NLP-MixtureModels
混合模型
介绍
集成方法
集成机器学习方法是一组使用多个估计器并结合其结果以生成最终输出的方法。常见的方法包括袋装法、提升法、堆叠法等。这些方法背后的思想是,多个估计器的组合比单个估计器更准确。
流行的集成方法包括随机森林和梯度提升等方法。
- 袋装法(Bootstrap Aggregating)使用训练数据的不同子集来训练多个模型,然后结合它们的结果
- 提升法(Boosting)顺序地使用多个模型,每个模型都被训练来纠正前一个模型的错误
- 堆叠法(Stacking)使用多个模型生成预测,然后使用另一个模型来结合前几个模型的预测
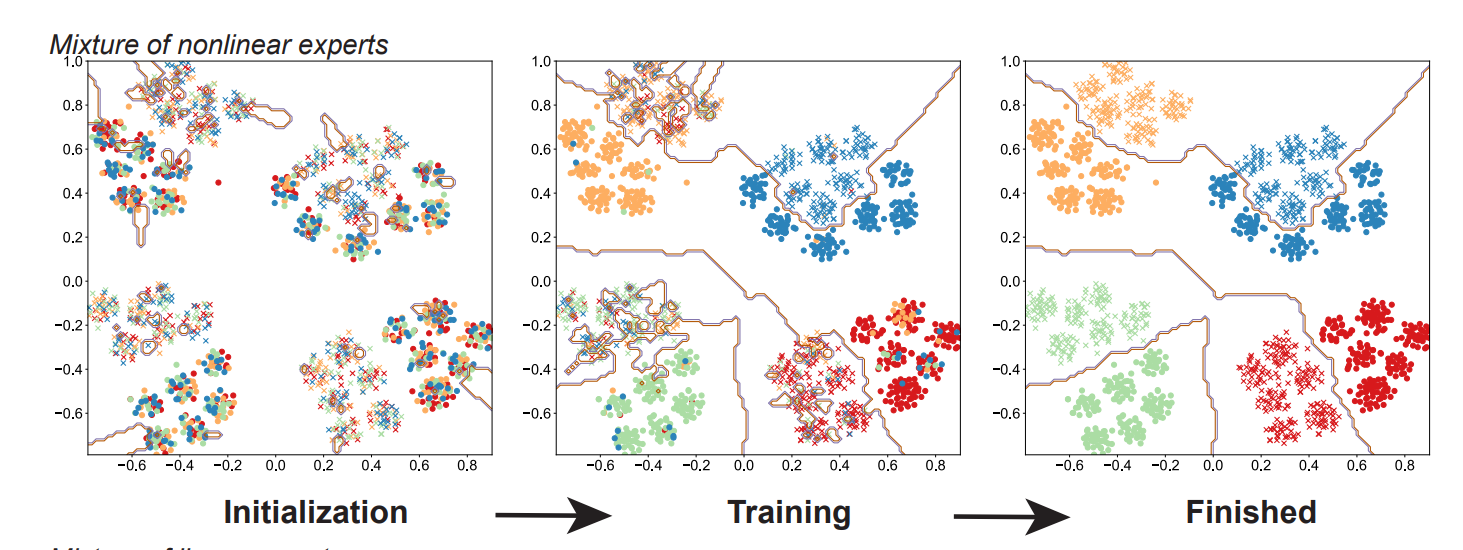
- 专家混合(Mixture of Experts)区分不同类型的输入,使用不同的模型来处理它们,然后结合所选模型的结果
专家混合(MoE)
MoE 概述
在1991年引入了专家混合(MoE)模型。该模型是混合模型的推广,其中输入用于选择用于生成输出的模型。该模型被训练来为每个输入选择最佳模型。
在原始论文中,该模型由多个前馈神经网络作为专家组成,还有一个决定每个专家被选择概率的门控网络。门控网络也是一个具有softmax激活的前馈神经网络。这里每个专家具有相同的输入,输出维度对于所有专家都是相同的,只是权重不同。
