NLP-Tooling
工具
增强语言模型
Augmenting Language Models
动机
从2020年代初期开始,语言模型可以通过以下特性来描述:
- Few-shot learners
- 能够推理逻辑问题
- 容易产生幻觉 hallucinations(由于活跃的知识空白)
- 能够逐步遵循指令
知识可以以少样本的方式注入,这可以解释为克服幻觉。通过逐步处理,增强模型可以使用低复杂度的知识源来回答复杂问题。
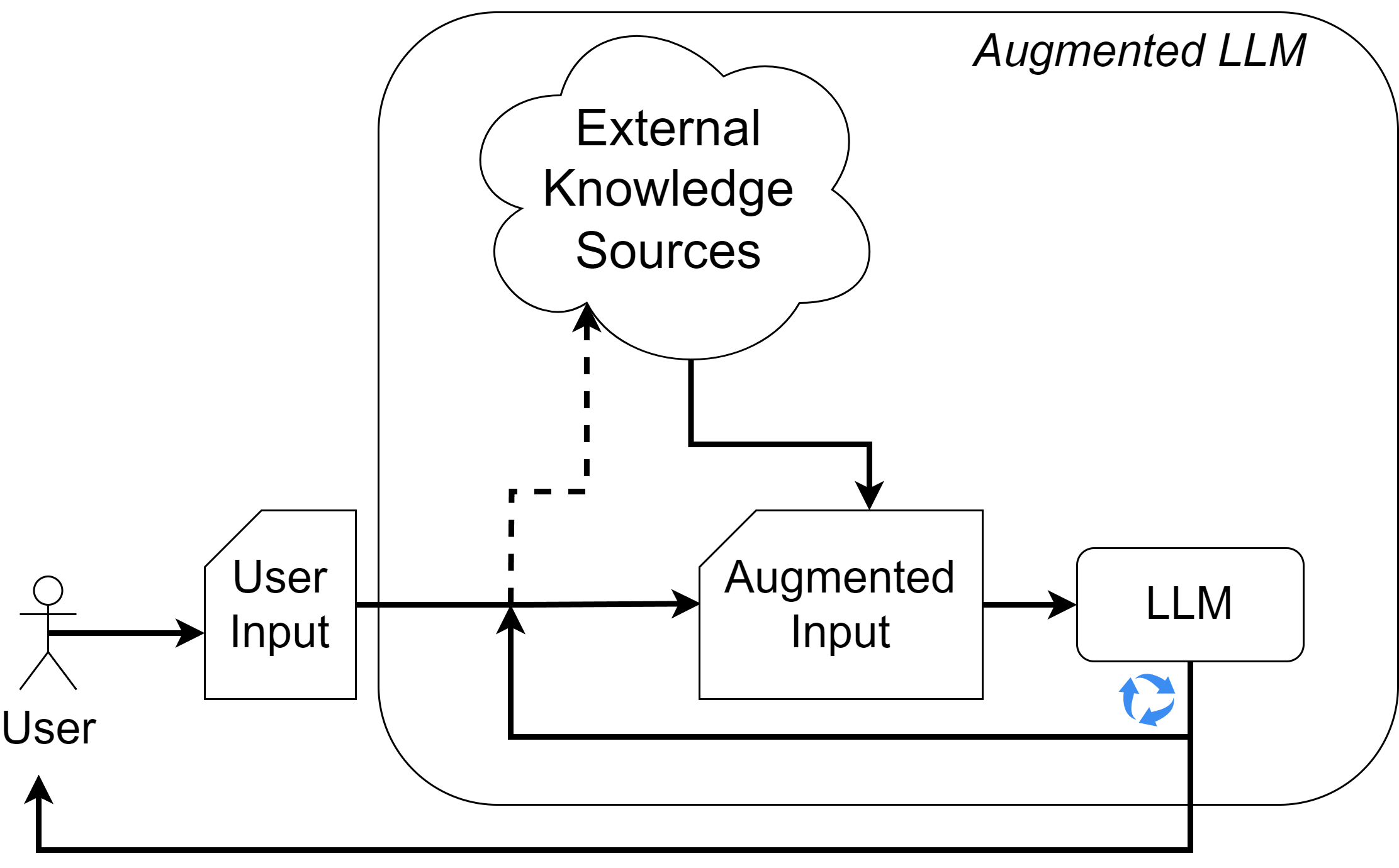
与提示的连接
有两种方法可以将外部信息注入类似Transformer的语言模型:
- 嵌入空间中的向量序列(cross-attn,prefix等)
- 将文本信息注入提示(特殊标记,格式等)
重要提示!在考虑增强的同时,应考虑使用适当的提示技术。基于Transformer的模型的上下文窗口具有固定长度,这是一个限制!
检索
最简单的解决方案:检索增强生成(RAG)。
获取一个外部知识库并查询它。然后,模型可以利用查询结果来回答问题。
示例提示:
1 | 仅使用提供的上下文回答以下问题! |
如何检索信息?
查找相关信息的最常见方法是:
- 基于关键词的搜索(出现次数,正则表达式等)
- 基于向量相似度的搜索(TF-IDF,LM-embedding等)
- 关系查询
- 基于分类法(Taxonomy)的搜索(词典,维基,WordNet)
- 直接访问(链接,文档)
搜索方法
基于向量相似度的搜索方法
假设我们有某些文档的特征向量 ($e^i$),其中 $i\in I$,且 $||e^i||_2^2 = 1$。
检索过程应返回与嵌入的用户查询 $e^q$ 最接近的文档。
这是通过经典的最近邻搜索实现的。假设 $e \in \mathcal{R}^d$ 且 $|I| = N$,则检索的复杂度为 $O(Nd)$。
这随着嵌入大小(质量)和文档数量的增加而变得困难。搜索 $k$ 个最近邻也是如此。
近似最近邻搜索
Approximate nearest neighbor search
预构建的索引可以减少推理时间,但内存和构建时间仍然是一个限制。存储和索引构建需要近似。
可能的解决方案:
- 哈希
- 量化
