NLP-RNNs
递归神经网络
介绍
使用神经网络进行语言建模
正如我们所见,使用学习到的词嵌入的前馈神经网络语言模型已经比传统的 $n$-gram 模型表现得更好:
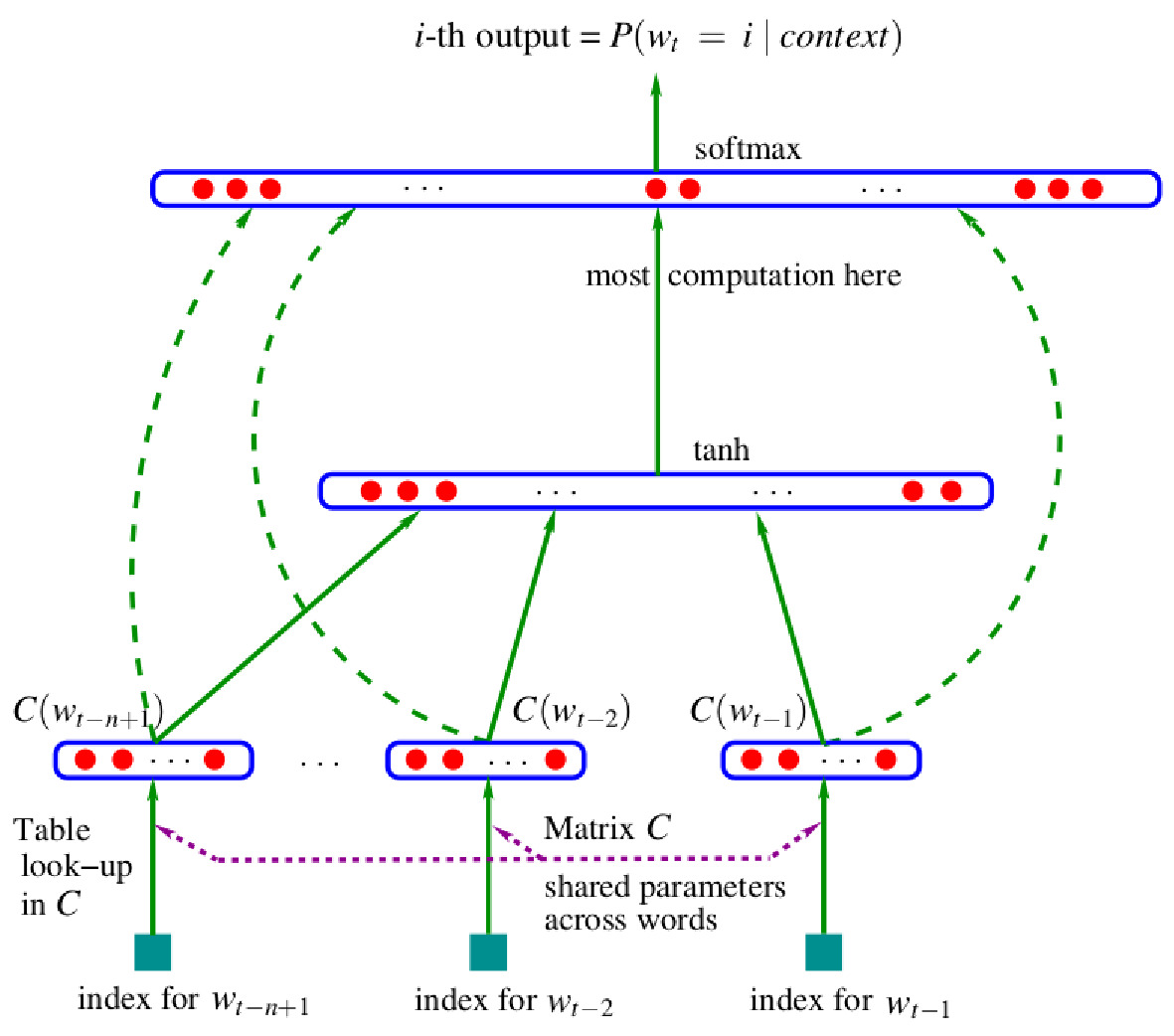
与最好的 $n$-gram 模型相比,困惑度提高了24%。
但这些模型仍然与$n$-gram模型共享一个重要的限制:续接(continuation)预测基于固定大小的上下文窗口,没有任何关于早期历史的信息:
其中 $\phi(\cdot)$ 是由前馈神经网络计算的函数。
循环神经网络 (RNNs)
Recurrent Neural Networks与此不同,它们不受限于固定长度的输入序列,并且至少在理论上可以形成有用的任意长历史的内部表示。它们可以逐步处理顺序输入,并在每一步更新内部状态:
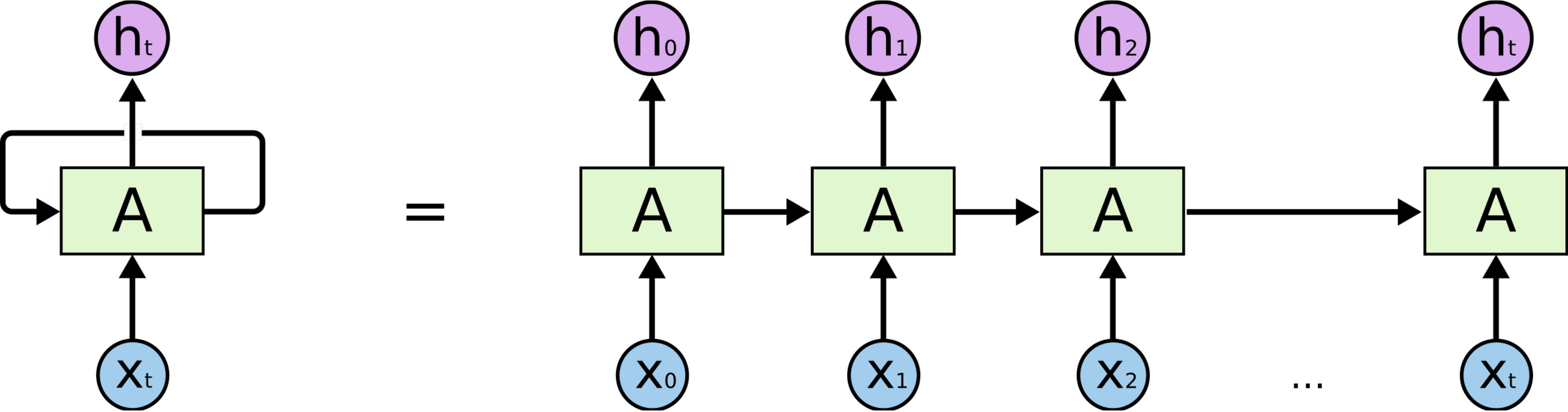
