NLP-VisionActionModels
视觉-语言-行动模型
Introduction
一个重要的方向是控制具身AI代理(机器人),它们应该根据口头指令和来自环境的视觉输入采取行动。这类任务包括:
- 视觉-语言-导航:根据人类的口头指令在真实的3D环境中导航
- 移动物体,即将物体从一个位置转移到另一个位置
- 操作物体,例如打开和关闭抽屉,敲击物体,将它们竖立等
方法和挑战
- 目前,主要的架构方法是使用编码器-解码器架构将视觉观察和语言输入映射到适当的机器人动作
- 架构的骨干通常是一个transformer(编码器、解码器或两者)
挑战包括:
- 利用预训练组件
- 收集足够大的指令机器人行为数据集
- 泛化:创建在不同任务中表现良好的模型,包括在未见过的环境中执行未见过的任务
- 减少硬件需求
使用情景transformer扩展的视觉语言导航
视觉语言导航任务
视觉语言导航任务是让一个人工代理
在环境中导航并到达由自然语言指令指定的目标。
情景transformer模型的具体设置由ALFRED基准数据集提供,其中指令指定了“日常任务”,特别是在室内环境中移动物体。
ALFRED数据集
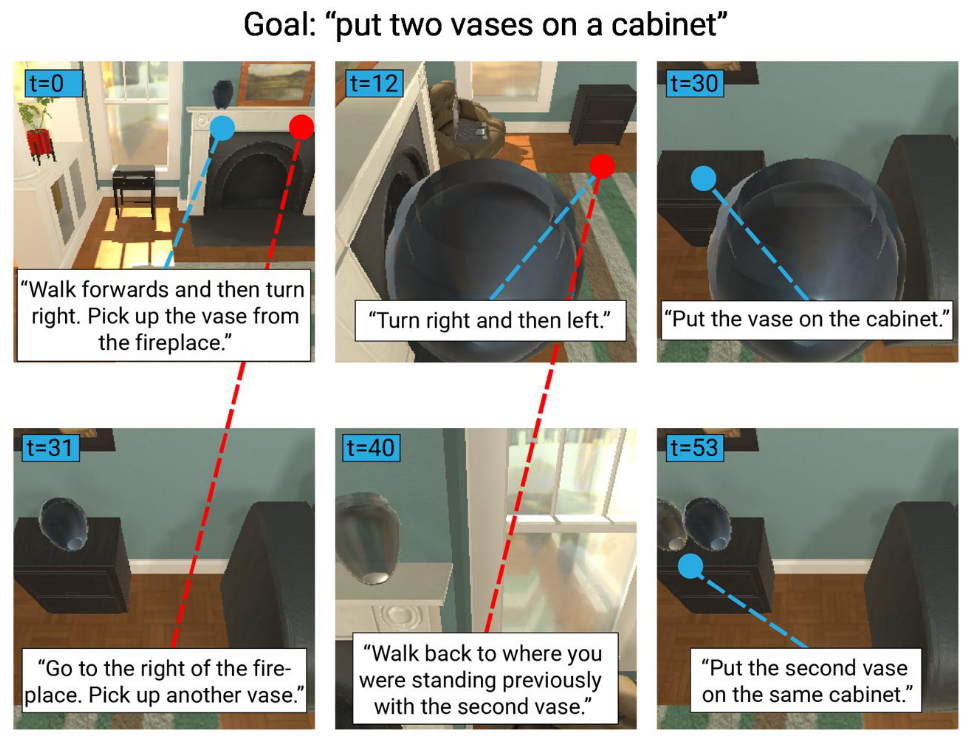
两种类型的自然语言指令:
- 一个单一的“总体”目标
- 几个子目标指令,导致最终目标的实现
数据集由“专家演示”组成,展示了如何在给定环境中通过执行适当的动作来实现描述的目标和子目标
具体来说,ALFRED中的单个演示数据点包括:
- 简短的总体目标描述
- 自我中心的视觉观察时间序列,以及在每个时间步执行的动作和相应的交互掩码(如果动作有目标物体)
- 子目标指令序列,与观察/动作时间序列时间对齐
评估指标
- 任务成功率:如果在动作序列结束时,对象位置和状态变化正确地对应于任务目标条件,则为1,否则为0。
- 目标条件成功率:在一个回合结束时完成的目标条件与完成任务所需的目标条件的比率。
示例:“将一个热的土豆片放在柜台上”
目标条件:
- 土豆必须被切片
- 土豆必须被加热
- 土豆片应放在柜台上
- 加热后的土豆片(2)必须放在柜台上
路径加权版本