- 树结构
- 基于图的
上述原则在实践中经过改进并经常结合使用。
哈希
与返回精确结果不同,哈希函数构建了分箱。使用LSH(Locality-Sensitive Hashing)函数族时,两个向量距离增加时碰撞概率单调递减。
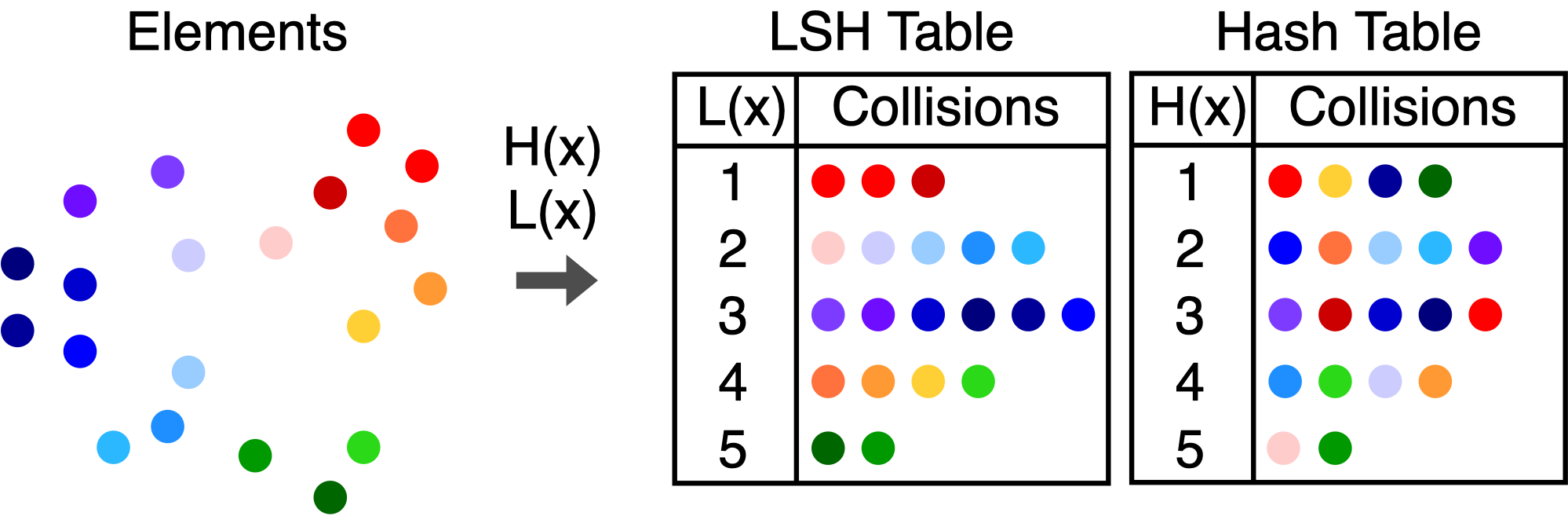
通过分箱减少复杂度。在找到最近的分箱后可以进行细粒度搜索。
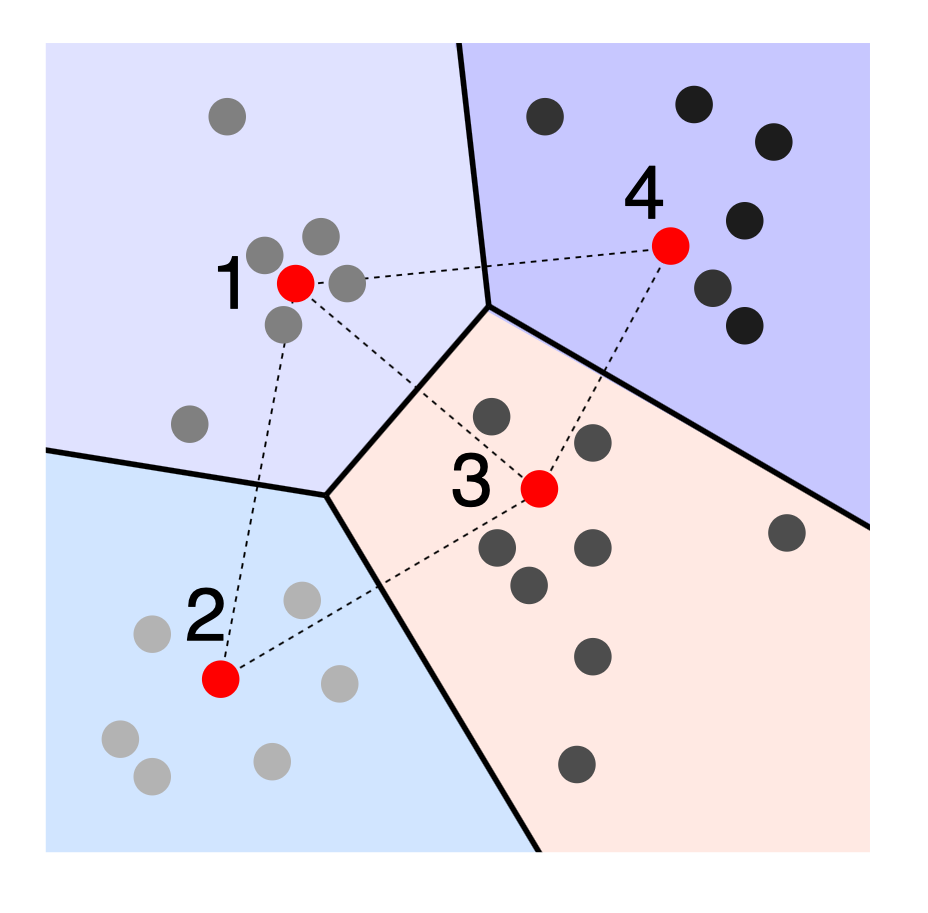
基于树的解决方案
在树结构中,分支因子 $b$ 将搜索复杂度减少到 $\log_b(N)$。
对于二叉 KD 树 $b=2$,构建此类树的简单解决方案是在最高方差数据维度的中位数处绘制一个垂直超平面。然后每一半使用相同的原则进行拆分。这继续进行,直到每个节点仅包含一个元素。
然后可以结合树和嵌入空间搜索算法来找到最近邻。例如:优先搜索。
优先搜索
首先选择包含查询的节点(或单元),然后访问由查询与查询单元中的嵌入向量之间的距离初始化的最大嵌入空间距离限制的最近邻树节点。
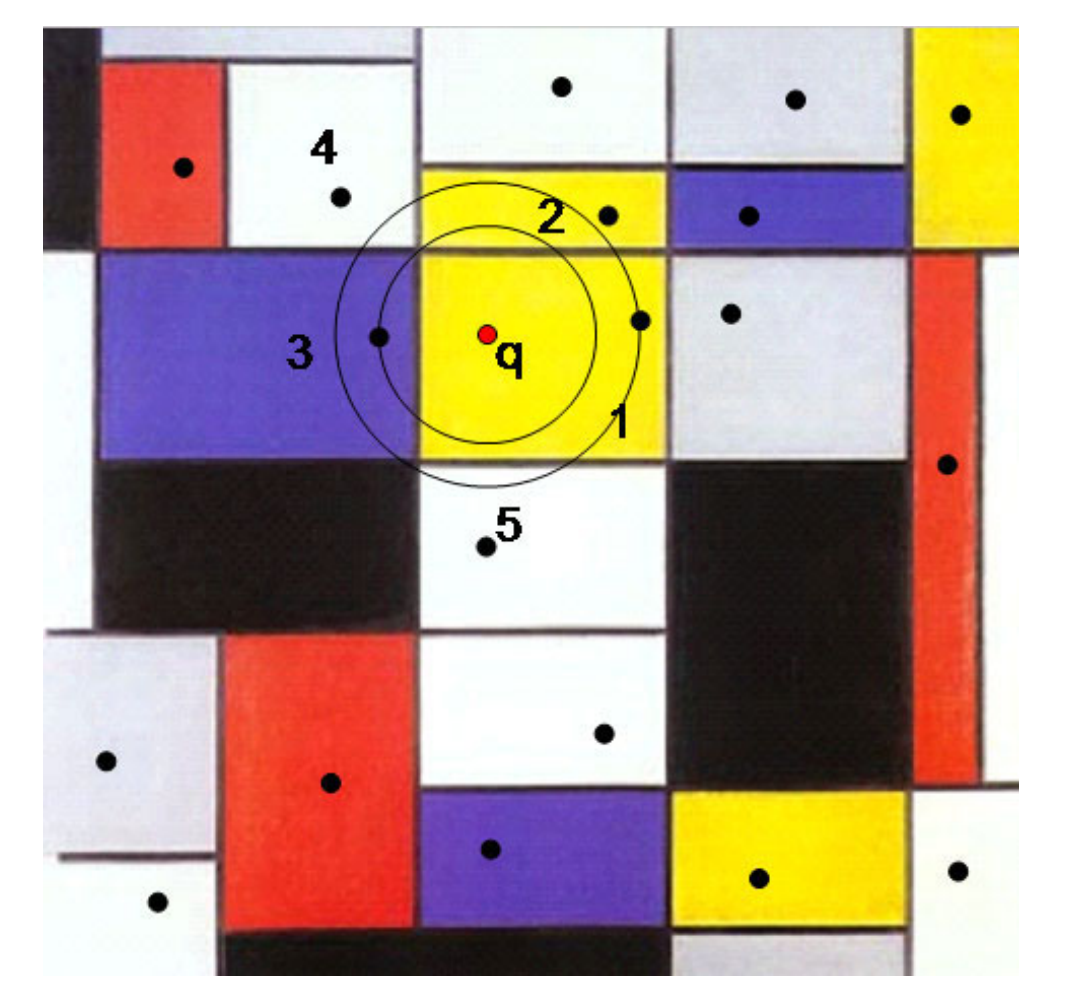
量化
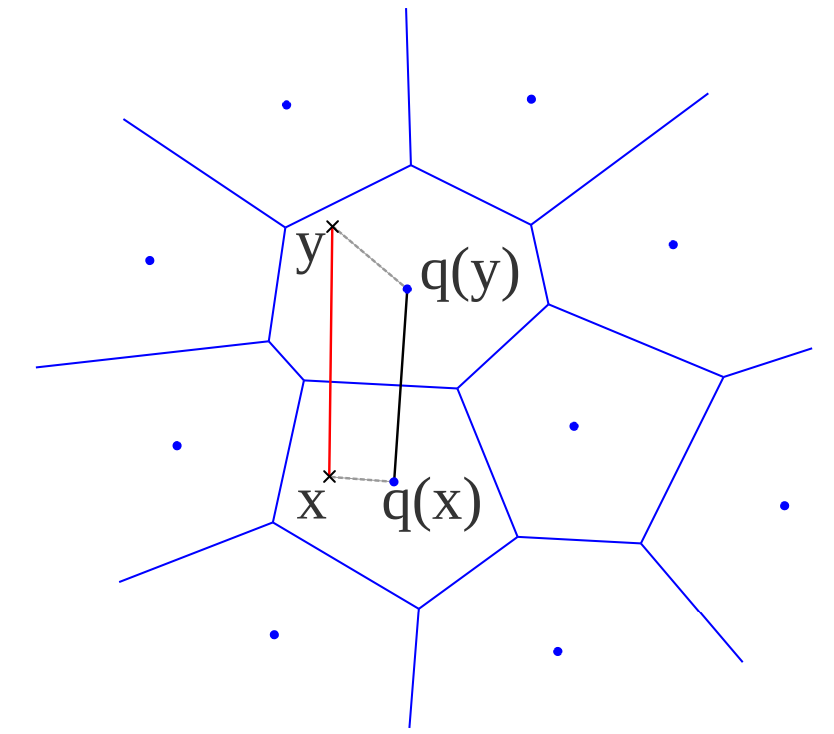
给定由质心 $\mathcal{C} = {c_i | i\in I}$ 定义的码本,其中 $I = {0, 1, … m-1}$ 是有限的。
我们将每个实向量映射到最近的质心 $q(\cdot)$。映射到 $c_i$ 的实向量集合是其 Voronoi 单元,用 $V_i$ 表示。
这意味着 $q(x) = \text{arg}\min\limits_{c_i \in C}d(x, c_i)$,其中 $d(\cdot)$ 是距离函数。
$c_i = E_x[x|i] = \int_{V_i}p(x)\cdot x dx$,应定义为 Voronoi 单元的中心。
Product Quantization
简单量化仍然效率低下,因为聚类中心需要使用复杂的算法(如 k-means,复杂度 $O(dm)$)来计算。在简单的 1 位/组件 $128$ 维量化向量的情况下,需要计算和存储 $m = 2^{128}$ 个质心。
这太多了!
