NLP-Prompt
提示词
预训练、提示和预测
描述 GPT-3 的论文介绍了一种使用预训练语言模型进行下游任务的新范式:只需适当地提示模型,并将输出映射到任务的输出域,而无需任何微调。他们区分了三种场景:



一般提示规则
- 指令应尽可能 详细、具体 和 精确
- 指定输出的 预期受众(如果适用)通常是有用的
- 复杂的提示还可以包括
- 人物描述
- 上下文示例
- 约束(例如,预期输出格式的模板)
- 解决方案所需的步骤 – 这引出了“链式思维提示”的概念
Pretrain, prompt and predict
提示范式的一个重要特征是任务性能对提示的细节非常敏感:
- 示例选择
- 示例排序
- 任务表述
都可能产生巨大影响,因为模型具有各种偏差,其中包括:
- 多数标签 (majority)(imbalance 不平衡)偏差
- 新近性 (recency) 偏差(后面的标签更有影响力)
- 常见标记 偏差(更常见的标记更可能被预测)
提示工程
列出的偏差(以及其他偏差)使得 优化 用于基于大型语言模型的零样本或少样本任务解决方案的提示变得至关重要,即使用适当的 提示工程 方法。
任务表述
formulation
提示挖掘
mining
给定一个监督数据集 ${\langle x_i, y_i \rangle}_{i=1}^{N}$,可以取一个语料库(例如,维基百科)并 搜索连接 $x$ 和相应 $y$ 的词或句法结构。变体:
中间词提示
Barack Obama was born in Hawaii $\Rightarrow$ [x] was born in [y]
基于依存关系的提示
取包含 $x$ 和 $y$ 之间最短依存路径的最小跨度:
France $\xleftarrow{pobj}$ of $\xleftarrow{prep}$ capital $\xleftarrow{nsubj}$ is $\xrightarrow{attr}$ Paris $\Rightarrow$ capital of [x] is [y]
提示释义
从一个 种子提示 开始,通过 释义 生成候选提示(例如,通过翻译和回译)。
示例
种子: [x] shares a border with [y] $\Rightarrow$ [x] has a common border with [y]
$\vdots$
[x] adjoins [y]
[示例] 然后可以通过选择在目标任务的训练数据上表现最好的候选提示来选择最佳提示。
基于梯度的搜索
构建一个由触发词组成的提示模板,例如 AutoPrompt 算法:
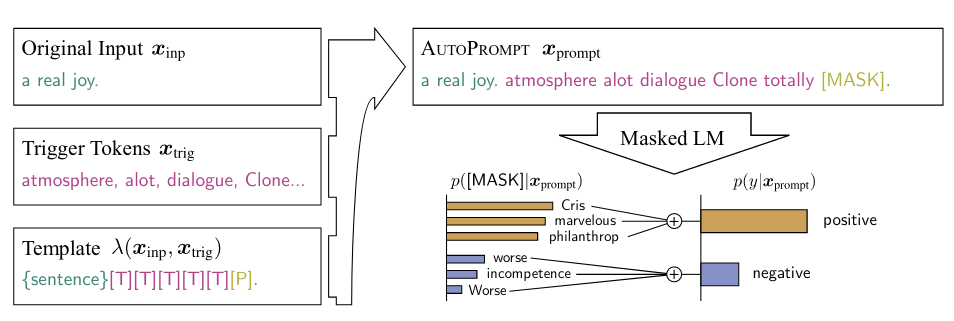
这些词由与坐标下降相关的算法找到:
- 初始化一个长度为 $L$ 的起始列表,填充掩码标记
- 对于每个 $i \in 1 \dots L$ 的标记位置
- 计算位置中标记嵌入的训练数据对数似然的 $\mathbf{g}$ 梯度
- 对于每个词汇条目,使用梯度近似在该位置使用该词会带来的对数似然变化,并选择前 $k$ 个词
- 从中选择对数似然值最大的一个词,并用它替换当前位置的标记
这显然假设梯度是可访问的,尽管不需要更改参数。
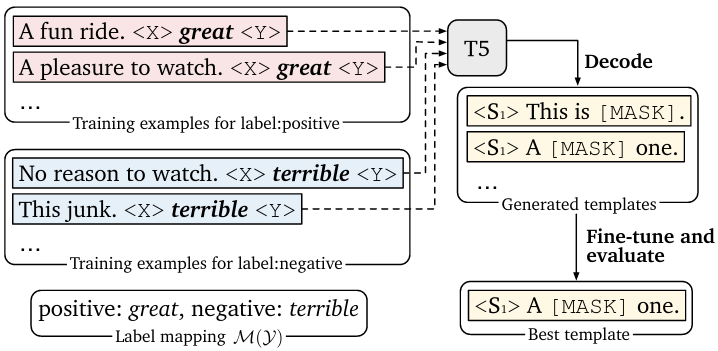
提示生成
可以将提示生成视为条件文本生成问题,并使用标准的 seq2seq 模型来解决。例如,使用预训练的 T5 生成在数据集上具有 高对数似然 的提示候选(使用束搜索):
一种更激进的方法是提示大型语言模型生成指令:

提示评分
最后,基于 BERT 的常识知识提取器,基于一组手工设计的提示模板,但对于任何具体的数据点,选择根据第二个预训练的单向语言模型(测量“连贯性”)具有最高概率的模板实例。

示例选择
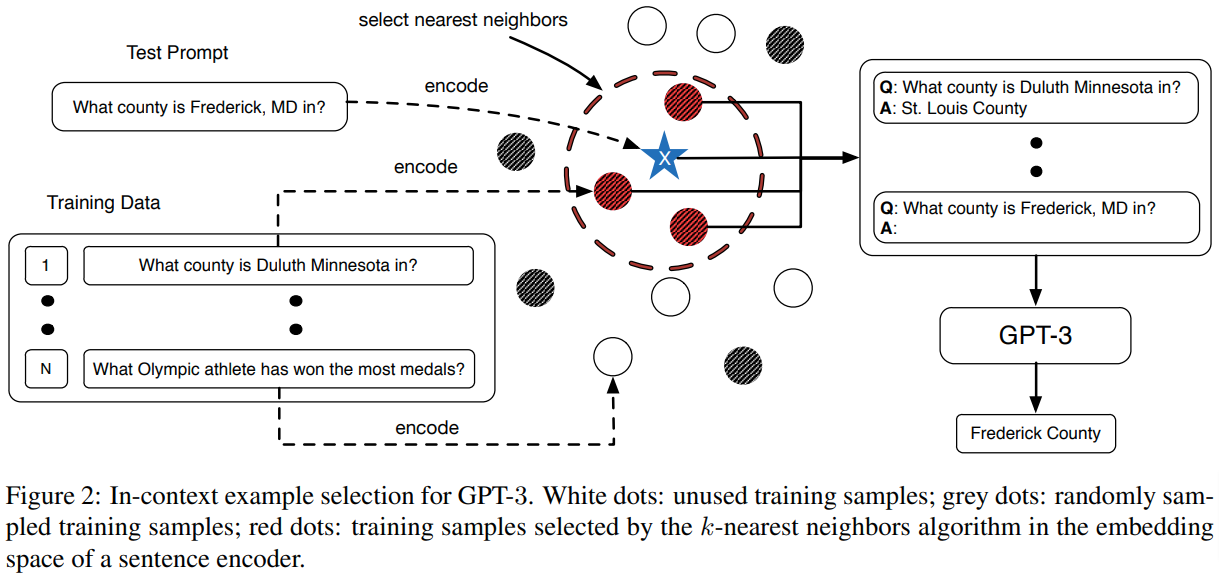
嵌入空间中的相似示例
从训练数据中选择相似和随机的示例用于少样本预测:
对比学习
依靠对比学习找到最有用的示例。提出的方法是:
- 使用(通常较小的)评分 $LM$ 在训练数据中找到正面和负面 $(e, x)$ 对,其中评分只是 $P_{LM}(y | e, x)$
- 使用对比学习训练一个度量嵌入模型,该模型可用于为任何(示例,$x$)对分配分数
- 对于任何 $x$,检索包含根据模型评分最高和最低的 $k$ 个示例的正面和负面示例,并在少样本提示中使用这些示例
连续(“软”)策略
前缀微调
学习任务特定的嵌入向量序列,以作为实际输入(以及编码器-解码器的输出)嵌入的前缀:

- 这些向量仅使用训练集上的对数似然目标进行微调
- 作者实验了仅将前缀的 输入 嵌入作为可学习参数与在 所有层 中前缀嵌入的处理方式,后者方法带来了显著更好的结果
- 该方法的表现与完全微调相似
前缀微调变体
连续前缀微调主题的变体:
- 离散初始化:优化可以从为任务自动或手动创建的离散提示开始,而不是随机初始化
- 离散-连续 混合微调:也可以固定提示的一些离散部分(使用“锚定标记”),并仅将前缀的其余部分作为可学习参数
- 辅助网络 (Auxiliary):建模前缀嵌入之间的交互使用(相对)简单的网络,例如 LSTM,结果非常有用
答案工程
LM 输出到下游任务输出域的映射也可以进行优化。
根据架构和任务,输出可以是
- 标记:这是分类任务的常见选择
- Span:包含几个标记,通常用于“填空提示 cloze prompts”
- 句子:语言生成任务的自然选择
对于某些任务,直接使用 LM 输出是可行的,例如文本生成,但当 $\mathcal{Y}$ 输出空间不同或受限时,需要进行映射,例如分类或命名实体识别(NER)任务。
一个简单的映射示例:$v(\cdot)$ “口头化”函数将下游主题分类任务的类标签映射到答案标记。(输入是一个“填空问题”,模型预测其中的内容。)
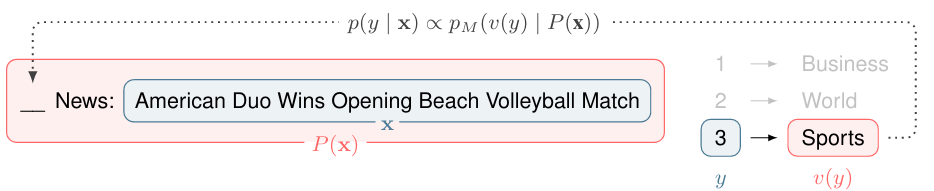
找到每个 $y\in \mathcal{Y}$ 对应的合适答案集的方法包括
答案释义
手动设计的种子答案集通过释义扩展。
修剪后搜索
创建一个初始集合,例如通过释义,然后在该集合中搜索 $y$ 的最佳答案,例如通过选择在训练数据集上具有最大对数似然的替代答案。
组合提示
提示集成
类似于模型集成,将多个未回答提示的 LM 答案组合到相同的 $x$ 输入可以带来更好或更稳定的性能。组合方法可以是
- 均匀平均 uniform:将组合提示的答案概率分布简单平均
- 加权平均 weighted:最终分布是答案分布的加权平均——权重可以来自提示在训练数据集上的表现
- 简单的多数投票 majority 也可以用于分类
对于文本生成,组合提示并不那么简单,但一种方法是在每个生成时间步使用所有下一个词概率分布的平均值来生成下一个词。
基于推理结构的提示
连锁思维提示
对于涉及复杂推理的任务,例如数学问题解决或规划,提供逐步演示可以显著提高性能。例如,
问题:Tom 和 Elizabeth 进行了一场爬山比赛。Elizabeth 爬山用了 30 分钟。Tom 爬山的时间是 Elizabeth 的四倍。Tom 爬山需要多少小时?
答案:Tom 爬山需要 30*4 = 120 分钟。Tom 爬山需要 120/60 = 2 小时。所以答案是 2。
问题:Jack 是一名足球运动员。他需要买两双袜子和一双足球鞋。每双袜子 9.50 美元,鞋子 92 美元。Jack 有 40 美元。Jack 还需要多少钱?
答案:两双袜子的总成本是 9.50 x 2 = 19。袜子和鞋子的总成本是 19 + 92 = 111。Jack 需要 111 - 40 = 71 美元。所以答案是 71。
问题:Marty 有 100 厘米的丝带,他必须将其切成 4 等份。每个切割部分必须再分成 5 等份。每个最终切割部分有多长?
答案:
更令人惊讶的是,“零样本连锁思维”在没有示例的情况下也有效:
问题:Marty 有 100 厘米的丝带,他必须将其切成 4 等份。每个切割部分必须再分成 5 等份。每个最终切割部分有多长?
答案:让我们一步一步地思考。
自洽采样用于连锁思维提示
Self-consistency sampling for COT,通过采样多个答案,即多个推理路径,而不是单一的贪婪解码,并将结果集成,例如通过多数投票,可以经常改善结果:

自问自答
Self-ask 提示模型明确提出并回答后续问题也是一种有用的策略:

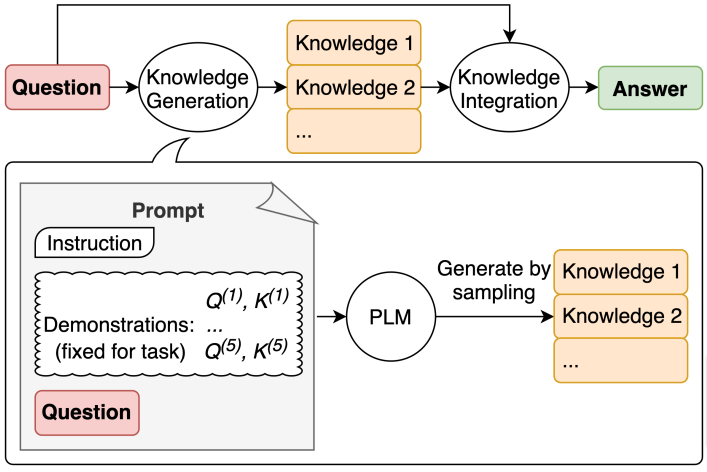
知识生成
对于常识推理任务,提示大型语言模型生成相关知识也可能是有益的。(具体的表述和示例取决于任务。)生成的知识片段用于回答问题:

通过采样生成多个知识提示的答案,并使用它们生成问题的答案。可以通过多数投票选择最佳答案:
更复杂的思维结构
关于连锁思维提示的一个常见观察是它假设了一条直接通向答案的顺序链(sequential
chain),但复杂的人类推理经常涉及
- 探索从共同起点分支的替代思维序列
- 丢弃一些思维分支
- 并回溯
直到找到最终结论。
思维树提示框架支持使用适当的提示执行这种类型的推理步骤。
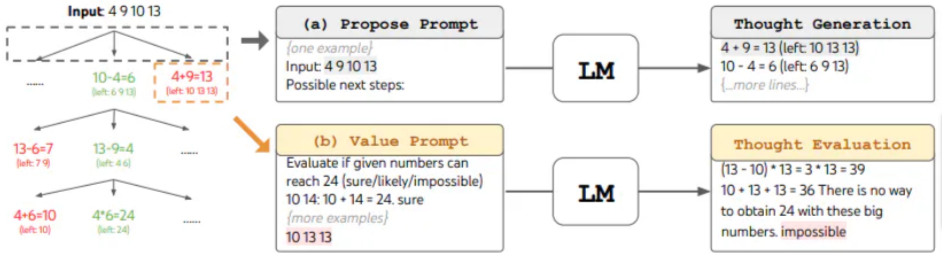
思维树提示
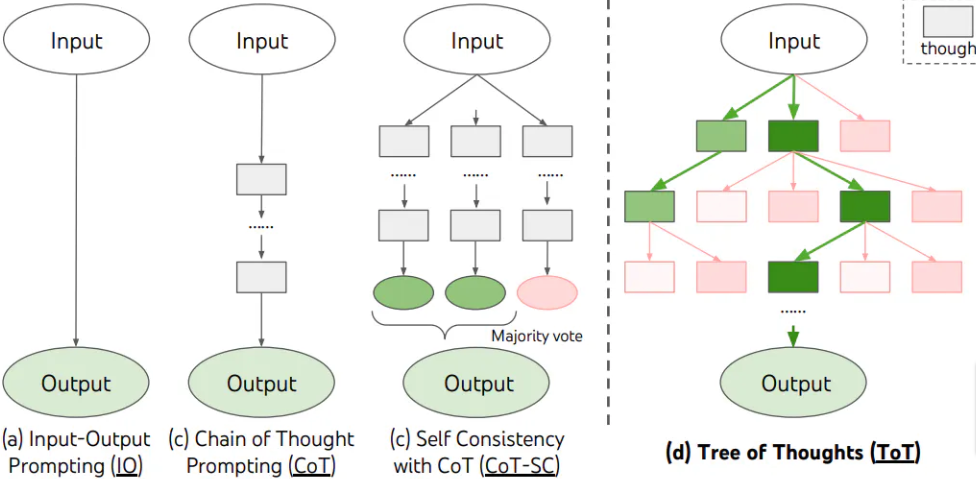
主要组件是:
- 明确定义当前任务的 单元思维(unit thought) 是什么(一个段落、一个公式等)
- 为一个分支生成 延续思维(continuation thoughts,例如,通过采样)
- 评估 思维
- 决定下一个扩展节点的 搜索策略(例如,广度优先搜索)
有尝试通过单一提示引出类似思维树的推理,例如,@tree-of-thought-prompting 使用以下示例提示:
1 | 想象三个不同的专家在回答这个问题。 |
图思维提示
树思维理念的自然扩展是添加思维路径的聚合。这导致将 T-o-t 提示推广到支持任意有向无环图拓扑的Graph-of-thoughts框架:
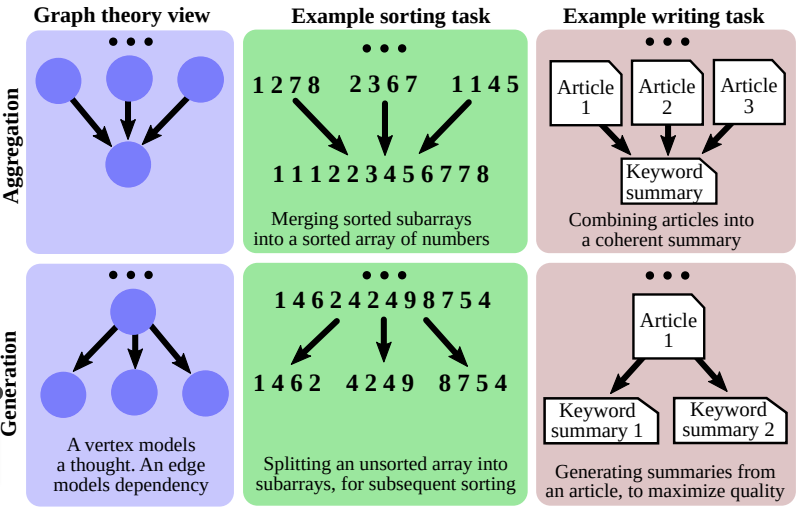
当然,增加的复杂性需要更复杂的架构,例如,使用以下模块(适应实际任务):
- Prompter 用于准备编码图结构的提示
- Parser 从输出中提取思维状态并更新动态的图推理状态结构
- Scorer 和 Validator 用于评估思维
- Controller 用于控制图构建过程的步骤
程序辅助的连锁思维推理
连锁思维提示的一个有趣研究方向是提示 LLM 进行形式推理或计算步骤(例如,Python 语句),并通过外部解释器或推理器执行这些步骤生成最终答案。