对于上述两种评分(任务和目标条件成功率),都有路径加权版本,将基本评分乘以实际执行的动作数($\hat L$)与演示中的动作数($L^*$)的比率:
评分 $s$ 的路径加权版本
$$
p_s = s \cdot \frac{L^}{\max(L^, \hat L)}
$$
情景transformer
动机
- 过去的VLN模型基于递归架构(ALFRED基准模型也是如此)
- 递归网络不能很好地捕捉长期依赖关系,因为历史(先前的观察和动作)被编码在隐藏状态中
- 相比之下,transformer可以访问整个回合的整个历史
更正式的对比 [$\hat a_i$ 是预测动作,$x_{1:L}$ 是指令,$v_i$ 和 $h_i$ 是视觉观察和历史表示]:
架构
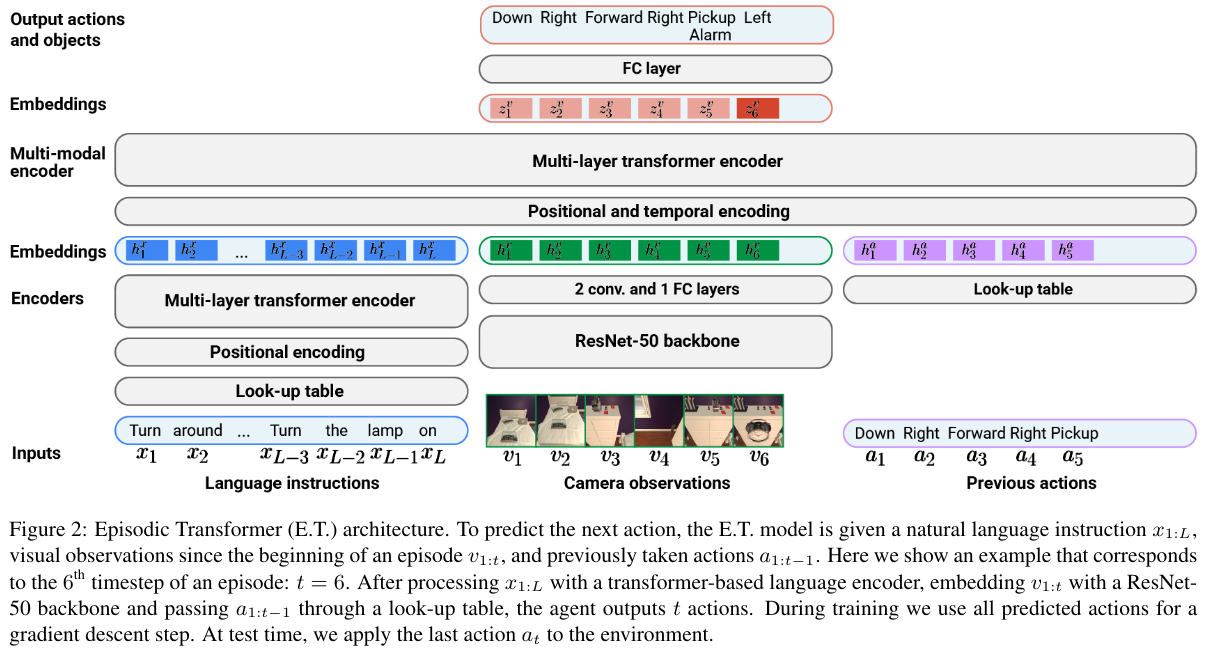
三个历史组件的独立初始编码器:
- 语言指令:一个transformer编码器嵌入文本标记
- 相机观察:一个 ResNet-50 - 2 个卷积和 1 个全连接层独立嵌入所有观察
- 先前的动作 通过一个学习的查找表简单地嵌入
一个多模态transformer编码器融合单模态嵌入
- 文本标记、视觉观察和先前动作的顺序由位置和时间嵌入表示
- 使用“因果注意”防止视觉和动作嵌入关注后续时间步
- 输出层是一个全连接层,预测下一个动作 $\hat a_t$
- 使用基于预测目标对象类别的预训练实例分割模型预测目标对象的位掩码
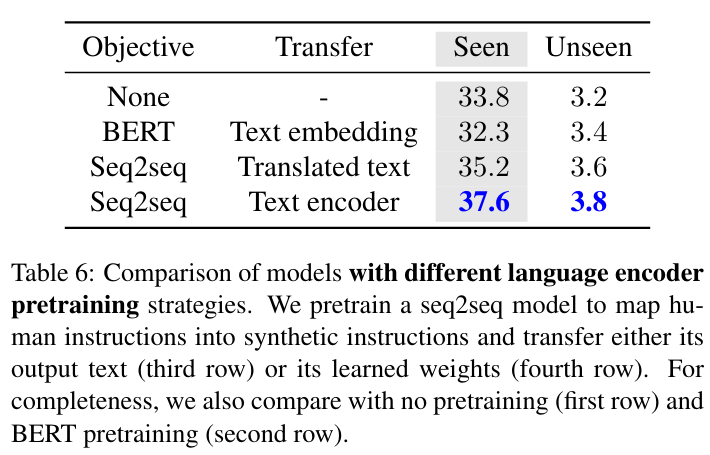
指令编码器预训练
编码器在将自然语言指令转换为合成的、受控的“翻译”(由专家路径规划器参数生成)的编码-解码任务上进行预训练:
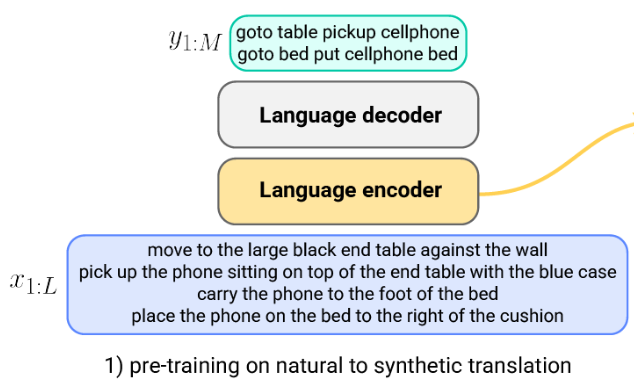
使用合成指令的数据增强
除了预训练语言编码器外,合成指令还用于生成额外的训练数据点:

训练
预训练
- 如我们所见,语言编码器在合成翻译任务上进行预训练
- 视觉编码器和掩码生成器都在训练数据集的帧和相应的类别分割掩码上进行预训练
训练
整个模型的训练使用教师强制:
- 对于专家演示输入 $(x_{1:L}, v_{1:T}, a_{1:T})$,所有 $\hat{a}_{1:T}$ 动作一次性预测
- 要最小化的损失是 $a_{1:t}$ 和 $\hat{a}_{1:T}$ 之间的交叉熵损失
结果
- 结果优于原始的 ALFRED LSTM 基线(在已见任务上的任务成功率为 33.8% 对 23.3%)
- 特别有趣的是,使用预训练的 BERT 进行编码实际上降低了性能
作为通用 VLA 模型的 VLMs:RT-2
起点
- 目标是适应预训练的 VLMs 作为通用指令跟随 VLA 模型
- 具体实现基于 PaLI-X 和 PaLM-E,这两个基于transformer的 VLMs 使用 ViT 变体将图像编码为视觉标记,并使用线性投影将它们映射到 LM 嵌入空间
- 使用的机器人动作特定数据集使用相对简单的指令和任务,预期在其上微调预训练的 VLMs 将导致复杂的指令跟随能力
机器人指令跟随数据集
RT-1 数据集包含 130K 个示例,涉及 13 个人类远程操作机器人在办公室厨房环境中遵循 700 多条不同指令。
任务/技能的分布如下:

“演示是在操作员和机器人之间有直接视线的情况下,使用 2 个虚拟现实遥控器收集的。”
收集的动作数据包含:
- 3 个用于底座移动的连续变量:$x$,$y$,偏航
- 7 个用于手臂移动的连续变量:$x$,$y$,$z$,滚转,俯仰,偏航,以及夹爪的开合
- 一个用于在三种模式之间切换的离散变量:控制手臂、底座或终止回合
模型架构
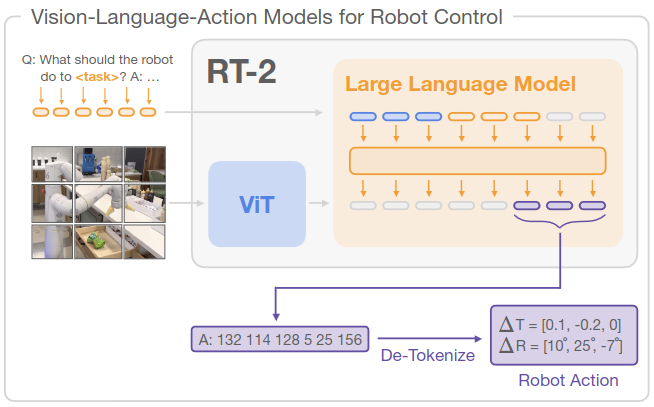
模型架构:PaLM-E
使用的 VLM 之一是 PaLM-E,一个基于预训练 PaLM 语言模型的 12B 参数 VLM,它是一个transformer解码器类型的 LM。
图像使用 ViT 或 Object Scene Representation Transformer (OSRT) 进行编码。表示为 LLM 嵌入空间中的向量序列的多个图像可以与文本标记嵌入交错形成多模态句子作为输入,例如:
Q: What happened between <img 1> and <img 2>?