解决方案:我们应该将向量分解为多个段(类似于 MHA)。
在将向量分成 $L$ 段的情况下,每个段可以通过其特定的量化器进行量化。这意味着 $\mathcal{C} = \mathcal{C}_1 \times \mathcal{C}_2 \times … \times \mathcal{C}_L$ 和 $I = I_1 \times I_2 \times … \times I_L$ 应分解为子量化器和子索引的笛卡尔积。
在这种情况下,复杂度减少到 $O(dm^{\frac{1}{L}})$。
每个段的量化值之间的距离可以计算并存储以供搜索步骤使用。
使用预计算的 $d(c_i, c_j)$ 表,我们可以轻松计算完整向量 $e^i$ 和 $e^q$ 的距离。在欧几里得距离的情况下等于:
$$d(e^i, e^q)=d(q(e^i), q(e^q))=\sqrt{\sum\limits_{l \in L} d(q_l(e^i), q_l(e^q))^2}$$
这导致平均搜索复杂度为 $N$ 次比较加上查找和求和 $L$ 查找表中的相应距离。如果 $N>>L$,则简化为 $O(N + L\ \log L \cdot \log\ \log N )$。
基于图的
图方法构建一个索引,该索引采用适合邻居关系表示的形式。例如 Delaunay 图、相对最近邻图、k 最近邻图、最小生成树等。
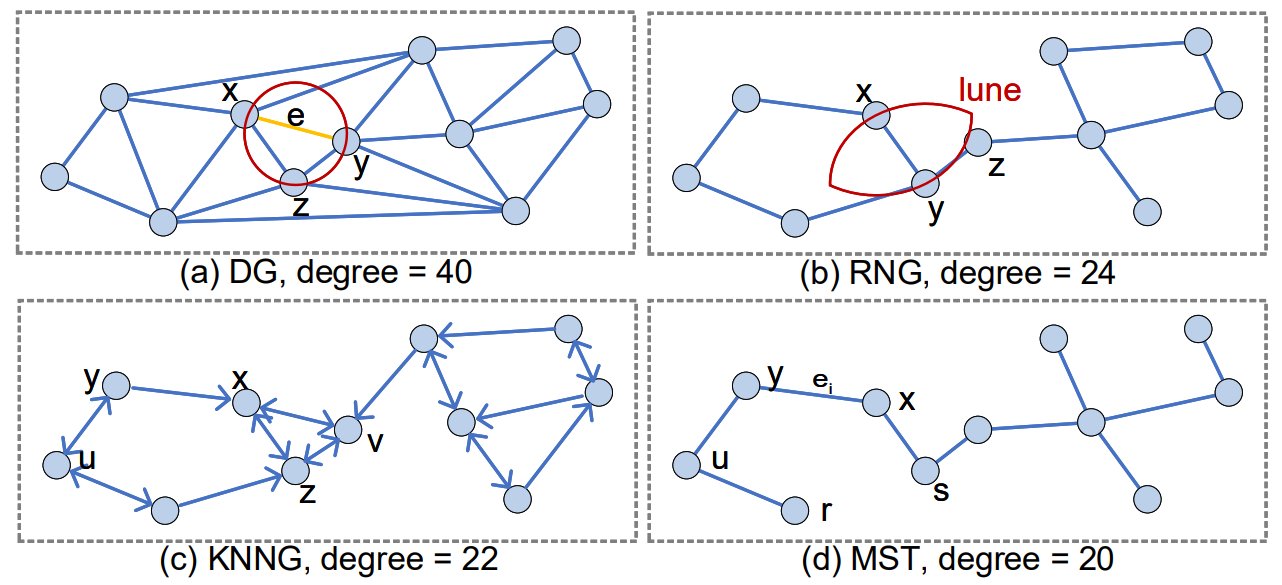
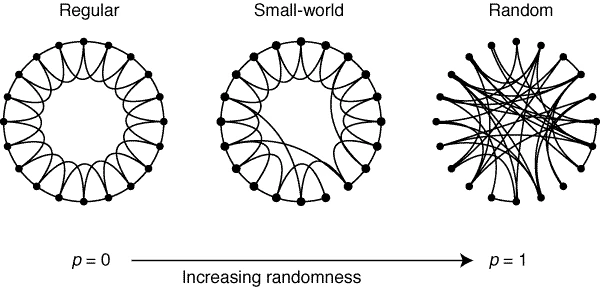