RNNs 可以非常简单,例如曾经广泛使用的 Elman 网络具有以下结构:
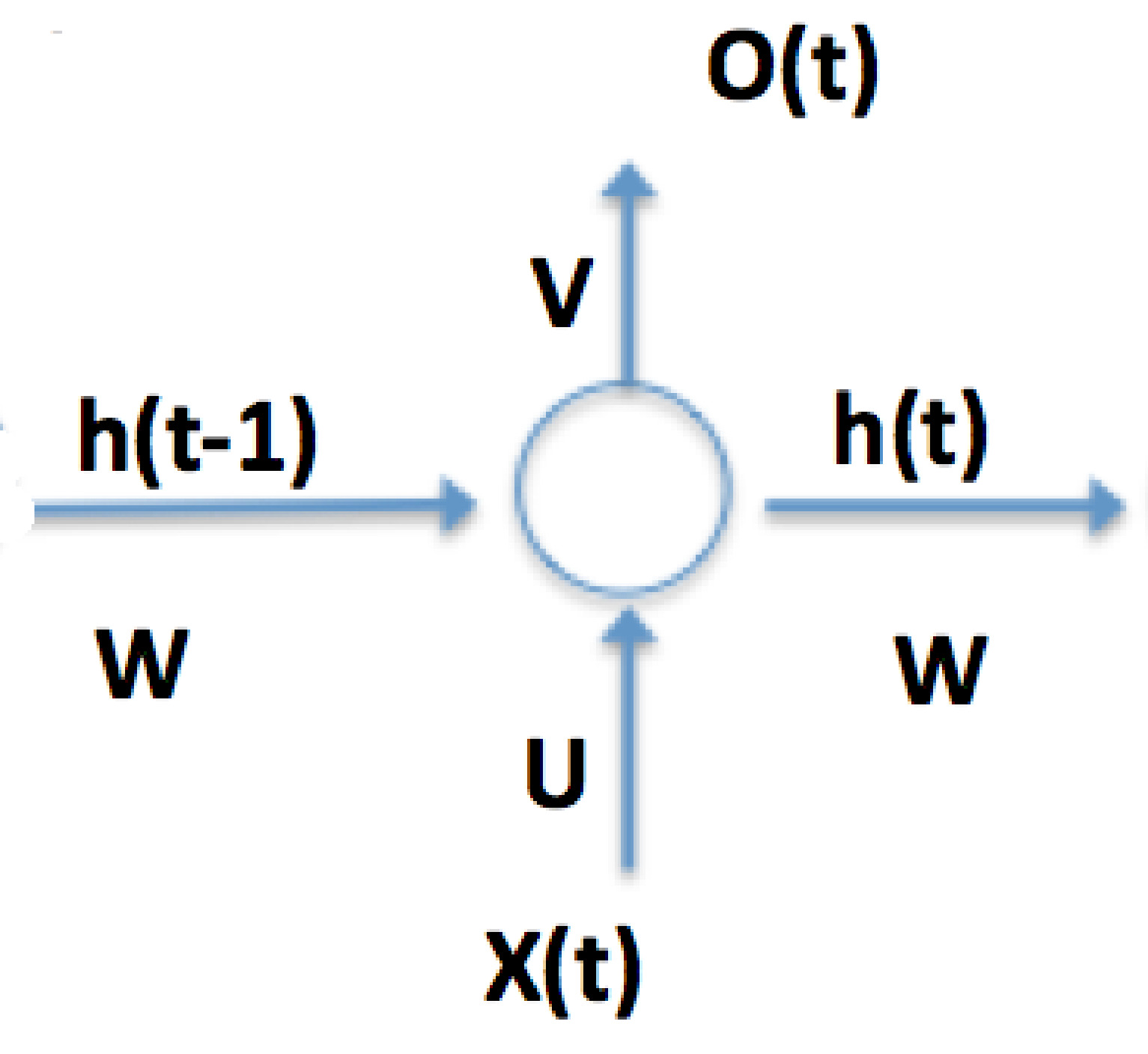
$$h_t = a_h(U x_t + W h_{t-1} + b_h )$$
$$o_t = a_o(Vh_{t} + b_o )$$
反向传播通过时间
RNNs 的标准优化方法是backpropagation through time (BPTT),这是应用于时间展开网络的反向传播:
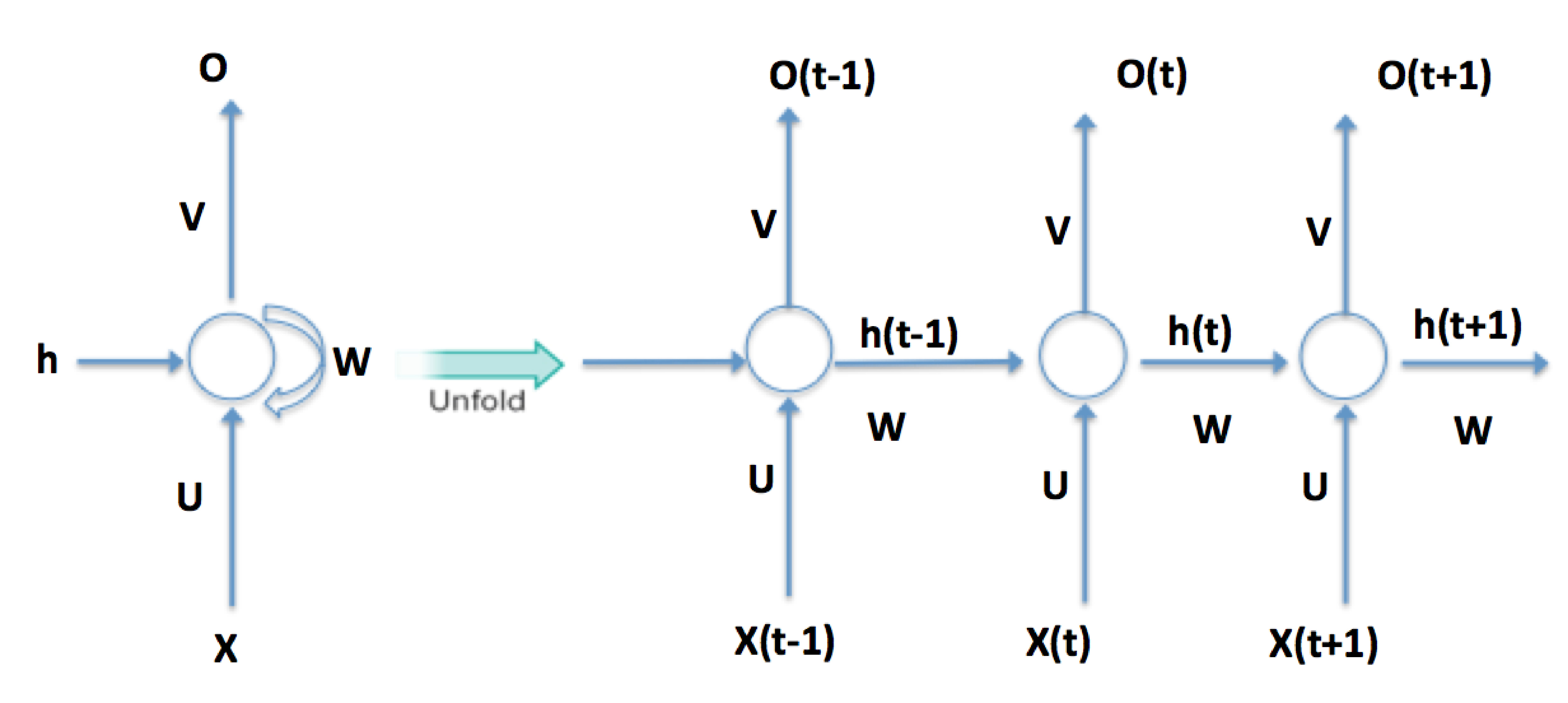
由于展开的 RNN 的深度随着展开的时间步数线性增长,通常无法对所有时间步进行反向传播。
在这些情况下,展开和误差的反向传播仅在一定数量的时间步内进行 - 反向传播是截断的(backpropagation is truncated)。实际上,大多数神经网络框架实现了截断反向传播。
