NLP-STT
语音转文字
语音转文字任务
语音转文字 (STT) 任务,也称为自动语音识别 (ASR):
- 输入是包含语音的声学信号(例如,一个
wav文件) - 输出是口语内容的书面转录,通常没有标点和大写
- 生成的转录不一定分段成句子或包含正确的标点和大写
- 该任务是监督的:模型在转录的语音语料库上进行训练
挑战
挑战源于语音和书写之间的差异,以及上下文依赖性:
- 分段:书写中的单词边界通常不会通过语音中的静音来指示,反之亦然,语音中的静音不一定表示单词边界
- 歧义:不同书写的文本可以发音相同,例如,在英语中 bare 和 bear 发音相同
- 连音现象:相邻的语音可以相互作用并影响彼此的发音,例如,在 I have to 中的 v 发音为 f(在快速语音中),因为后面的无声 t
- 所谓的 隆巴德效应:不能简单地通过添加噪音来扩充数据集,因为人们在嘈杂环境中会改变说话方式(不仅仅是说得更大声…)
- 与典型的书面语言相比,语音可能包含不合语法的结构、不完整的句子或单词、纠正、单词/音节重复和中断
- 说话者适应:不同性别、年龄、文化背景等的人在发音上有很大差异
- 人类的语音理解在很大程度上依赖于上下文背景信息来进行可接受的解释——我们使用上下文线索主动“感知”/“听到”语音。一个戏剧性的例子可以在这里听到