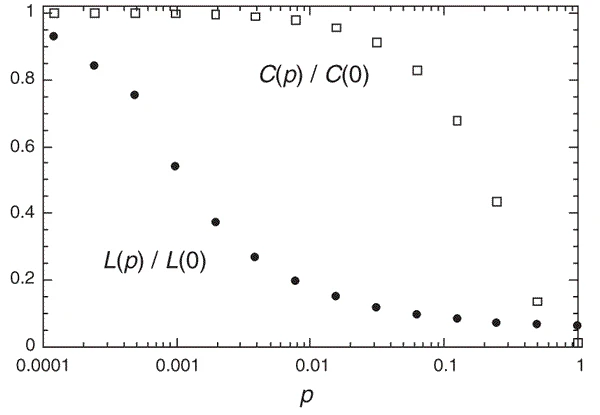
这些图很难构建和存储,因此在构建过程中会进行近似。通常,具有“小世界”特性的图被构建。这些网络具有以下特性,给定一个常规网络的边重连概率 $p$:
- $L(p)$ 两个顶点之间的最短路径平均值应较小
- $C(p)$ 聚类系数(完全连接的三元组(三角形)与图中所有三元组的比率)应较大
Small world
构建图
NSW(navigable small worlds)用于创建可导航的小世界。在这里,顶点被迭代地插入到网络中。连接是通过一个随机性水平选择的,这创建了一个小世界网络,同时确保整个网络是可遍历的。
HNSW(hierarchical NSW)更进一步,通过将节点和链接组织成层次结构。那些具有长链接距离的层应插入到顶层,而较小距离(后插入)的节点放置在较低层。
HNSW 推理
一个贪婪搜索算法从顶层节点之一初始化。然后它在层中寻找局部最小值,并在找到后切换到较低层,直到找到最接近查询的点。该算法的平均复杂度为 $O(\log(N))$。
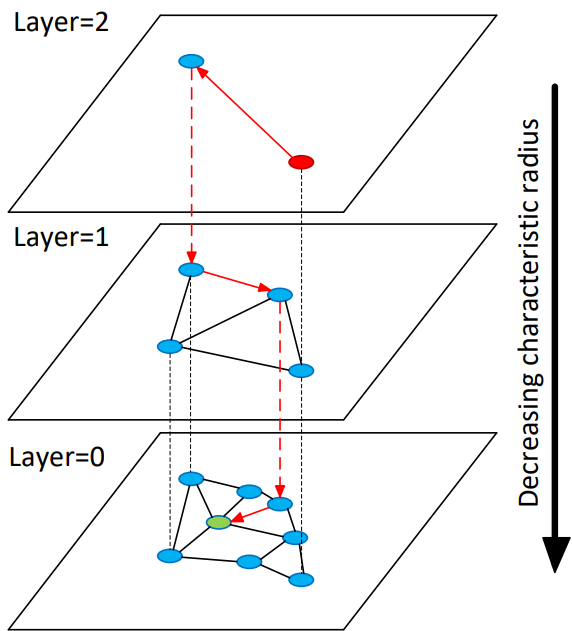
图推理
一般来说,其他基于图的解决方案也遵循类似的原则。它们从一个种子顶点开始,然后通过图遍历,朝着与查询距离较小的方向前进。
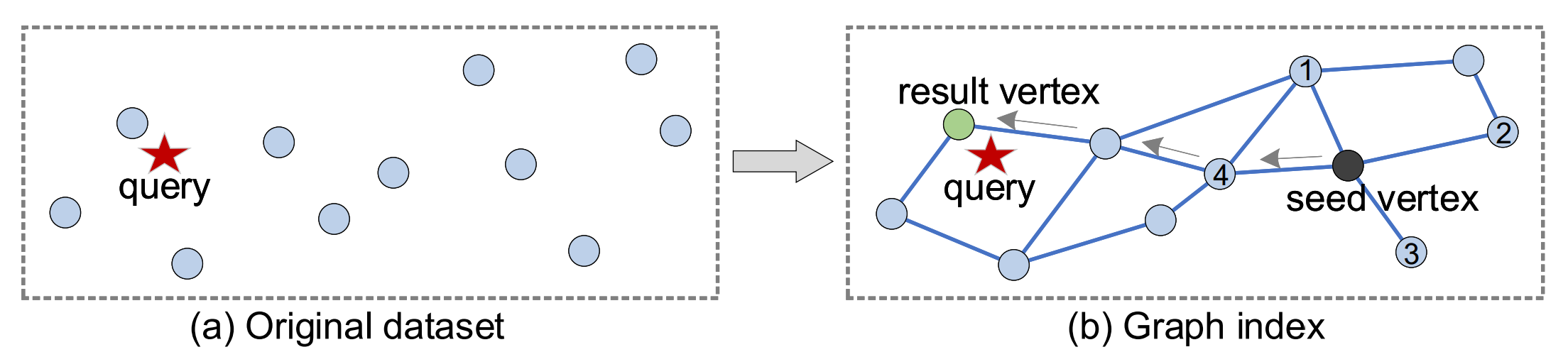
检索增强
Retrieval Augmentation
嵌入模型