RNN 训练挑战
训练 RNNs 存在显著的挑战:
一个展开了多个时间步的 RNN 在反向传播方面表现得像一个深度前馈网络,因此梯度消失(vanishing)和梯度爆炸(exploding gradients)都可能成为问题,尤其是因为完全相同的层被重复使用。
特别是梯度消失,意味着 RNN 无法学习长期依赖(long-term dependencies),而这在理论上应该是它的强项。
长短期记忆网络
Long Short-Term Memory (LSTM)
一种复杂的门控拓扑(gated topology)结构,使 RNNs 具有长期记忆,并解决了 梯度消失/爆炸 问题。
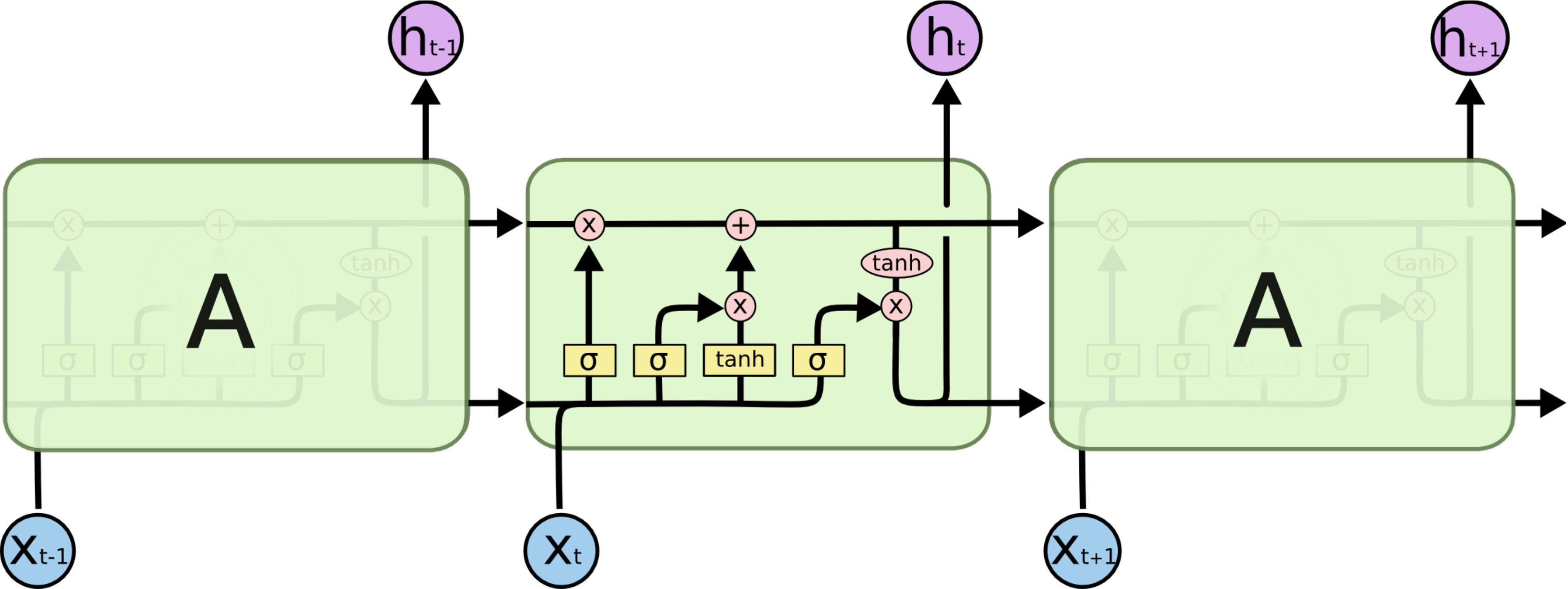
Cell state
LSTM 的单元状态充当“信息传送带”(conveyor belt),信息可以在时间步之间传递。