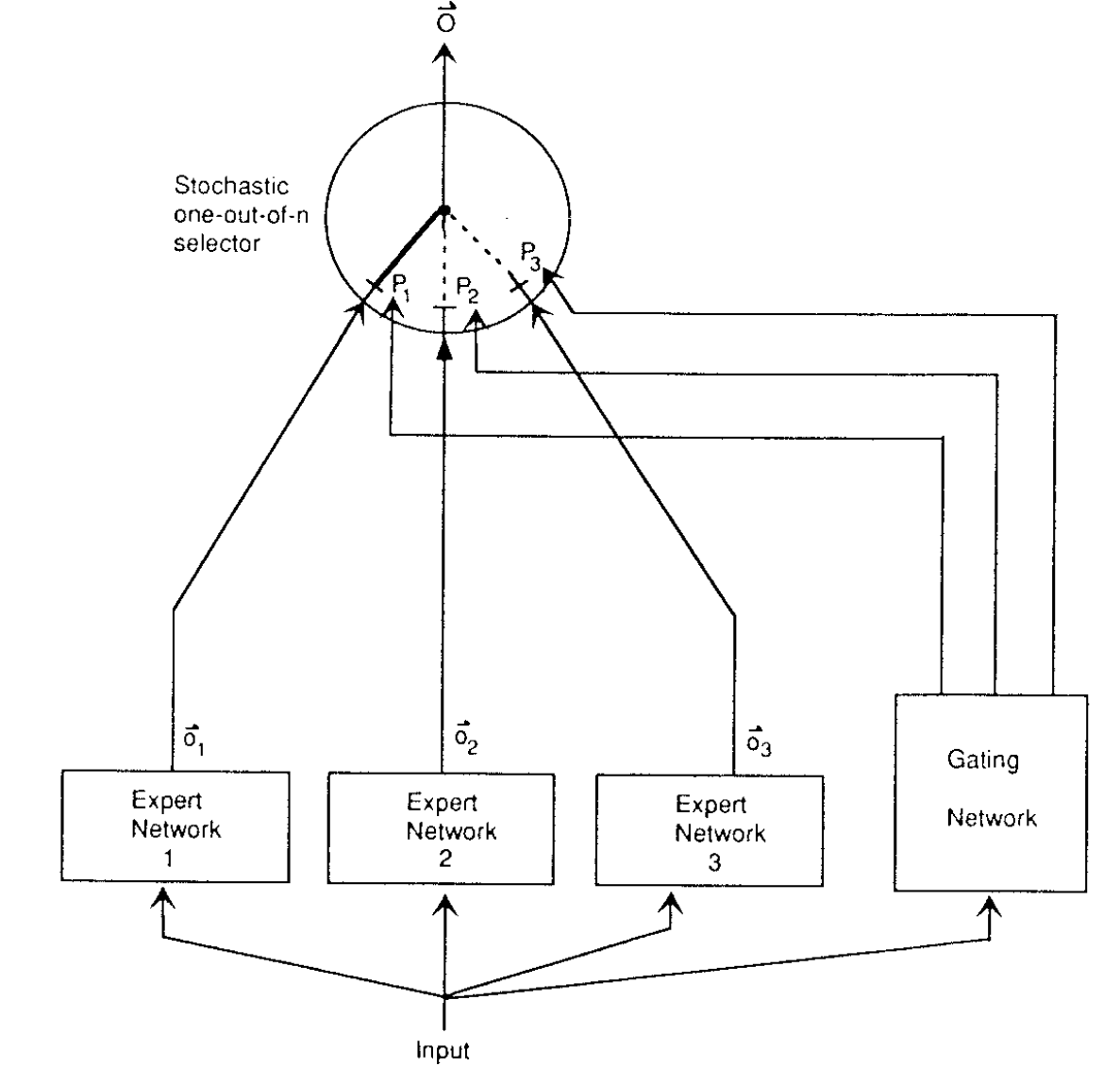
MoE 部件
MoE 模型的主要部件包括:
- 数据集划分(每个专家的输入是什么)
- 专家(每个专家的架构是什么)
- 门控网络(如何加权专家输出)
- 聚合(如何结合加权输出)
- 路由(不使用权重为零/低的专家)
- 稀疏性(如何分离专家的知识)
在深度学习模型中,稀疏性和路由可以替代数据集划分。
现代 MoE
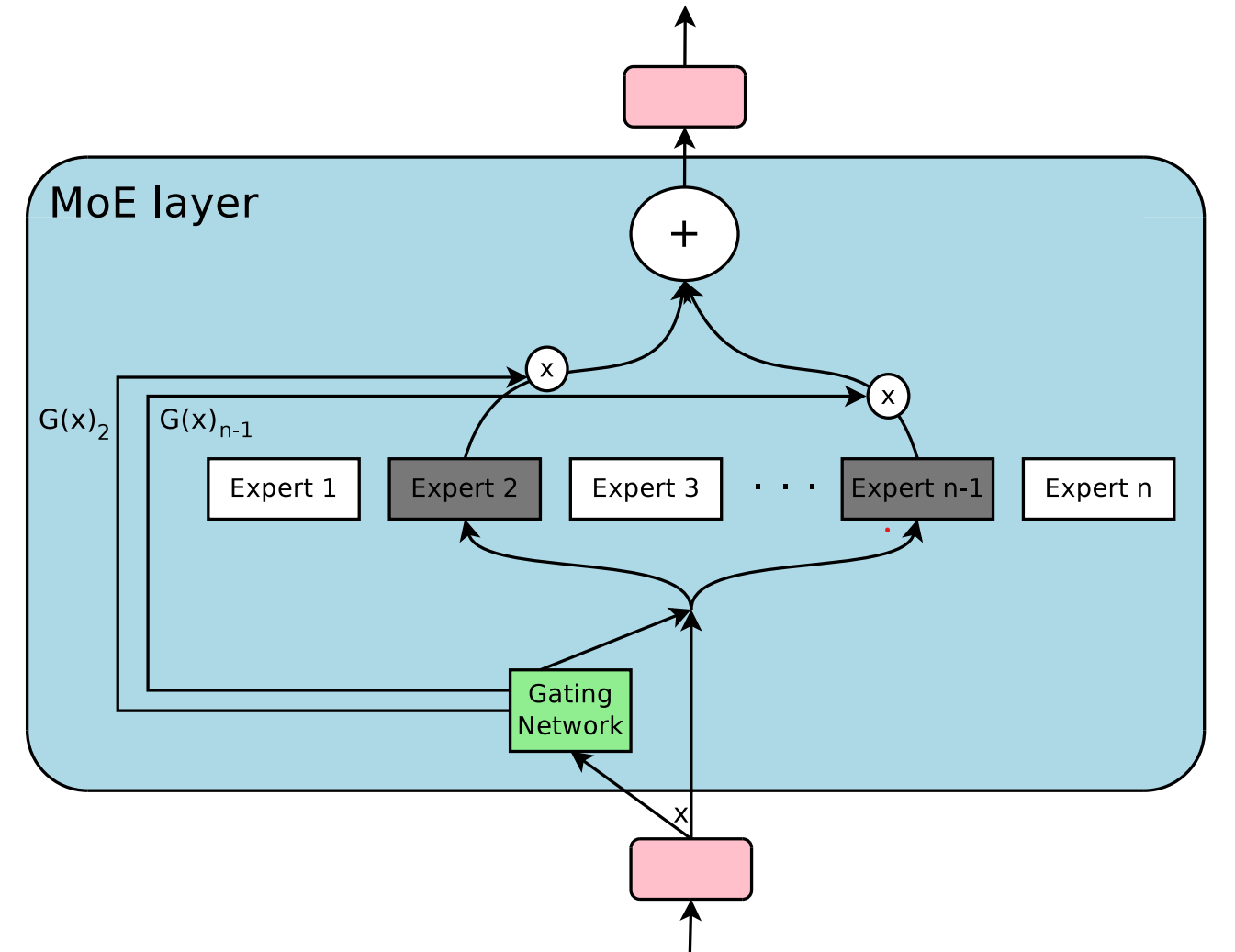
稀疏门控
引入了一种噪声-Top-K 稀疏门控程序,其中输出是专家的门控和。在使用 $n$ 个专家 ($E(.)$) 和 $G_i(.)$ 门控网络的 $x$ 输入上,输出为:
$$O(x)=\sum\limits_{i=1}^n G_i(x)E_i(x)$$
这种架构使用以下方法代替基于 softmax 的门控程序:
$$G(x)=Softmax(KeepTopK(H(x),k))$$
KeepTopK 让前 $k$ 个值的原始值通过,并将其余的值在 softmax 之前设置为 $-\infty$。
这里,$H(x)$ 是一个噪声门控值:
$$H_i(x) = (x\cdot W_g)_i + z_i \cdot Softplus((x\cdot W_N)_i)$$
其中 $z_i \sim \mathcal{N}(0,1)$ 是一个随机变量,$W_g$ 和 $W_N$ 是可调权重,softplus 是 ReLU 函数的平滑近似。
这确保了网络在每个输入时激活少量专家。问题是,如果一个专家被频繁激活,它会更频繁地被训练,因此表现会更好,从而会更频繁地被激活。这可能导致大多数输入只使用少量专家。
平衡专家利用率
为了解决专家过度使用的问题,我们可以引入一个额外的重要性损失项。这个重要性损失试图最小化每个训练批次中专家重要性的变化。
$$I_{batch}(X) = \sum\limits_{x\in X} G(x)$$
$I_{batch}(X)$ 是批次 $X$ 中输入的专家重要性之和的向量。损失与专家重要性变异(coefficient)系数成正比:
其中 $w_{importance}$ 是一个超参数,
$$CV(X) = \frac{\sigma(I_{batch}(X))}{\mu(I_{batch}(X))}$$
是变异系数。
优化和负载均衡
除了专家的均匀利用外,一些解决方案还为每个批次的负载不均衡定义了损失(负载是指分配给每个专家的输入数量)。均衡负载有利于模型的并行化。