语义向量用于检索文档。这些文档通常被拆分成较短的片段。语义向量可以来自 TF-IDF、Word2Vec 嵌入、Masked- 或 Causal-LM 嵌入。也可以使用多模态选项。
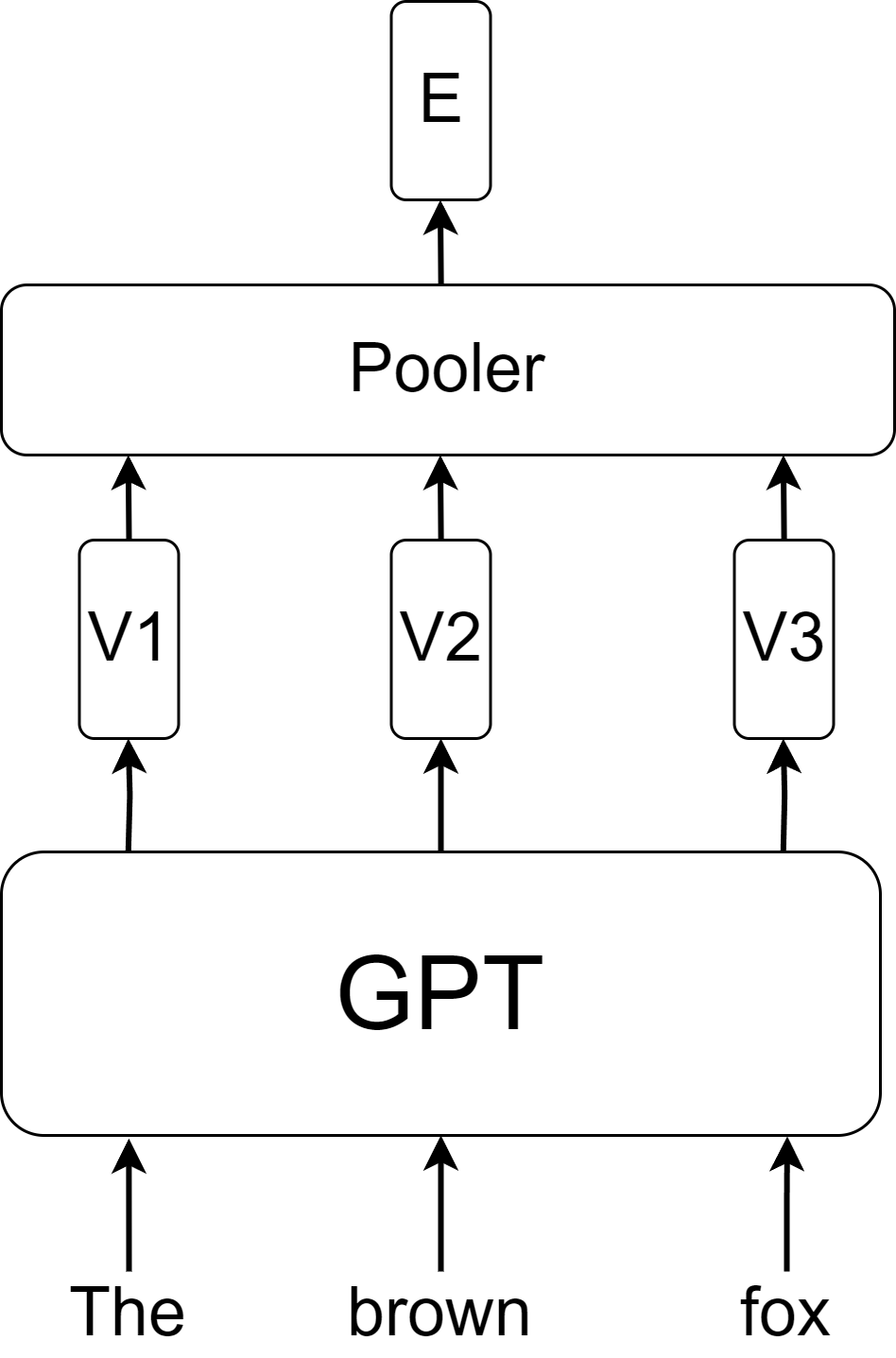
专门的嵌入模型
语言模型的预训练可能不会产生具有所需属性的嵌入空间。
一些额外的目标可以帮助对其进行调整:
- 监督语义相似性 Supervised semantic similarity
- 分类
- 聚类 Clustering
- 监督检索或重新排序
- 问答映射
- 更长的(句子、段落)文本表示
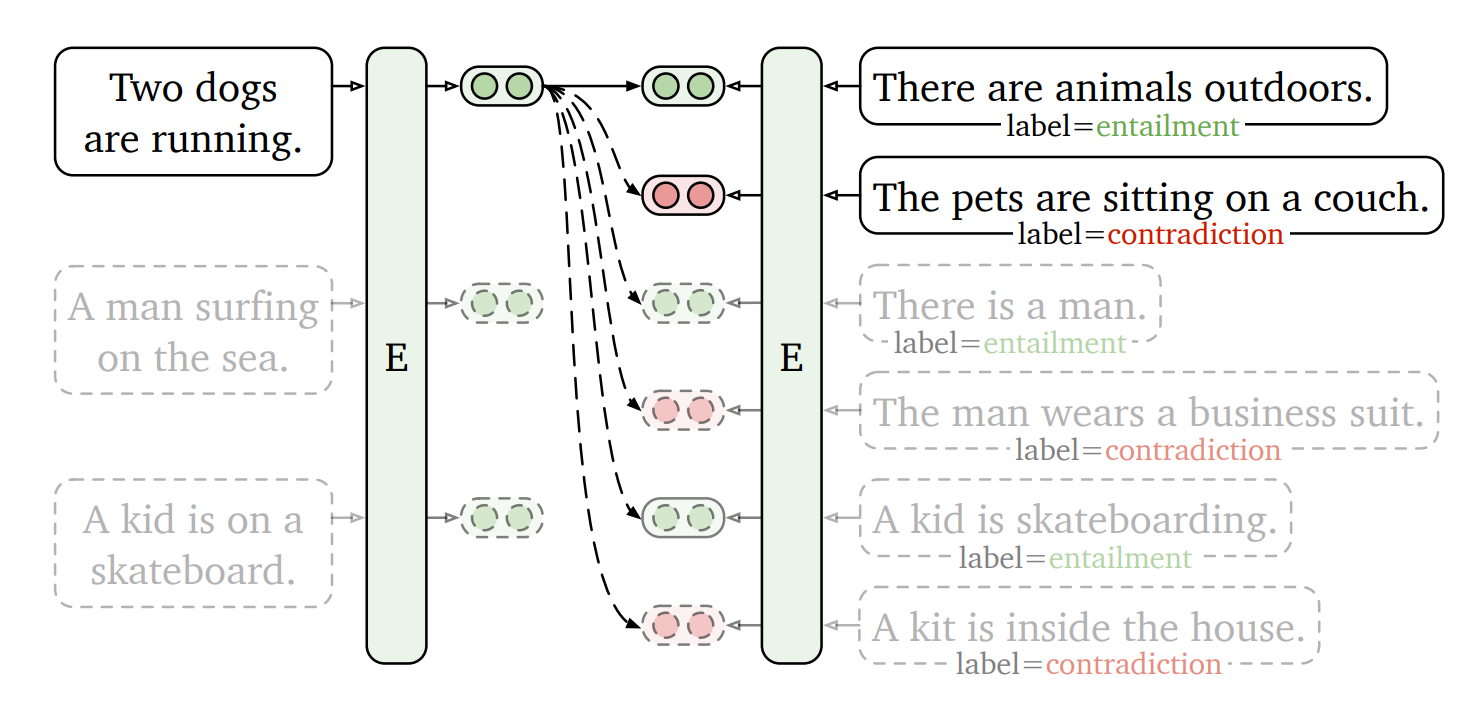
句子嵌入
需要对句子级别进行微调,以正确表示较长文本的语义。
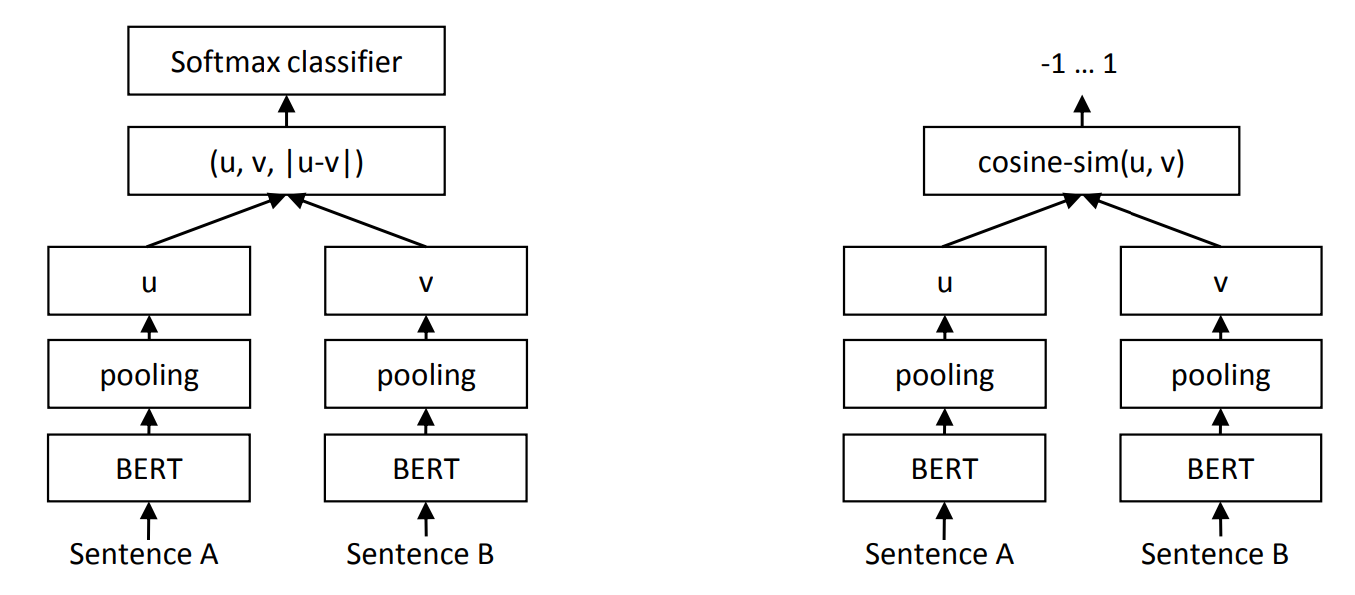
句子级别的监督数据集示例包括:句子相似性数据集、情感分析数据集、自然语言推理数据集(前提和一个蕴涵、矛盾或中性对),等等。
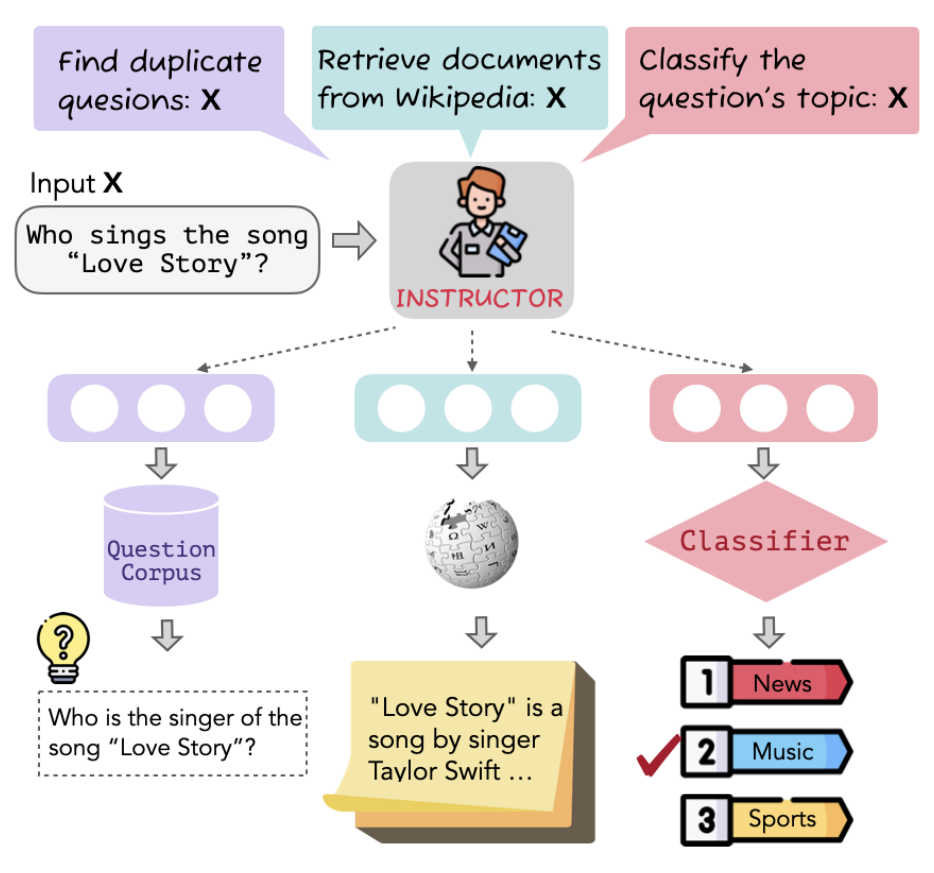
指令嵌入
指令嵌入作为多任务训练嵌入出现,其中执行的任务取决于给模型的自然语言指令。指令训练也提高了领域适应性。
检索增强生成
RAG 通常包括以下步骤:
- 问题形成:将用户查询重新表述为独立查询(考虑历史),关键词列表等
- 检索:使用嵌入和向量存储系统或搜索引擎等检索有用的段落
- 文档聚合:aggregation 将所有文档一起“填充”或“映射”一个转换(例如摘要)