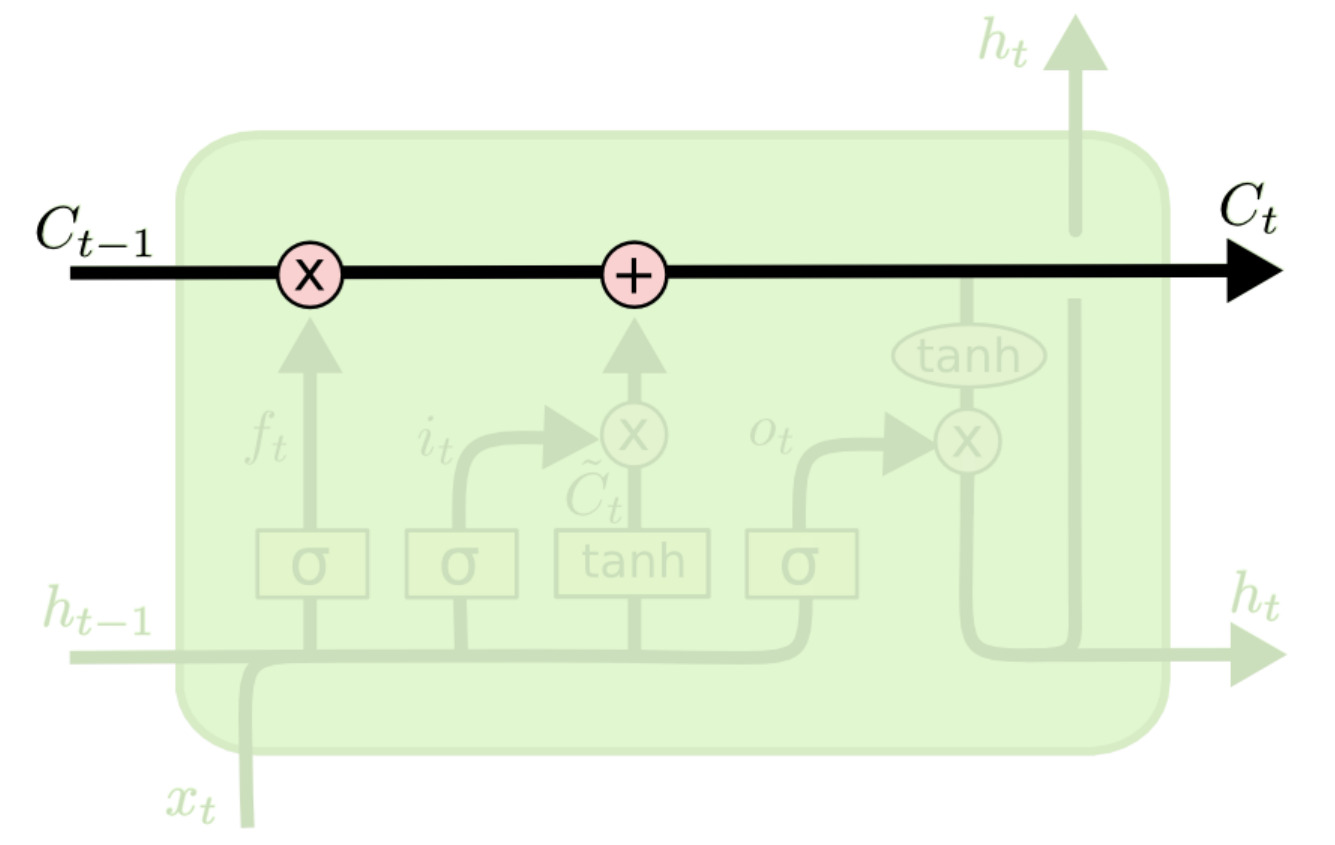
Forget gate
遗忘门计算一个 $f_t\in (0,1)^d$ 掩码,用于从单元状态中移除信息:
$$f_t=\sigma(W_f[h_{t-1}, x_t] + b_f)$$
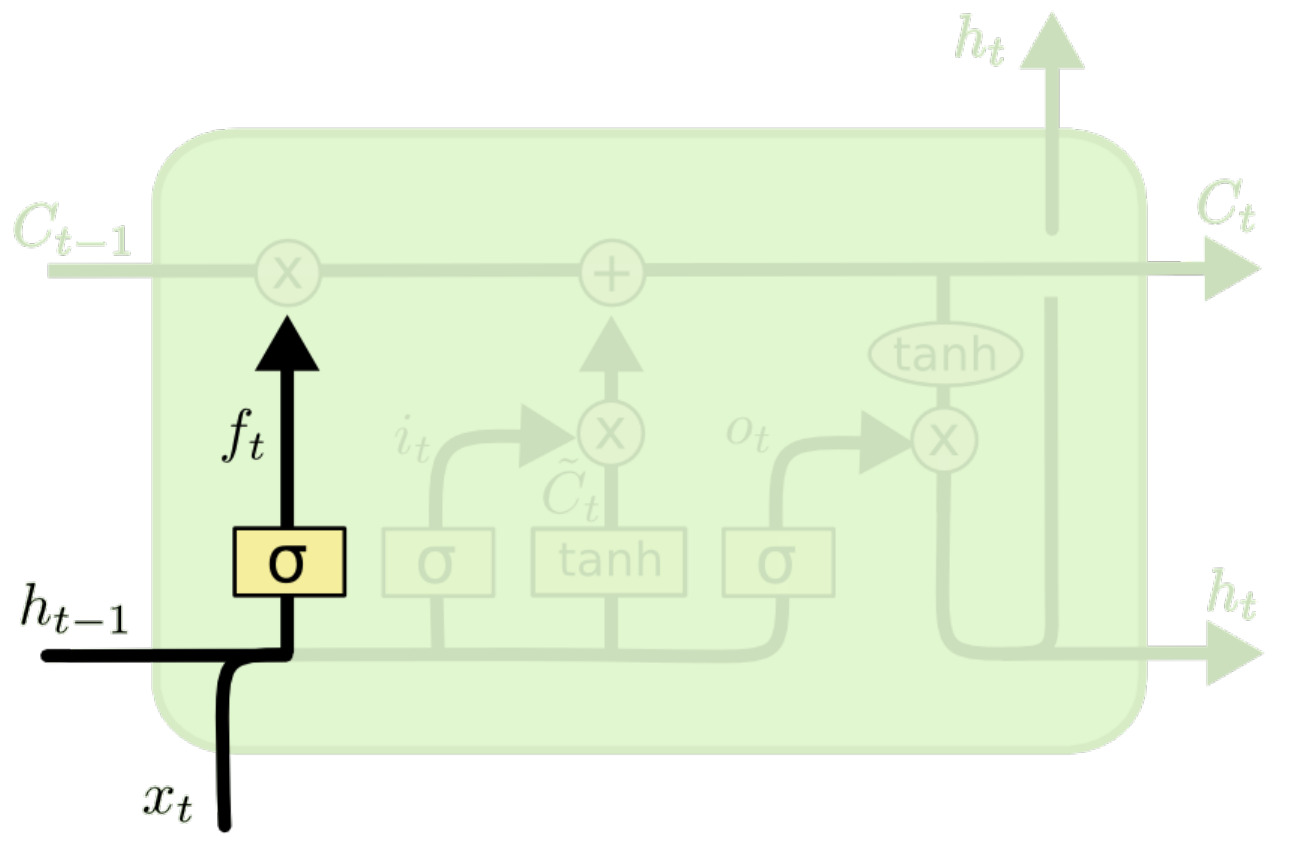
Input gate and update vector
计算输入掩码 $i_t$ 和更新向量 $\tilde C_t$:
$$i_t=\sigma(W_i[h_{t-1}, x_t] + b_i)$$
$$\tilde C_t = \tanh(W_C[h_{t-1}, x_t] + b_C)$$
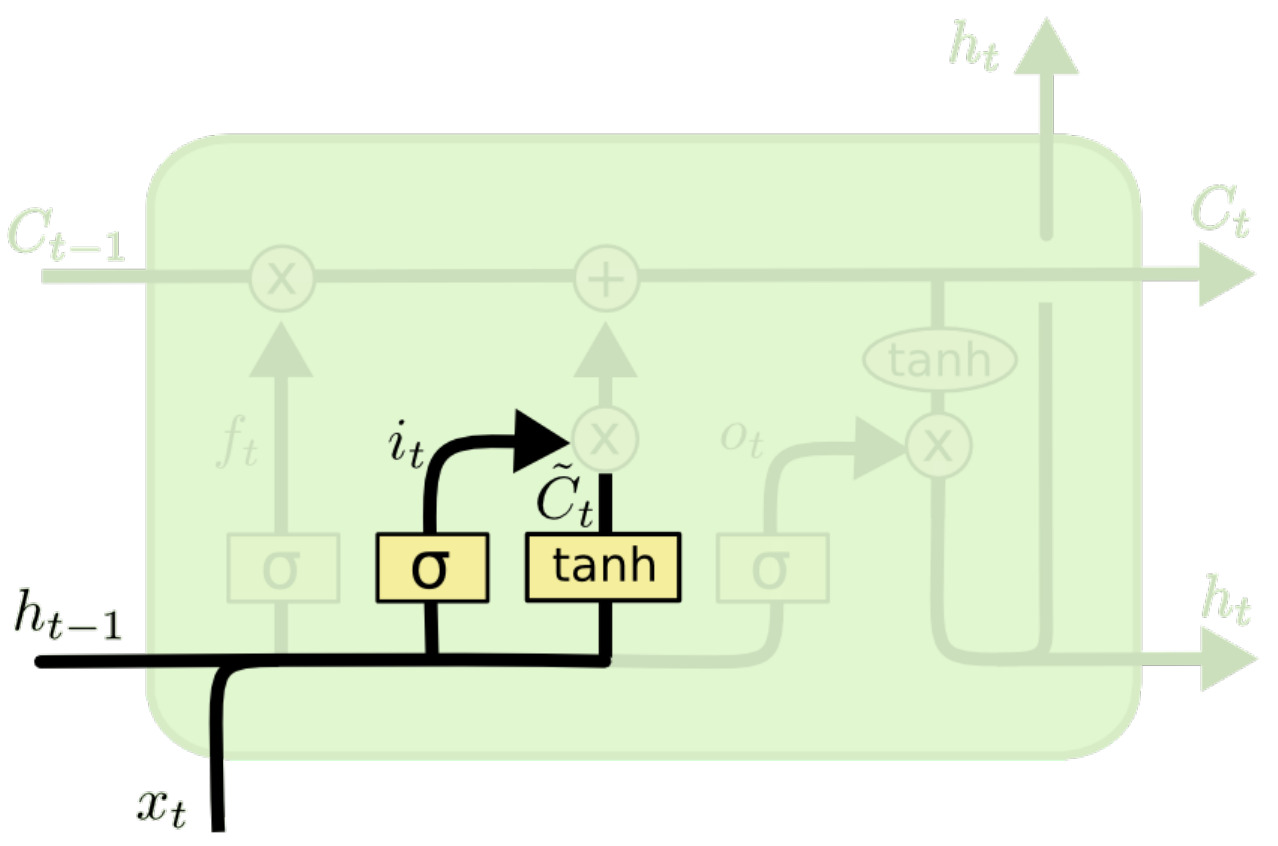