由于大批次更有利于平衡,多GPU数据和模型并行性被使用。标准层和门控以数据并行方式复制,而专家是模型并行分片,在整个系统中每个专家子集只有一个副本。不同的子集存储在不同的GPU上,信息根据门控在GPU之间传递。
分层 MoE
还引入了一种用于语言建模的分层 MoE 模型,其中第一个路由器/门控网络激活专家集,然后该专家集像传统的 MoE 块一样工作。
快速前馈层是具有对数复杂度树状门控程序的分层 MoE 块。该树中的每一层是一个 $[dim_{in}, dim_{node_{hidden}}, 1]$ 层维度的门控网络,具有 sigmoid 激活。输出表示输入应路由到哪个子节点。叶节点是正常的、更大的前馈专家。
参数效率 + MoE
最近引入了许多使用 MoE 架构来改进适配器、前缀调优或 LoRA 的模型,以提供高效且性能优越的适应性。通常,这些 MoE 风格的适配器比密集对应物效果更好。
最近提交给 ICLR 2024 的一篇论文还引入了 MoE 层,其中每个专家都是一个 LoRA。这为使用新添加的专家扩展 MoE 模型并动态激活或停用专家提供了可能性。
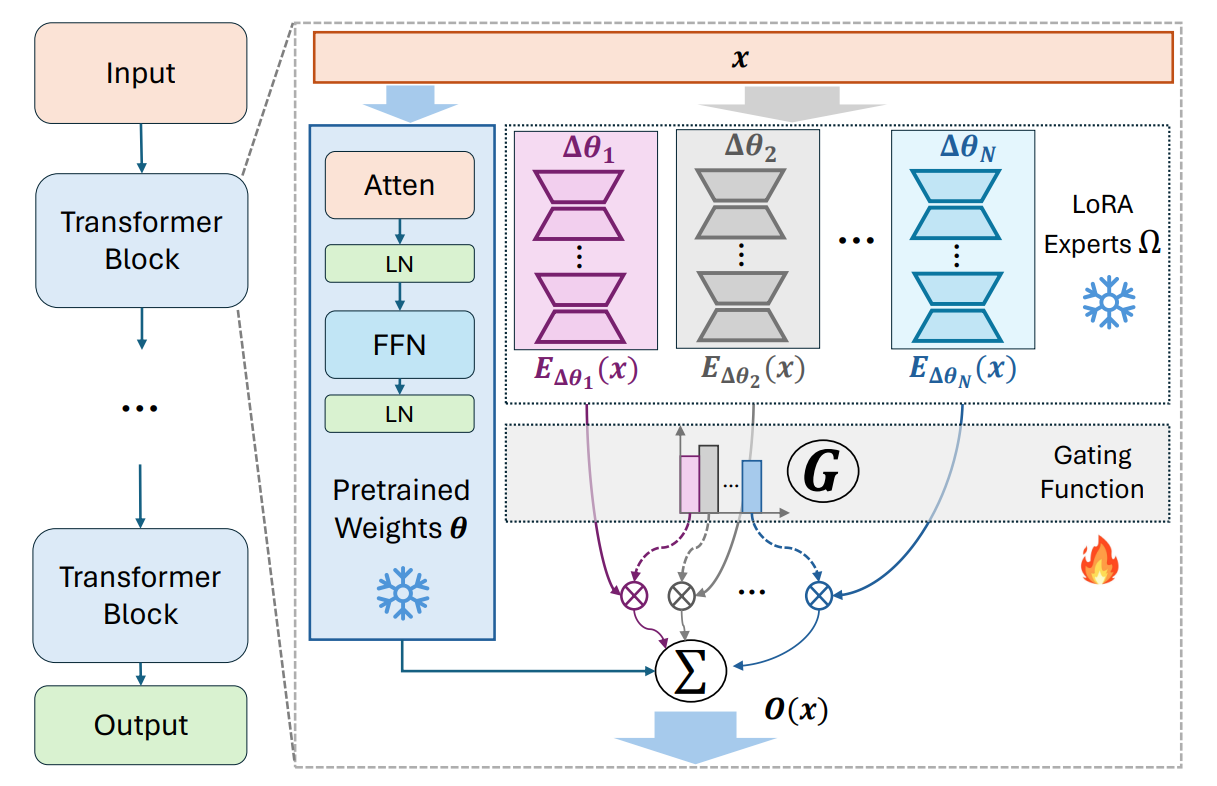
为什么它们效果很好?