- 答案形成:查询和上下文被输入到生成答案的语言模型中
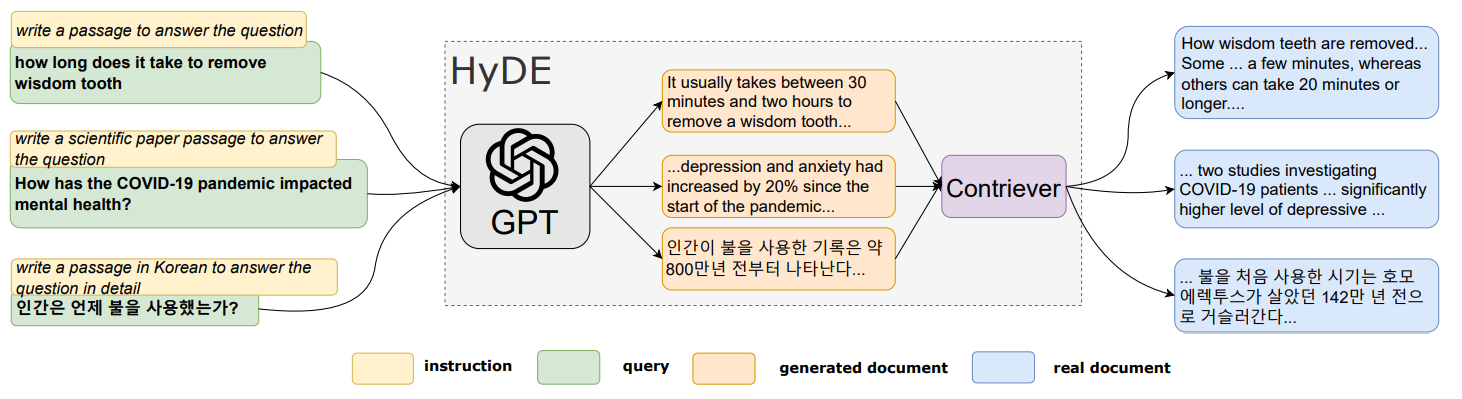
假设文档嵌入
Hypothetical 文档嵌入有助于为基于嵌入向量的检索系统生成更好的查询。HyDE 问题形成步骤被生成步骤取代,该步骤生成问题的“假”示例答案,并将其用作数据库中的查询。
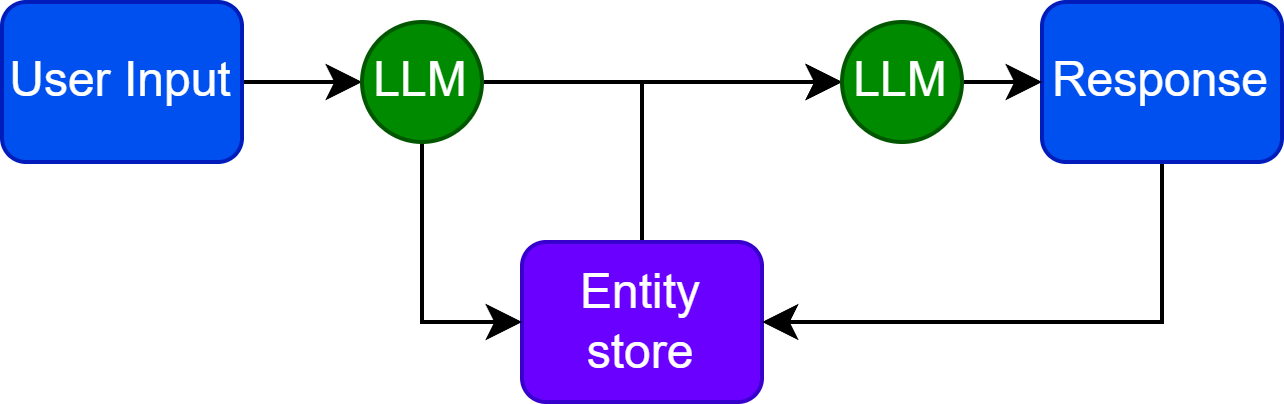
实体记忆
另一个可能的、更复杂的用例是当 LLM 也有能力修改数据库时。在这个数据库中存储了一个实体列表和相关知识。模型被迭代地提示更新这个数据库,然后它可以从数据库存储的实体信息中检索。
RAG 预训练模型
将解码的信息传输到文本实际上效率不高。
检索增强预训练对于模型是可能的,其中预嵌入向量附加到编码输入,或者通过类似交叉注意力的机制提供信息。
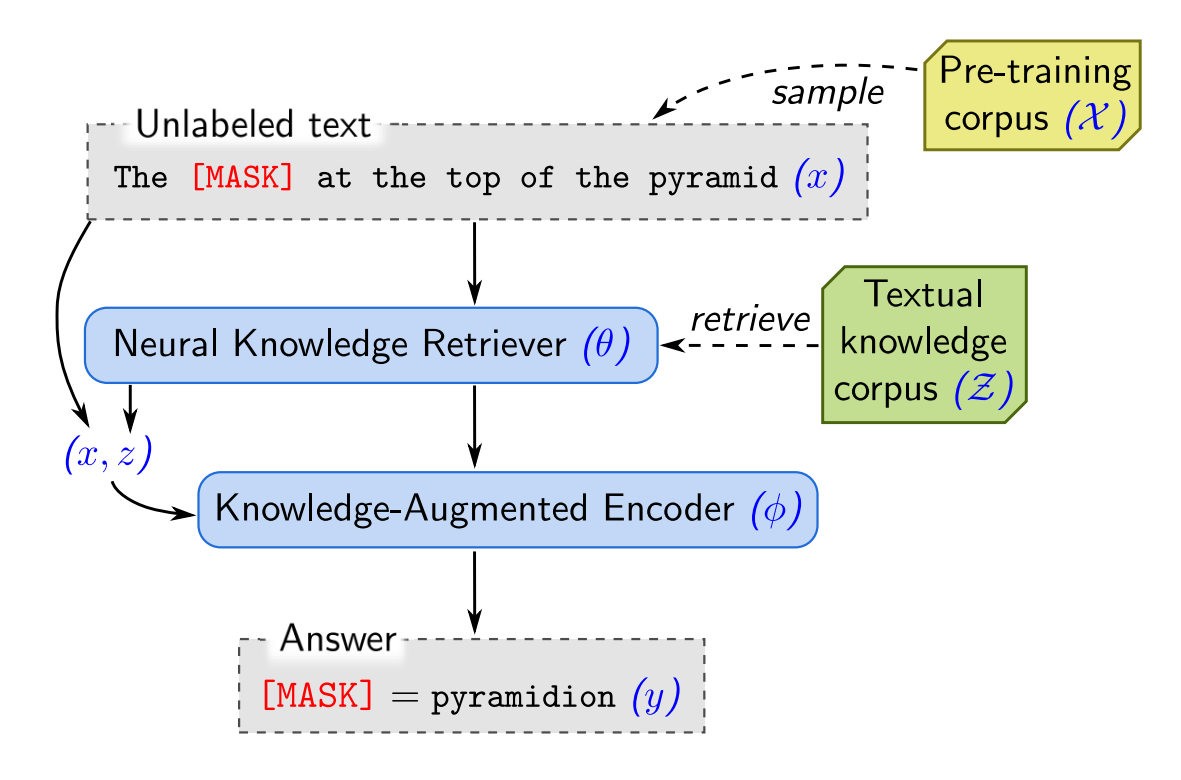
REALM
检索增强语言模型预训练使用由类似 BERT 的嵌入模型组成的神经检索器。这些模型是训练网络的一部分。检索器在 MLM 训练期间将检索到的文档嵌入与查询连接起来。
RETRO
检索增强 Transformer 引入了一种技术,其中相关的上下文信息通过交叉注意力进行处理。
检索是通过冻结的 BERT 嵌入进行的。检索到的块然后基于输入信息使用交叉注意力在编码器中进行修改。
在解码器中,交叉注意力将修改后的检索信息合并到输入中。