任务变体
连续与孤立识别:
- 在孤立情况下,输入要么由单个单词组成,要么可以轻松分段成单个单词(因为有分隔的静音)
- 在连续情况下,单词之间可以没有任何静音,就像正常语音一样。连续语音识别要困难得多
联合识别(可能带有说话者分离):基本的语音识别是针对一个说话者的:更复杂的变体是有多个说话者(例如,在对话中),并且,选择性地,转录必须指示谁在说什么(说话者分离)。在这种情况下,重叠语音可能是一个特别困难的问题
评估
最常见的评估指标是词错误率 (WER),它基于与正确转录相比的词级编辑距离。如果 $\hat{W}$ 是输出,$W$ 是正确的转录,那么 WER 简单定义为
$$
\frac{\mathrm{Levenshtein}(\hat W, W)}{\mathrm{length}(W)},
$$
即,从正确转录得到输出所需的每个词的平均词级编辑操作数。
训练数据
一般来说,训练数据包括录制的语音音频和时间对齐的书面转录。
过去,转录是音素级的,并在音素级别对齐,因此注释者必须通过听和查看波形来确定音素边界:
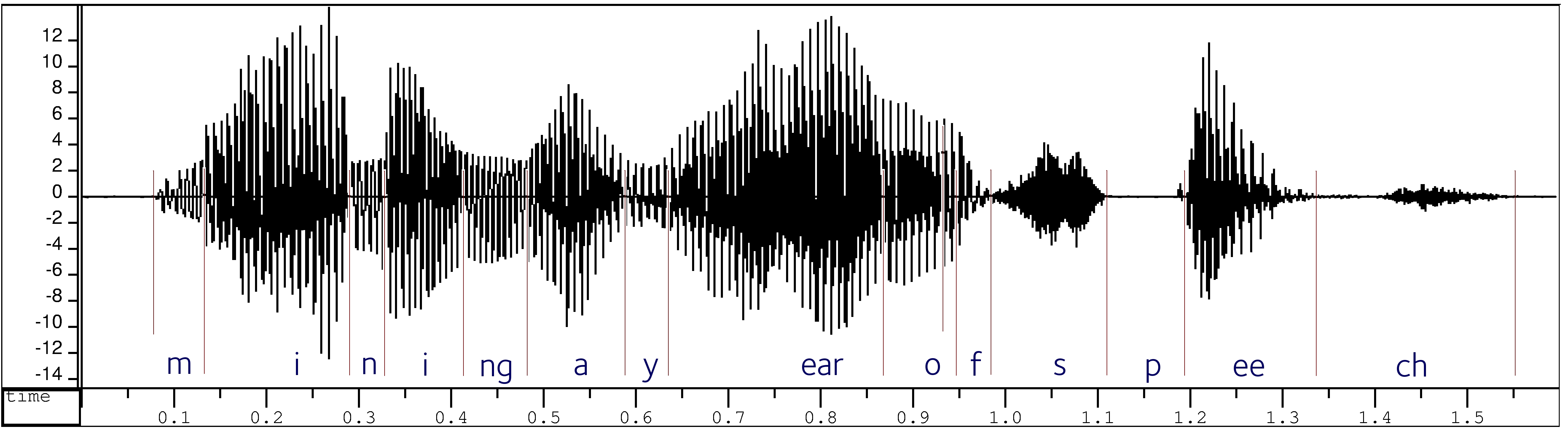
训练方法的改进使得音素级对齐变得过时:现代 ASR 数据集包含正常书写的转录,只需在句子级别进行时间对齐。