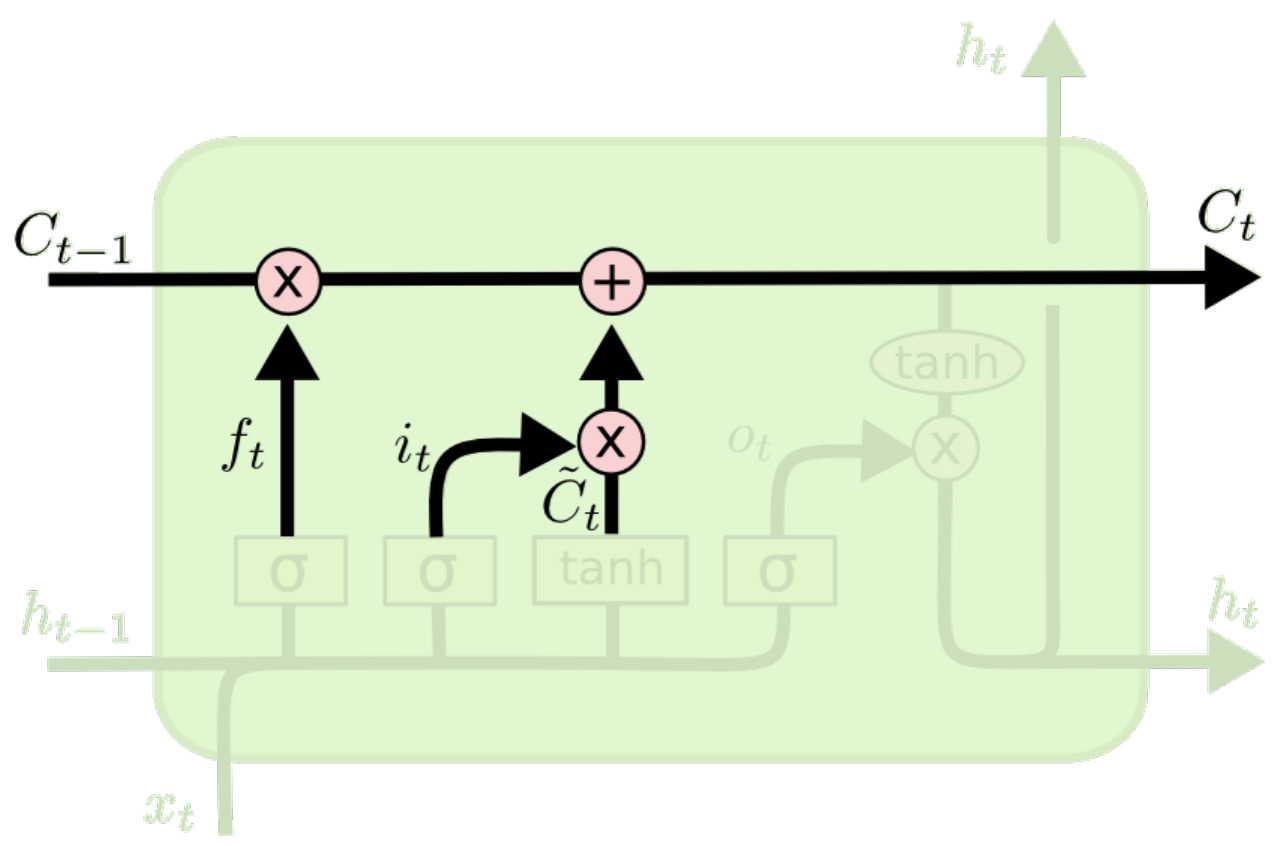
计算新的单元状态
使用 $f_t, i_t$ 和 $\tilde C_t$ 计算新的单元状态:
$$C_t = f_t \odot C_{t-1} + i_t \odot \tilde C_t$$
输出
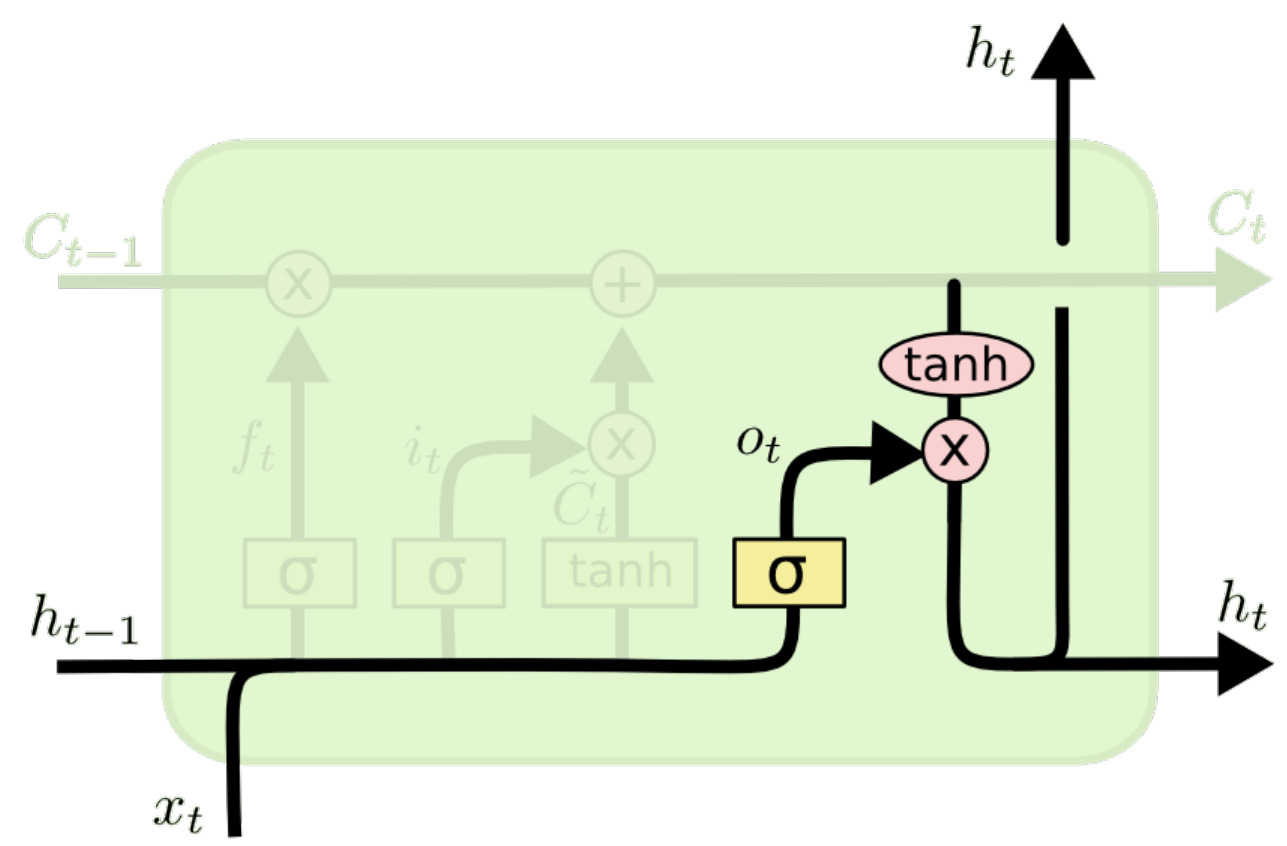
最后,生成输出 $h_t$:
$$o_t = \sigma(W_o[h_{t-1}, x_t] + b_o)$$
$$h_t = o_t \odot \tanh(C_t)$$
LSTM 优势
门控 LSTM 架构通过确保梯度可以流向远处的时间步,解决了梯度消失/爆炸的问题。
更新是加性(additive)的,这意味着梯度不会像 Elman 网络那样被相乘,并且门控可以在训练期间获得权重,使网络能够在输入和输出值之间表现出长距离依赖关系。