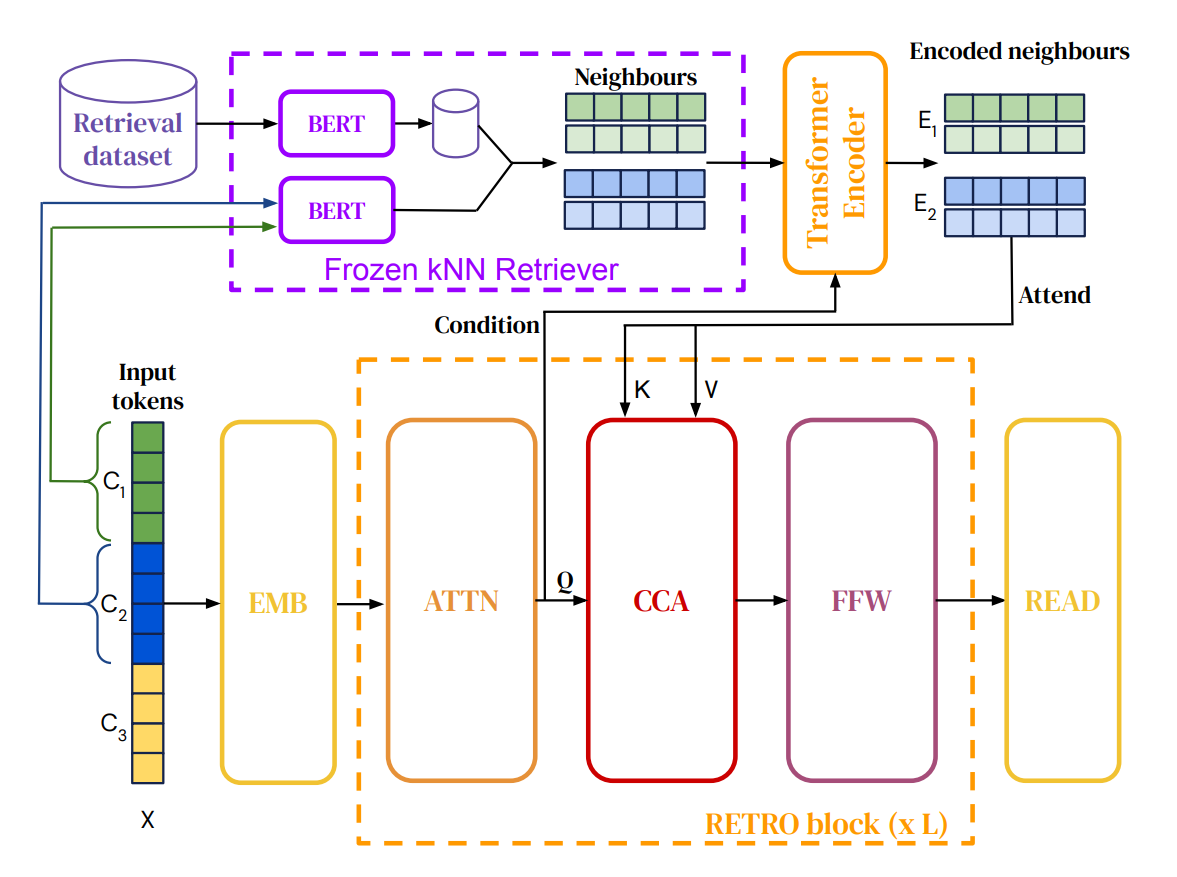
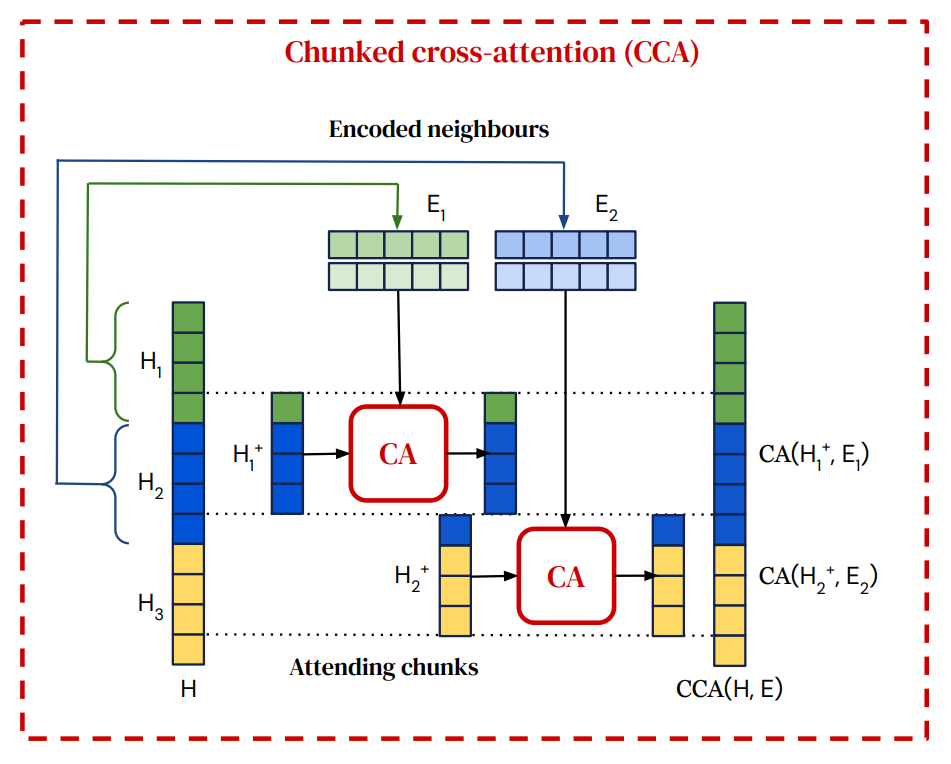
RETRO 块
输入被切分成块,每个块分别检索信息。前面的块(及相关信息)按因果关系处理。
整个模型是可微分的,梯度可以通过网络流动。
在训练期间,检索到的信息是预先计算的。
工具
API 调用
基于文本的 API 可以通过 API 的输入和输出定义轻松调用。大多数 LLM 都经过微调,可以很好地处理 JSON 或 XML 格式。
此类 API 的一些示例包括:
- 搜索引擎
- 网络抓取
- 实时数据流
- 可执行文件,命令(例如:计算器)
- 代码解释器,模拟器
- 其他 LLM 实例
AutoGPT - 自我独白
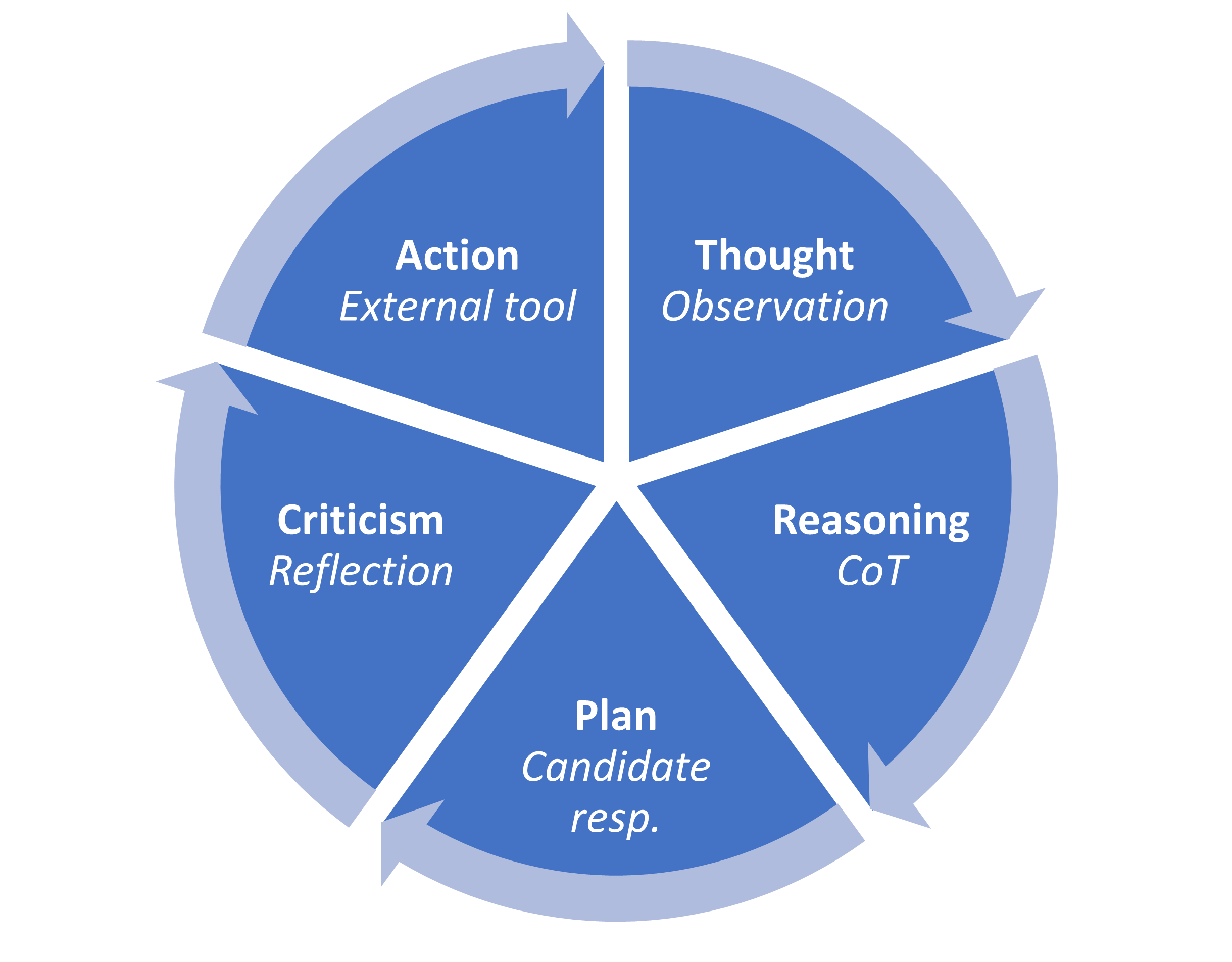
AutoGPT 通过在链式思维和反思类型提示中应用多次生成,能够进行更高阶的规划。
AutoGPT 应用 $4+1$ 步骤的类似 CoT 的过程来控制动作:
- 思考:根据目标解释用户输入。
- 推理:关于如何处理此输入的 CoT。
- 计划:计划要执行的操作。
- 批评:反思行动结果。
- 行动:由 AutoGPT 生成输入的动作。
在计划和行动阶段,可以调用额外的专家 LLM 和外部工具。
AutoGPT 系统通常只提示一组目标,其余由模型自行解决。
示例工作流程(发送电子邮件):
思考:联系 Joe,邮箱 Joe@inf.hu,发送一封礼貌的电子邮件,表明他应该完成 NLP 幻灯片。