尽管有这些改进,创建好的 ASR 数据集仍然需要大量工作,因为可用语料库的大小从多个说话者(包括男性和女性)的 20 小时语音开始。由于相关成本,即使是最广泛使用的语言,免费语料库的数量也很少,对于许多语言,根本不存在免费的数据集。
LCD 数据集
对于英语,直到最近,大多数公共数据集都是由语言数据联盟 (LDC) 发布的。这些包括
- 华尔街日报音频语料库(阅读报纸文章,80 小时,1993 年)
- Fisher 语料库(电话语音,1600 小时,2004/2005 年)
- Switchboard 语料库(电话语音,300 小时,1993/1997/2000 年)
- TIMIT 语料库(阅读示例句子,有限的语法/词汇变异性,1986 年)
最近,其他语言的数据集也被添加到 LDC 目录中,现在它包含西班牙语、普通话和阿拉伯语等。
开放计划
不幸的是,LCD 数据集通常不是免费的,访问大多数数据集需要 LDC 会员或支付费用。
最近创建和管理免费数据集的计划:
开放语音和语言资源页面 列出了几种语言的多个免费数据集,其中包括重要的 LibriSpeech 语料库,包含约 1000 小时的有声读物语音
Common Voice:Mozilla 项目,旨在为尽可能多的语言收集 ASR 数据集。已经收集并验证了 2484 小时的英语转录语音,其他语言也在进展中,截至撰写本文时,德语为 1290 小时,法语为 958 小时