仅文本 MoE
Switch Transformer
Switch Transformer 基于稀疏 MoE 的思想,但不是将每个输入路由到单个专家,而是将输入拆分并独立地将每个 token 路由到单个专家。
为了指导负载平衡,在重要性和负载损失(它们融合在一起)之上,引入了专家容量($tokens_{batch}/num_{experts}\cdot capacity_factor$),这是每个专家可以处理的 token 数量的硬限制。如果发生溢出,本应路由到专家的 token 将不被处理(但其原始值通过残差连接传递)。
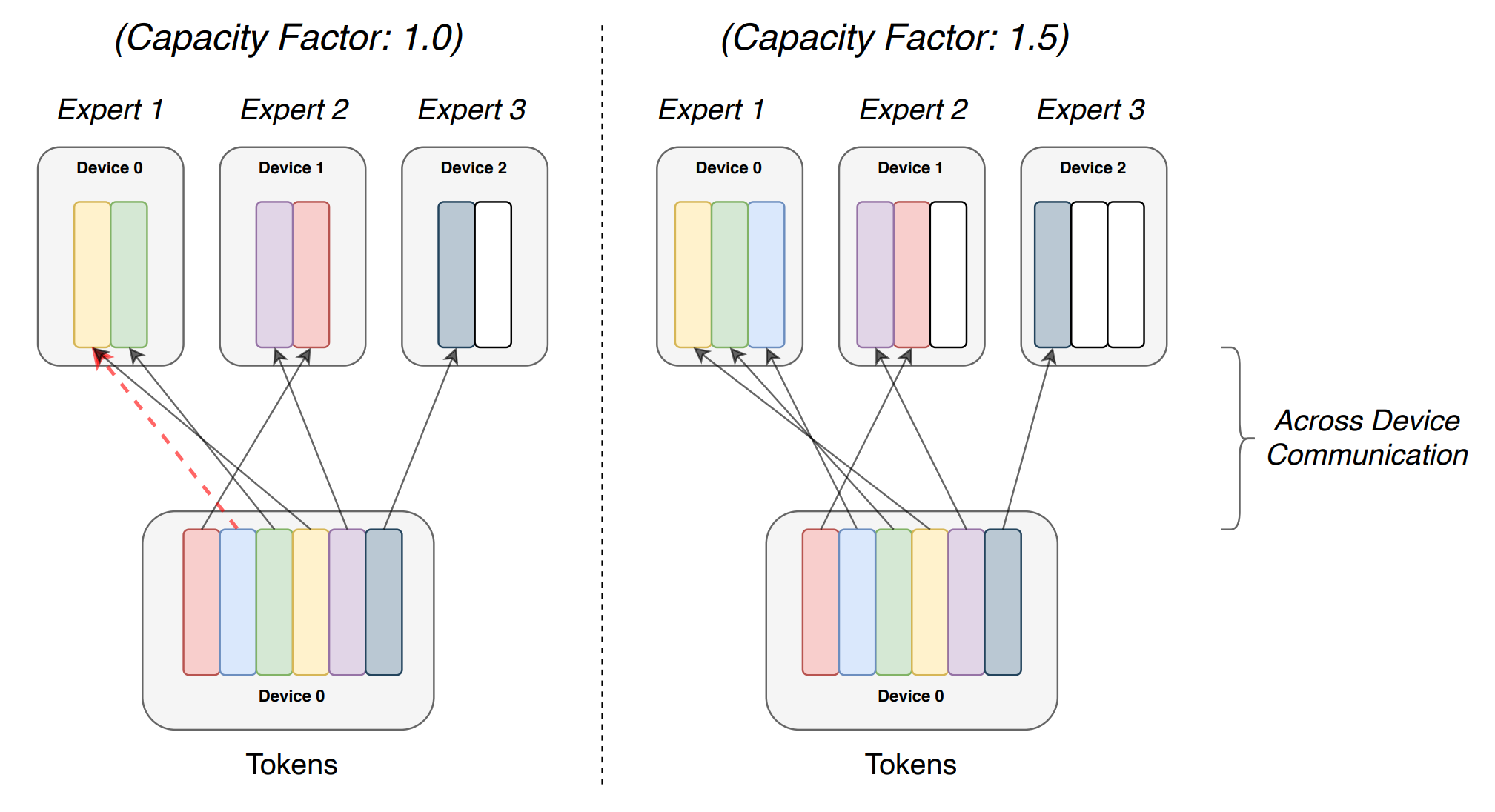
Switch Transformer 用 switch MoE 块替换 transformer 模块中的前馈层。Switch Transformer 相比传统的 MoE 和 T5 模型实现了最先进的结果。