推理:目标明确。我需要发送一封电子邮件给 Joe,邮箱 Joe@inf.hu,礼貌地要求他完成 NLP 幻灯片,并表明我是一个 AI 助手。
计划(+批评 Criticism):使用 send_email 动作。
{ “action”: “send_email”, “action_input”: <JSON>}
观察:邮件已发送。
Agent 循环
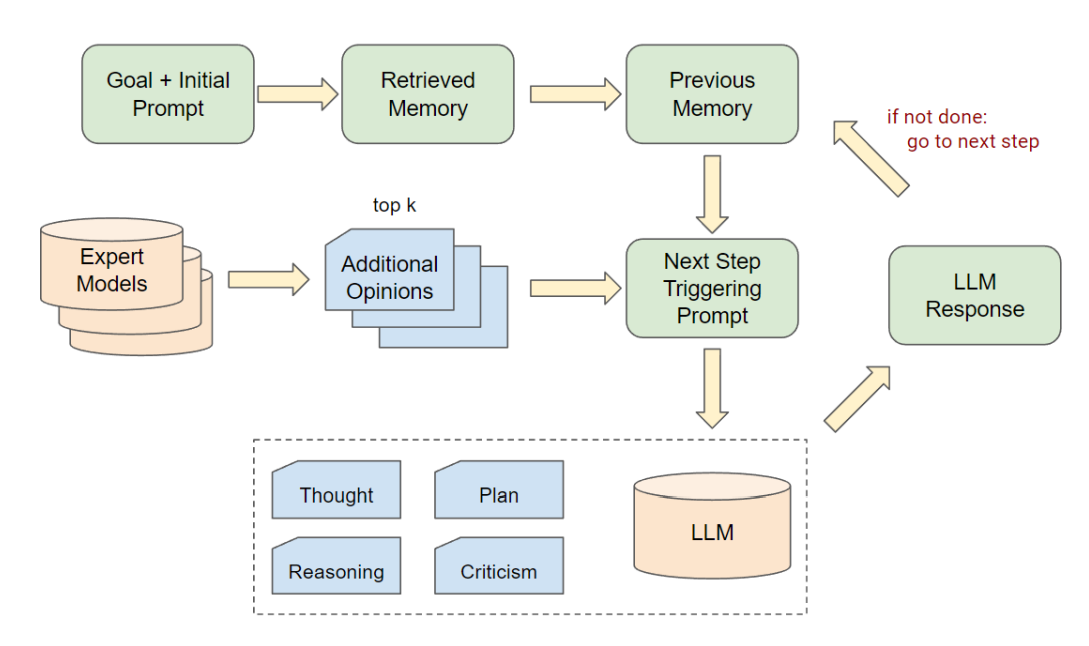
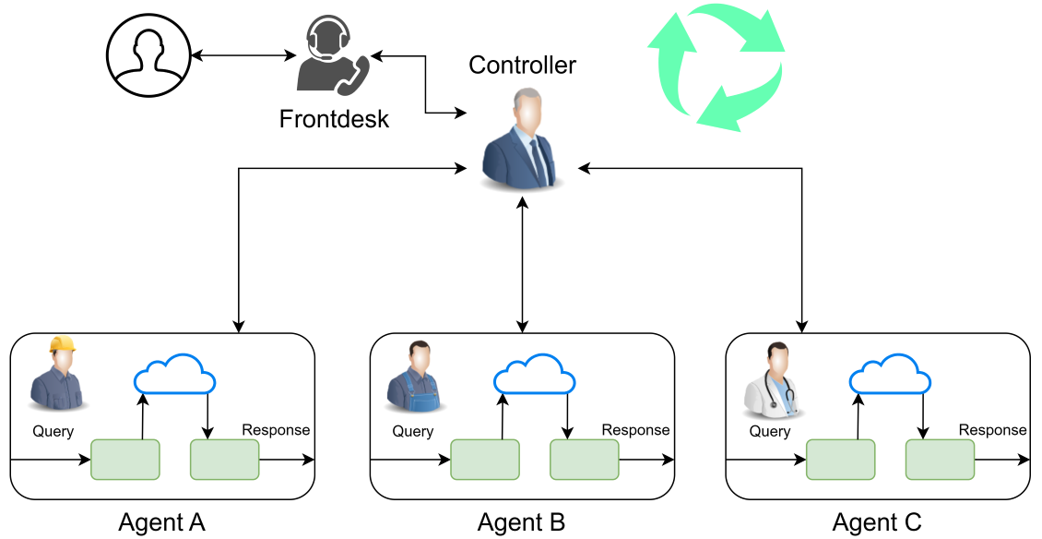
会话专家代理
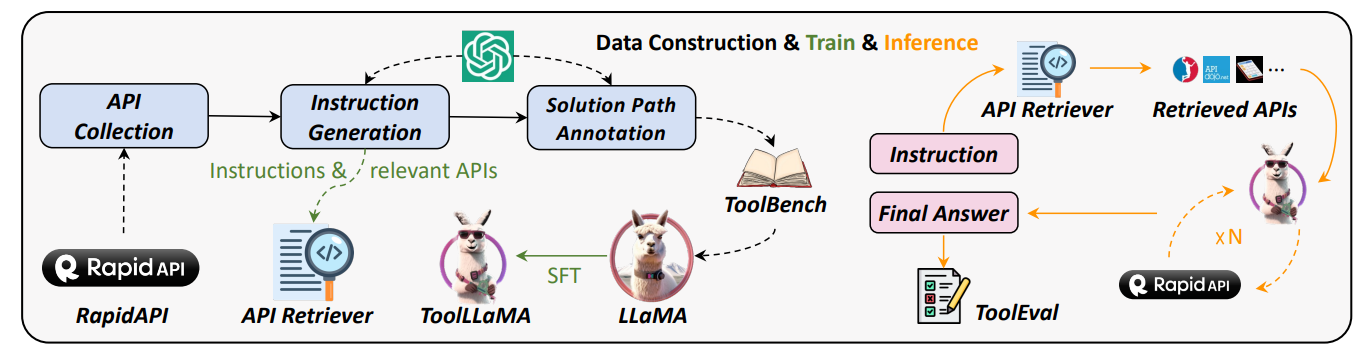
工具微调模型
微调模型以选择工具是困难的。引导可能是一个解决方案,其中使用大量 LLM 调用构建 API 调用图。这些连续调用按成功率排序,并选择通过率最高的几个解决方案纳入数据集。这样的微调可以增强语言模型的工具利用能力。
总结
总结 I
增强语言模型使用外部信息源来增强其能力。这些信息源的一个重要组是矢量化文档数据库。嵌入模型用于通过近似 NN 搜索算法检索相关信息。
其他工具包括 Web API,甚至代码解释器。应用自我独白过程的模型能够通过规划和执行连续的动作来实现目标。
总结 II
在检索增强生成过程中,检索到的文档被连接或总结,然后在第二个 LLM 步骤中输入模型以生成答案。
微调模型以使用检索到的信息或外部工具是可能的,并且可以提高性能。
NLP-Tooling