语音信号处理
时间上的连续语音信号
当语音被记录时,空气压力的变化会移动麦克风的振膜,这些运动被转换为电子电流的变化——因此,语音被表示为连续信号:
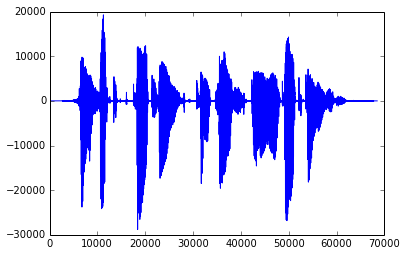
采样
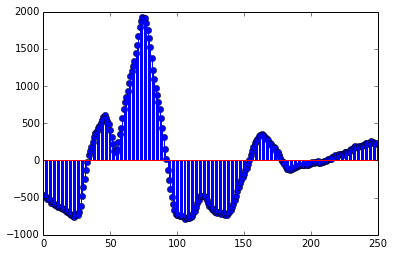
这是一个连续的模拟信号,可以通过以一定的速率采样进行数字化(至少 8kHz,以表示 100 Hz–4 kHz 范围内的音素):
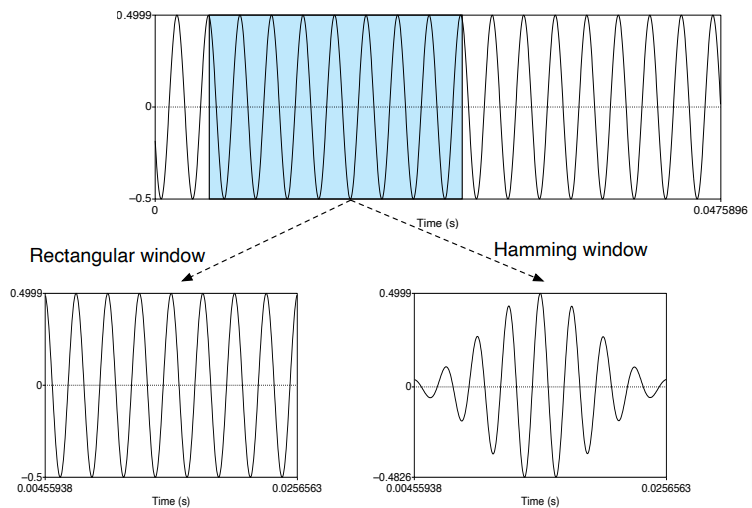
窗口化
数字信号通过取重叠的窗口(20-40 毫秒是典型长度,10 毫秒是典型步长)转换为一系列短信号:
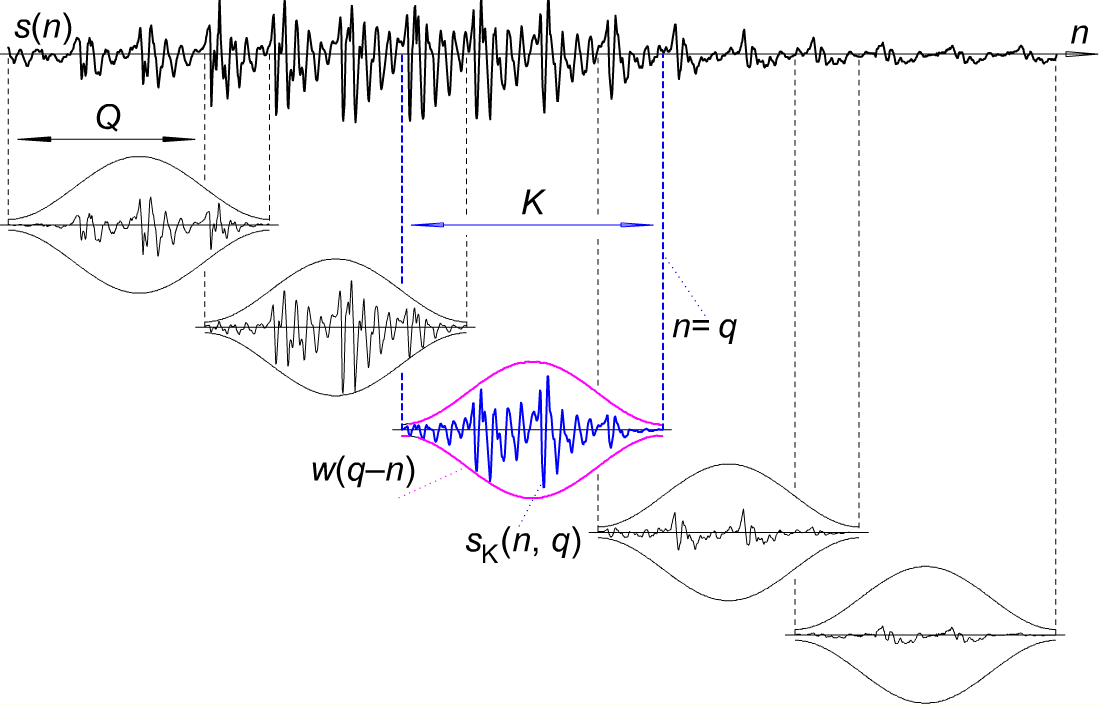
窗口通常包含接近窗口端逐渐衰减的加权值。一种流行的加权方案基于余弦函数:对于具有原始信号值 $s_0,\dots,s_{N-1}$ 的窗口,加权值为
$$w(n) = a - (1 - a)\cos\left(\frac{2\pi n}{N}\right)$$
选择 $a = 0.54$ 会导致常用的 Hamming 窗口。