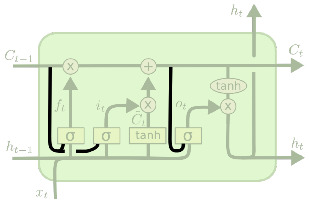
LSTM 变体:窥视孔连接
Peephole connections 通过允许门控访问实际的单元状态来扩展 LSTM 架构:
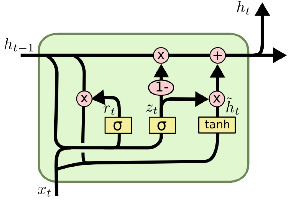
LSTM 变体:门控循环单元
Gated Recurrent Unit (GRU) 是一种简化的 LSTM 变体,它去除了单独的单元状态,并合并了遗忘门和输入门:
使用 RNNs 进行语言建模
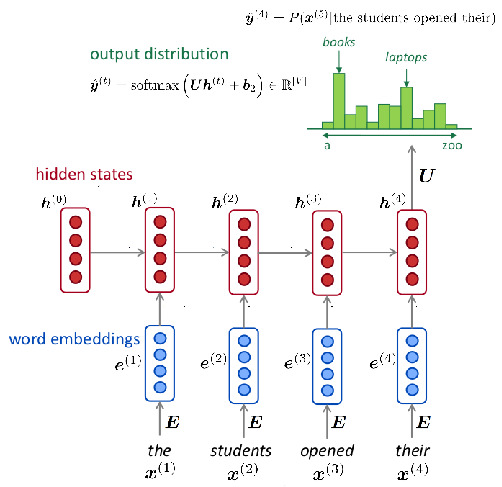
该模型最显著的特点是:
之前的词(“left context”)逐步处理,每次一个词
第一层是静态词嵌入
$h_t$ RNN 的直接输出(隐藏状态)通过仿射(affine)变换和 $\mathop{\mathrm{softmax}}$ 非线性变换,转化为词汇表上的续接概率分布
序列元素
虽然传统的 RNN 语言模型是基于词的,即序列元素是词,但有两个重要的替代方案:
字符级 语言模型将character视为序列元素,并根据之前的字符预测下一个字符
子词级 语言模型基于subword分词(例如 BPE),并预测词汇表中的下一个子词
这两种类型的模型都可以利用相应的字符和子词嵌入。
训练
基于 RNN 的语言模型与所有参数化语言模型一样,使用通常的负对数似然损失进行训练:如果训练序列是 $\langle w_1,\dots, w_n \rangle$,并且 $\hat P_i$ 是模型对第 $i$ 个续接概率的输出分布,那么损失是
$$- \sum_{i=1}^n \log \hat P_i(w_i)$$
但是在训练期间,每个时间步 RNN 的输入应该是什么?应该来自训练数据,还是来自 RNN 之前的预测?
