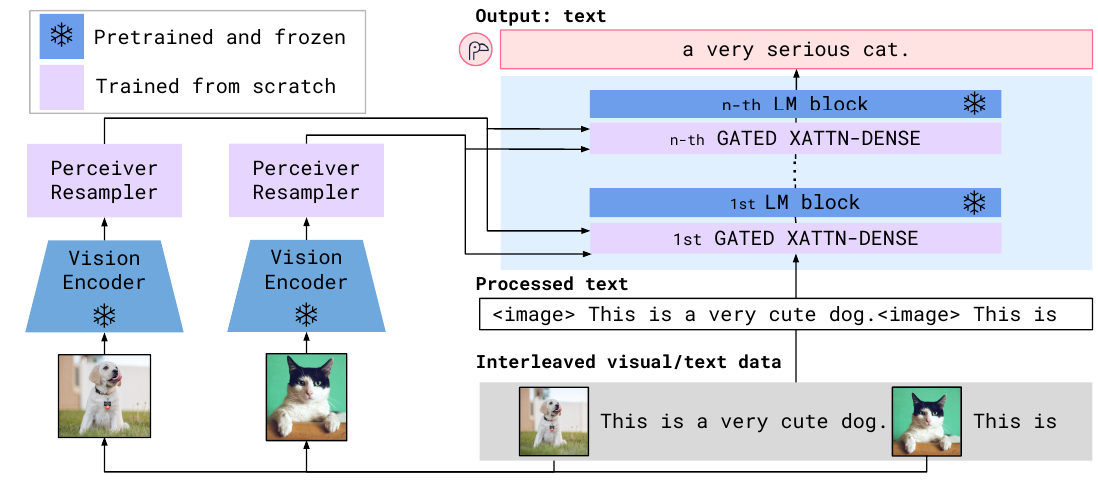
它使用冻结的视觉和文本编码器(例如 CLIP 和 Chinchilla),并且只训练操作其输出的语言模型。
开源模型
上面讨论的许多模型都是闭源的;通常,训练数据也由专有语料库组成。然而,现在有几个开源的 LLM 可在 Hugging Face Hub 上使用:
- BLOOM 是完全开源的,数据和模型都是如此。然而,它的开发已经完成,不再进一步更新
- LLaMa 是在开放数据上训练的,LLaMa 2 及以上版本可以免费使用。Llama 3.x 提供从 1B 到 405B 的模型
- Mistral 是另一个替代方案,提供指令微调和 MoE 模型供下载
LAION
LAION(Large-scale Artificial Intelligence Open Network 大规模人工智能开放网络)旨在提供 100% 免费和开放的 LLM 管道,包括数据集、工具和模型。
一些精选项目:
- Openclip:CLIP 的开源重新实现
- LAION5B:一个包含近 60 亿图像-文本对的语料库
- OpenAssistant:正在开发的开源对话 AI。你也可以通过以下方式提供帮助:
- 添加新对话
- 标记现有对话
- 等等