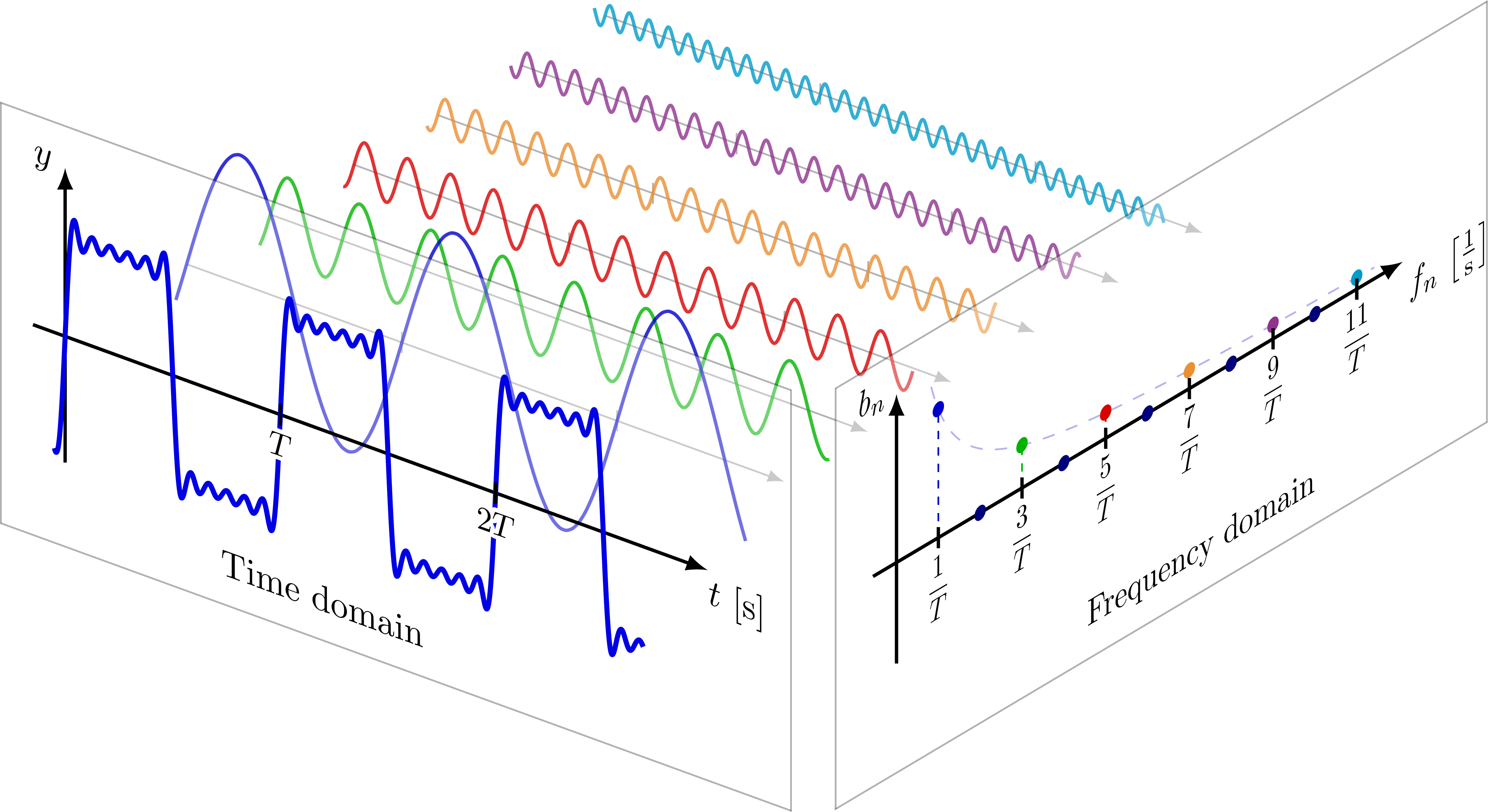
傅里叶变换
窗口化信号通过离散傅里叶变换(DFT)转换为各自的频谱:
进一步处理
尽管许多最新的方法直接使用频谱,但传统上,进一步的转换是通过以下方式完成的,例如:
- 使用滤波器组
- 取(平滑)频谱的对数
- 执行进一步的傅里叶变换
其目的是提供接近人类感知和处理语音的特征压缩表示。历史上最重要的表示是 MFCC(梅尔频率倒谱系数),它结合了上述几个步骤。
梅尔尺度
FFT 返回的频谱信息并不对应于人类感知声音的重要特征:
- 我们的听觉在频率较低时更敏感和辨别力更强,
- 反映声音之间感知距离的听觉频率尺度实际上是对数的。
对应于频率 $f$ 的感知音高可以通过计算其在对数梅尔尺度上的位置来表示(其中 mel [来自 melody] 是听觉音高距离的单位):
$$ mel(f) = 1127 \ln \left(1+\frac{f}{700} \right ) $$
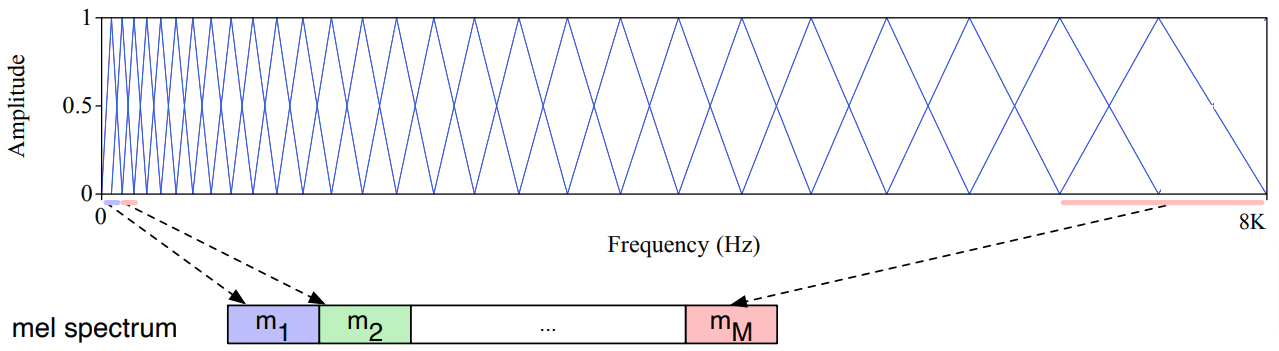
梅尔滤波器组
梅尔滤波器组是一组根据梅尔尺度均匀间隔的重叠(通常是三角形或余弦形状)滤波器。它可以用于将频谱转换为包含感知信息频带的梅尔频谱。
MFCC(梅尔频率倒谱系数)
MFCC 是语音识别领域中最广泛使用的频谱表示。“倒谱”是 DST 步骤的结果。