RNN 语言模型通常使用训练数据作为输入进行训练。这称为teacher forcing。
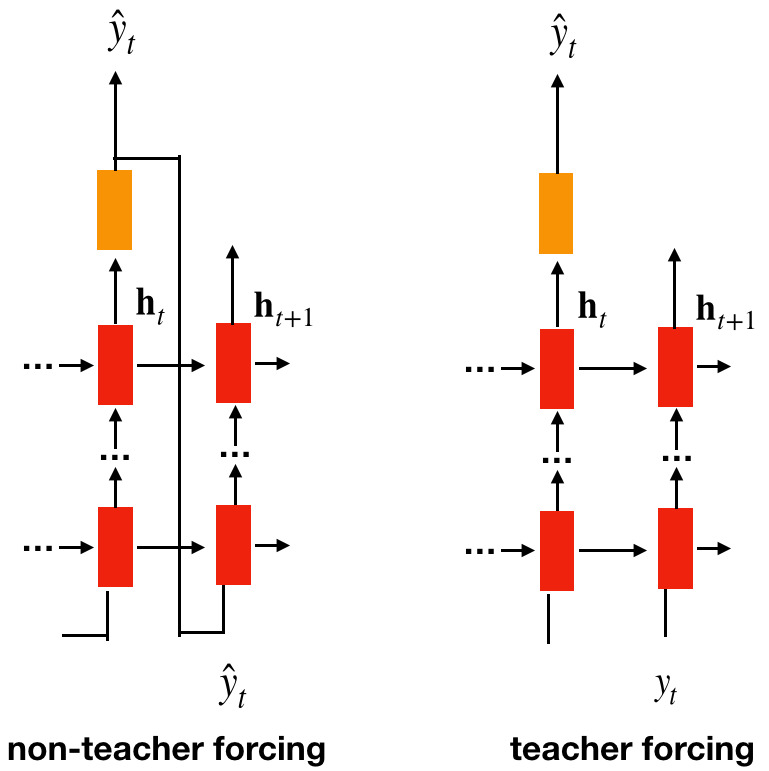
Exposure bias
尽管教师强制是目前最常用的训练方法,但它有一个主要问题,即所谓的 曝光偏差 现象:
使用教师强制训练的语言模型仅暴露于其输入完全来自训练语料库的情况
相比之下,在推理期间,它们必须为不在训练数据中的文本生成续接,最重要的是,在文本生成期间,它们必须继续自己的输出
解决方案
- 计划采样:在每个时间步随机选择使用训练数据作为输入还是从模型的预测中采样。选择从训练集中的概率从 1.0 开始,并在训练期间逐渐减少
- 可微采样:在原始 Scheduled sampling 中,误差不会通过使用的采样操作进行反向传播,因为它是不可微的。对此,开发了 Differentiable 的替代采样解决方案,最重要的是使用所谓的 Gumbel softmax 重参数化(reparametrization)
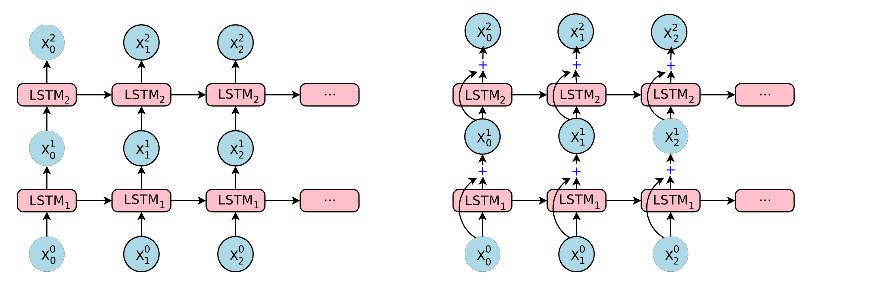
多层 RNN
现代基于 RNN 的架构经常将多个 RNN 单元堆叠在一起作为层,类似于多层前馈网络:
性能
在 transformer 出现之前,基于 LSTM 的语言模型在性能上始终优于其他架构,即使在现在也非常具有竞争力。
在 NLP-progress 跟踪的 9 个语言建模数据集中,有 5 个数据集上基于 LSTM 变体的模型(所谓的 Mogrifier LSTM)表现最好,而在剩下的 4 个数据集中,基于 LSTM 的模型非常接近(transformer 产生的)最先进水平。