漏洞
除了与 LLM 相关的常见问题(可能的幻觉、危险或有害内容等),将外部输入纳入 LLM 提示的方法可能容易受到各种类型的对抗性提示(adversarial)的攻击,并且必须加以防范:
- 提示注入 影响 LLM 的行为,使其忽略原始指令做一些意想不到的事情
- 提示泄漏 注入内容,使 LLM 泄露其提示的细节,这些提示可能包含敏感信息
尾声:元提示 LLM 作为提示优化器
Metaprompted
LLM 作为优化器
使用(元 meta)提示的 LLM 作为通用优化器:
\dots LLM 生成目标函数的新解,然后将新解及其得分添加到元提示中以进行下一步优化。
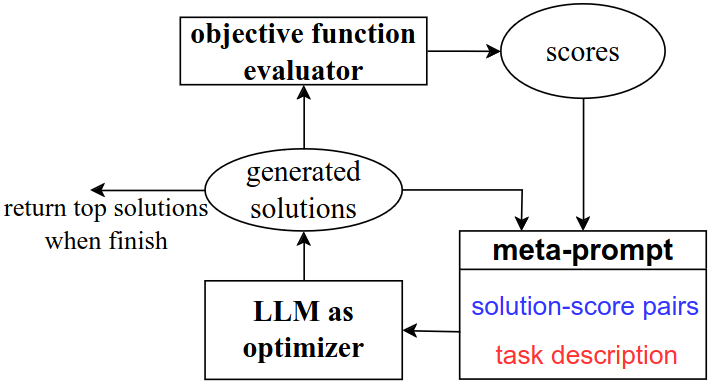
LLM 作为优化器:在提示中的应用

LLM 作为优化器:在提示中的应用 I

LLM 作为优化器:在提示中的应用 II
发现元提示优化器方法在 GSM8K 数学问题数据集上表现优于众所周知的手动提示工程方法,如“积极思考”和“链式思维”:
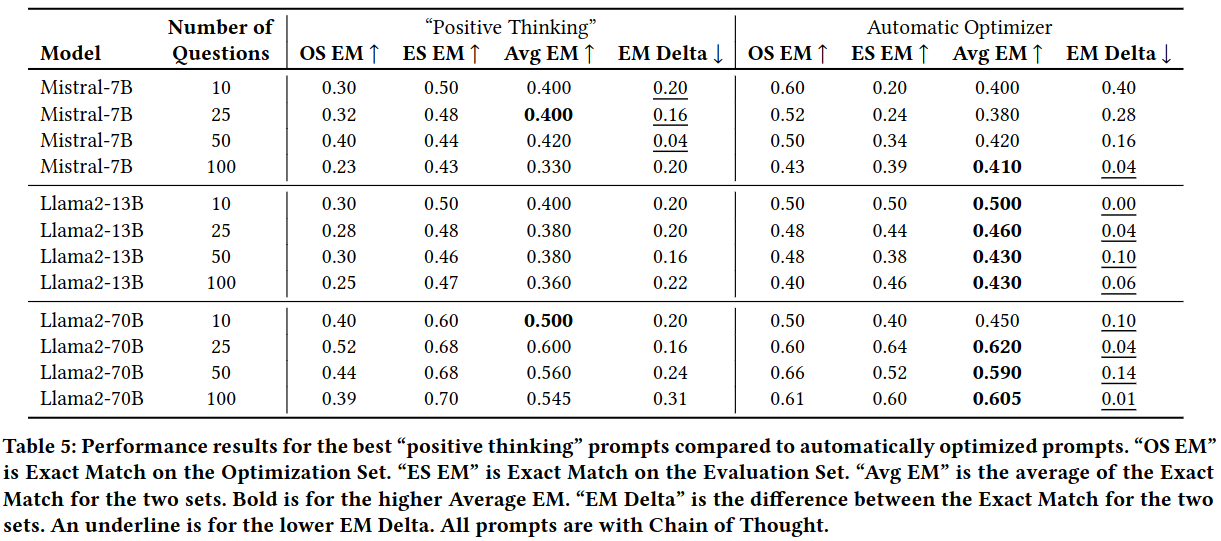
意想不到的最佳提示
此外,最佳提示通常是令人惊讶和古怪的:

NLP-Prompt