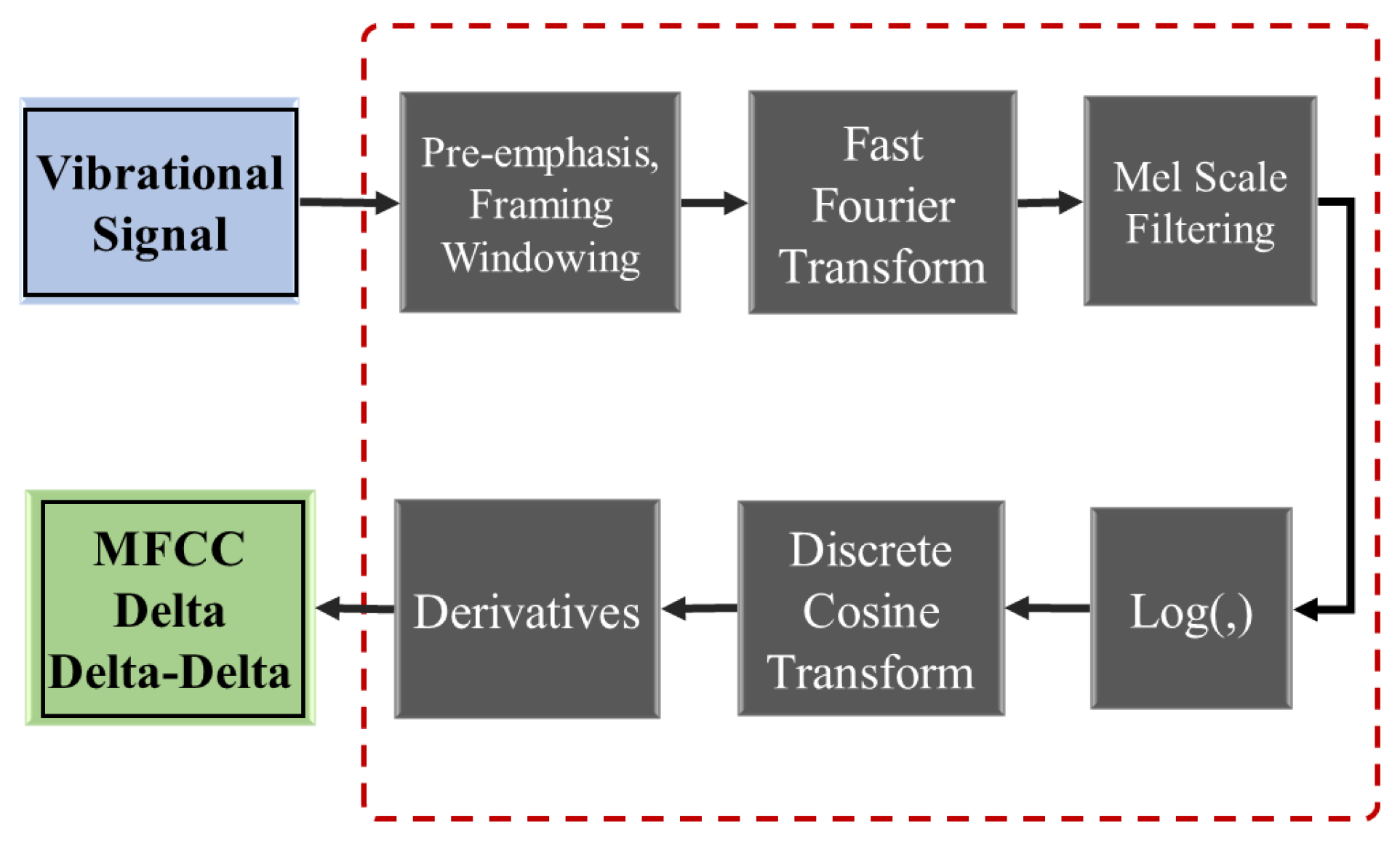
典型的 MFCC 帧特征向量包含以下 39 个值:
- 12 个基本 MFCC 特征(倒谱中的 12 个能量值)
- 倒谱中的总能量
- 12 个 delta MFCC 特征(MFCC 导数)
- 12 个 double delta MFCC 特征(MFCC 二阶导数)
- 1 个总 delta 能量特征
- 1 个总 double delta 能量特征
语音建模
我们尝试在给定(预处理)语音信号 $\mathbf s$ 的情况下找到最可能的 $\mathbf w=\langle w_1,\dots,w_n\rangle$ 词序列,即
$$ \underset{\mathbf w}{\operatorname{argmax}} P(\mathbf w \vert \mathbf s). $$
使用贝叶斯规则,这可以重新表述为
$$
\underset{\mathbf w}{\operatorname{argmax}}(P(\mathbf s \vert \mathbf w) \cdot P(\mathbf w)).
$$
这里 $P(\mathbf w)$ 可以通过语言模型建模,而给定词序列的声音信号的条件概率 $P(\mathbf s \vert \mathbf w)$ 则通过声学模型建模。