其中 <img 1> 和 <img 2> 是表示图像的向量序列。
模型架构:PaLI-X
另一个使用的 VLM 是 PaLI-X,它
- 使用一个非常大的(22B 参数)ViT 作为视觉组件,预训练于 OCR 中心的分类任务
- 一个 32B transformer编码器-解码器作为架构骨干
- 其视觉输入可以是多个图像(或视频帧),其表示与文本嵌入连接(而不是交错)
其较小的变体 PaLI-3B 也进行了实验,具有 2B ViT 和 3B 骨干。
VLM 预训练
视觉编码器单独在图像任务上进行预训练,例如 PaLI 的 OCR 分类任务
语言骨干使用标准的 LLM 预训练进行下一个标记预测(在 PaLI 的情况下还包括各种去噪任务)
VLM 训练本身是在大量视觉语言数据集上进行的,包括
- WebLI 数据集,其中包含 100 亿对图像-文本对(来自替代文本字段、OCR 等)
- 视觉问答数据集
机器人动作微调
适应后的 VLM 需要输出机器人动作,因此需要将可能的动作映射到标记序列。为此,
- 使用 256 个箱对连续动作值进行离散化
- 所有可能的变量值都映射到 VLM 的词汇表条目(对于 PaLI-X,前 1000 个整数有自己的条目并被使用,对于 PaLM-E,覆盖了 256 个最不常见的条目)
- 动作向量映射到相应的值-标记序列,用空格分隔
例如,形式为
$\langle$ terminate $\Delta pos_x$, $\Delta pos_y$, $\Delta pos_z$, $\Delta rot_x$, $\Delta rot_y$, $\Delta rot_z$, gripper_extension $\rangle$
的动作向量可以使用 PaLI-X 编码映射到字符串