作者还指出,特殊的权重初始化、32 位门控精度和 dropout(包括专家和其他部分)是有益的。Q、K、V 权重也可以被 MoE 模型替换,但在 16 位计算时观察到训练不稳定,详情请参阅相关文献。
在相同性能下,Switch Transformer 的训练速度比完整的 T5 模型快 2-3 倍。
UltraFastBERT
介绍了 UltraFastBERT,它是使用快速前馈层实现的 BERT。将编码器逐点前馈层中的中间层替换为单神经元专家,并在 11 层二进制决策后使用 GELU 激活函数,据报道可以达到原始 BERT 性能的 96% 以上。
训练时间也显著减少,但推理时间呈指数级加快。作者报告在朴素 GPU 实现上加速了 80 倍,在 CPU 上加速了 250 倍。
多模态 MoEs
BeiT
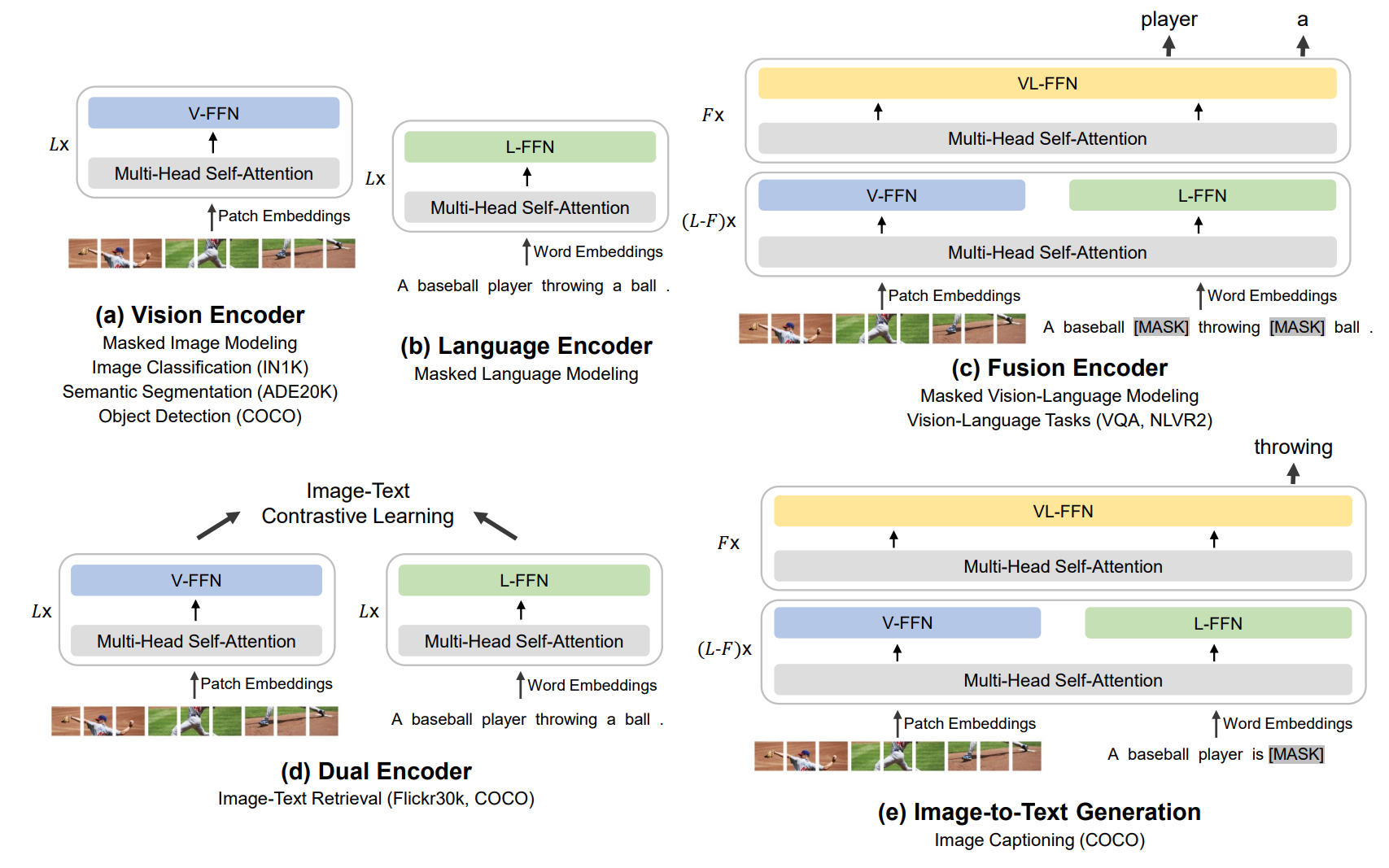
在多模态网络中,选择输入数据的“子集”是显而易见的,因为可以根据输入模态选择专家。
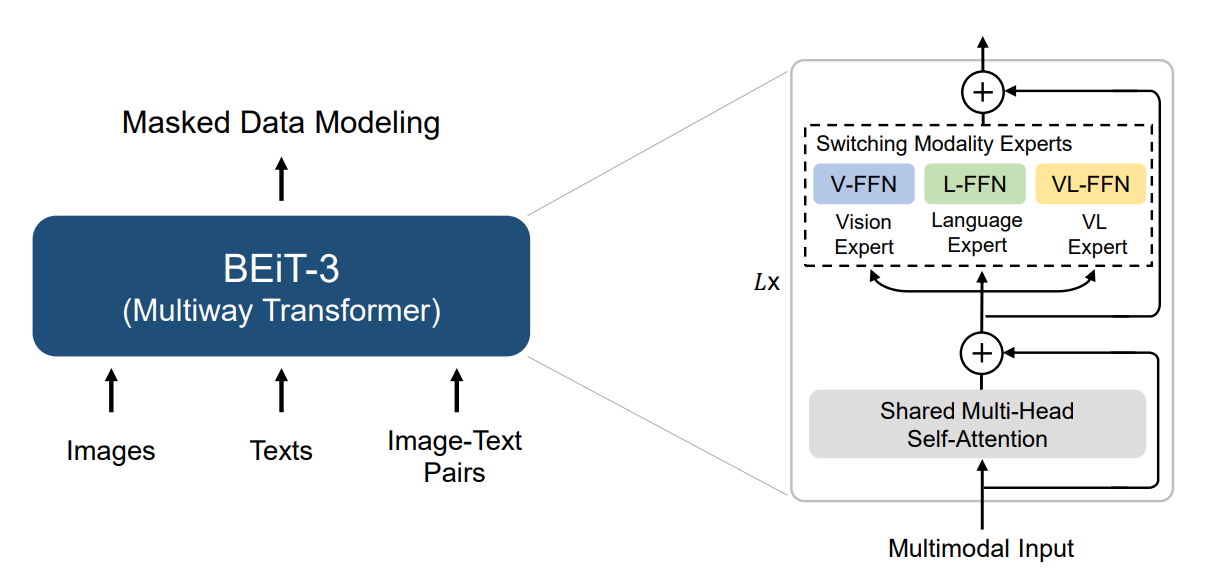
BeiT-3 以及之前的两个模型,在相同的掩码建模任务中处理图像和文本输入。
该模型通过一组视觉、语言和视觉-语言组合专家进行增强。每个输入 token 都有相应的模态信息。根据模态信息从相应的池中为每个 token 选择一个专家。
该模型在发布时在检索任务、目标检测、分割和图像分类方面达到了顶级性能。
BeiT 架构
BeiT 用例
NLP-MixtureModels