声学模型
在经典的 STT 中,声学模型通常包含目标语言音素的 HMM 模型。一个常见的选择是使用 3 状态 HMM 来建模音素,并使用高斯混合作为发射分布(3 个状态分别表示音素的开始、中间和结束):
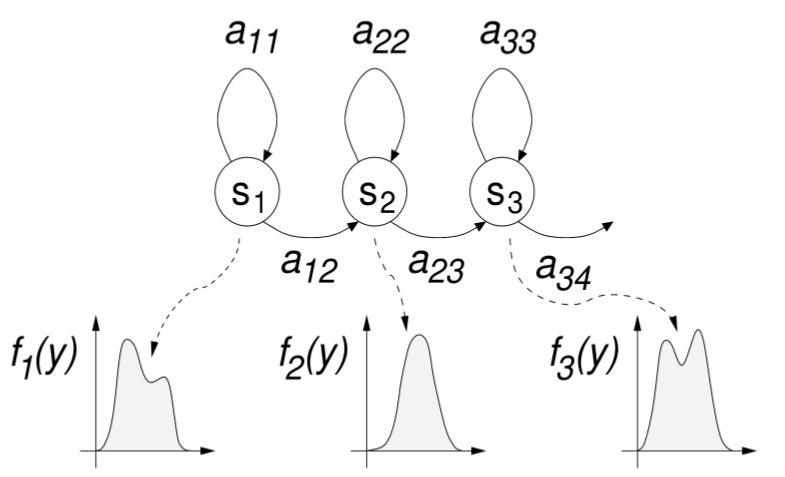
上下文相关的音素模型
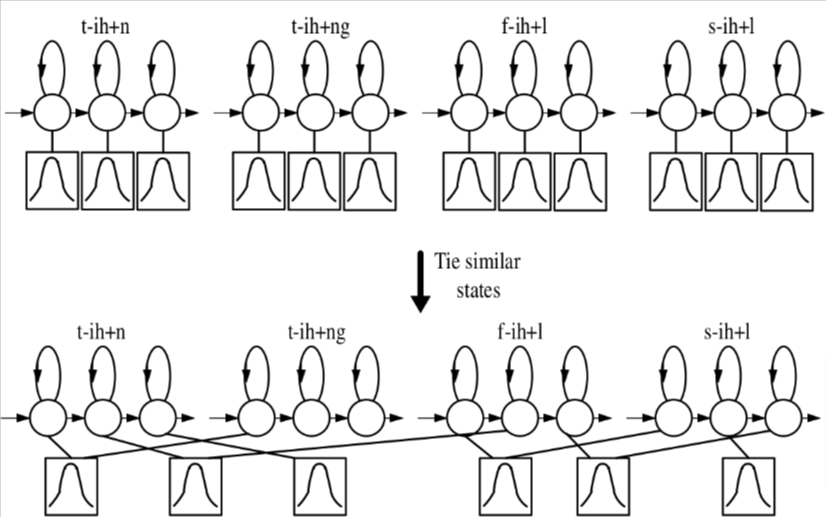
自然语言中的音素是上下文相关的:它们的物理实现取决于前后的音素。因此,更复杂的语音识别器使用上下文相关或“三音素”模型:
由于音素组合的数量庞大,一些 HMM 状态被共享或**“绑定”**在一起:假设它们具有相同的发射分布,以减少模型参数的数量。
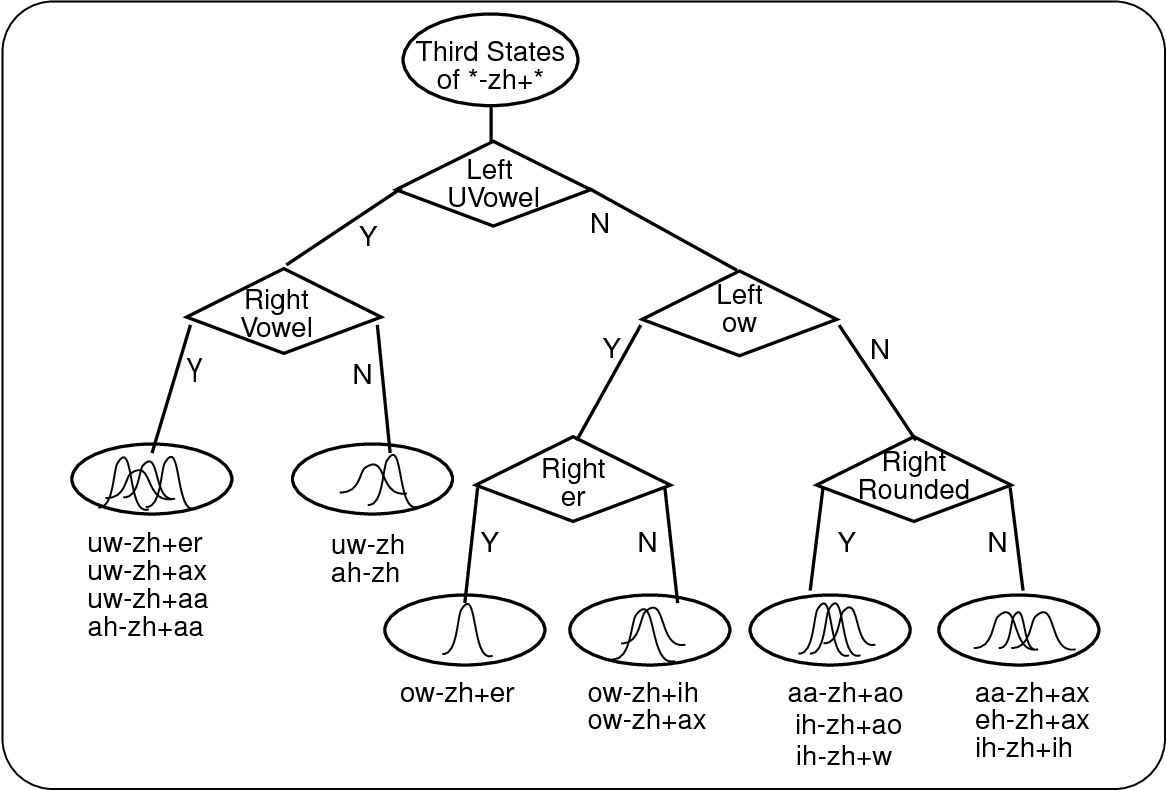
使用 MLE 优化的音素决策树将隐藏状态聚类为可以绑定在一起的组。
声学模型训练
基于 HMM 的声学模型与 GMM 发射分布通过期望最大化 (EM) 使用以下内容进行训练:
- 转录的语音样本,其中的转录精确地对齐时间
- 描述转录中所有单词发音的音素词典
在早期,转录是音素级别并逐个音素对齐,但现代系统使用单词或句子对齐的转录,其音素转录是使用音素词典自动生成的。