“1 128 91 241 5 101 127”
关键发现:与其在机器人数据上天真地微调模型,不如在原始 VL 数据和机器人数据上共同微调,因为这会导致更具普遍性的策略,因为模型同时暴露于抽象的视觉概念和低级别的机器人动作。
- 在共同微调期间,机器人数据集示例的采样权重在小批量中逐渐增加
- 训练目标是标准的下一个标记预测目标,这对应于机器人学中的行为克隆(一种模仿学习)
结果
- 对于机器人动作提示,采样仅限于有效的机器人动作标记,以避免生成不可执行的输出
评估重点是:
- 在已见任务上的表现,以及对新对象、背景和环境的泛化
- 新兴能力的可观察性
- 模型大小和架构对性能的影响
- 链式思维推理的可观察性
未见任务
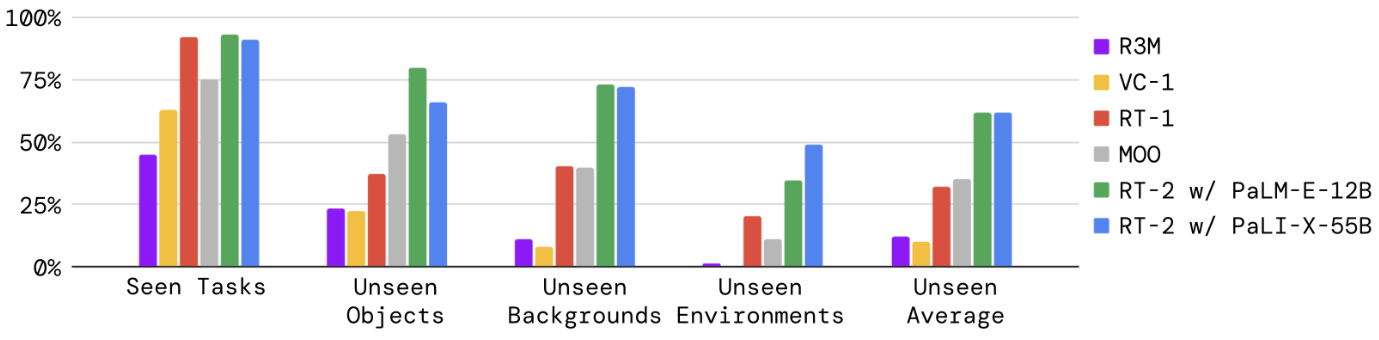
基于 VLM 的 RT-2 比没有 VLM 预训练的模型泛化得更好:
新兴能力
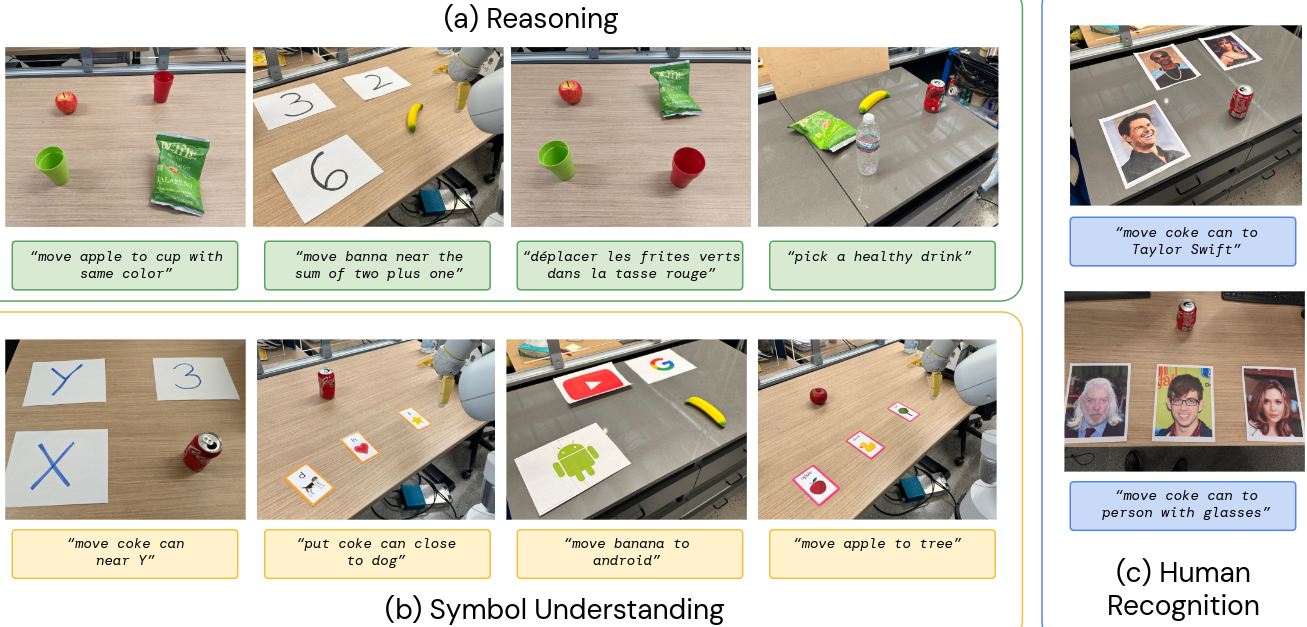
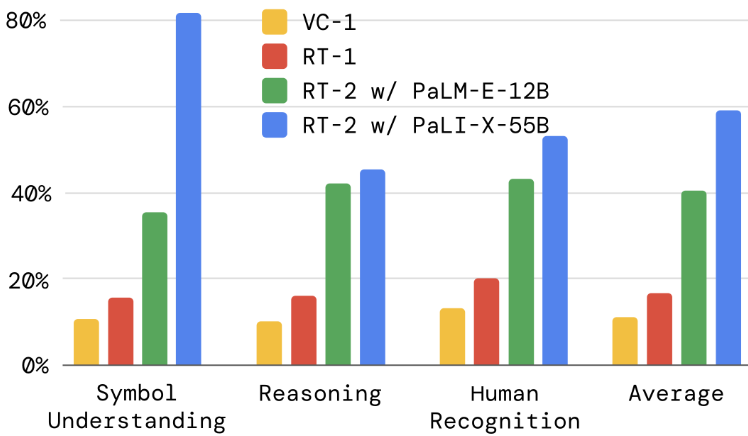
新兴能力分为三类:
- 推理:将 VLM 推理应用于控制任务
- 符号理解:VLM 转移语义知识,这些知识不在任何机器人数据中
- 人类识别:以人为中心的理解和识别
链式思维推理
RT-2 模型在额外的数据上进行了微调,包括指令后的“计划”部分,例如,
Instruction: I’m hungry. Plan: pick rxbar chocolate. Action: 1 128 124 136 121 158 111 255.
根据“定性观察”,这种微调使模型能够遵循更复杂的指令。

NLP-VisionActionModels