由于 HMM 可以组合(在这种情况下是串联的),使用音素词典,音素模型可以用于构建单词模型,单词模型又可以提供用于更高级别训练的单词序列模型:
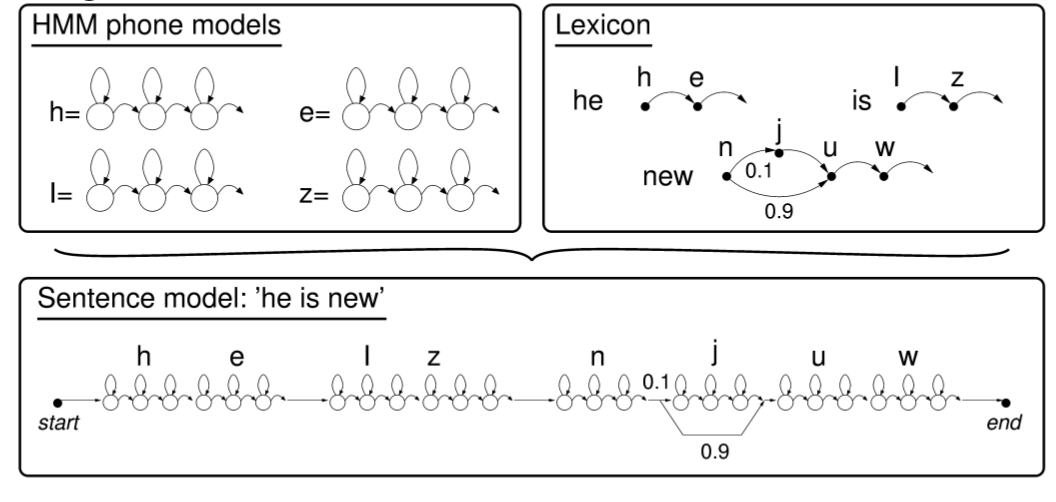
现代基于 HMM 的系统如 Kaldi ASR 不直接在训练数据集上训练其最复杂的模型,而是训练一系列模型:
- 首先训练一个单音素声学模型,并将该模型与音频对齐
- 训练好的单音素模型用于开始训练三音素模型
- 进一步的训练和对齐步骤使用额外的训练算法重复进行,以获得更高质量的模型(例如,使用 delta 特征等)
添加语言模型
由于传统的 N 元语言模型也基于马尔可夫假设,基于 HMM 的声学模型可以很容易地与它们结合,形成一个 联合声学 + 语言 HMM $\mathcal A + \mathcal L$,可以用来在给定声学输入的情况下找到最可能的单词序列。
$$ \underset{\mathbf w}{\operatorname{argmax}}~P_{\mathcal A + \mathcal L}(\mathbf w \vert \mathbf s) $$
理论上,可以使用完整的维特比算法,但其在状态数量方面的二次时间复杂度使得这在连续的大词汇量语音识别中不可行,因为组合的 HMM 非常大。