NLP-LexicalSemantics
词汇语义学
介绍
词义
正如我们在第一讲中所见,根据 组合原则,
复杂表达式的意义由其组成表达式的意义和用于组合它们的规则决定。
尽管这一原则并非没有问题,它表明要了解较大文本单元(句子、段落等)的意义,有必要了解组成它们的 词的意义。
直观地说,几个词有不止一个含义,例如,mouse 在以下句子中有不同的含义:
一只 mouse 吃了奶酪。
和
用 mouse 点击关闭按钮。
mouse 可以表示 一种小型啮齿动物 或 一种电子指点设备。识别和描述这些词义或 词义 的任务是 词汇语义学。
词典中的词义
一种描述词义的方法是通过传统的词典。
例如,在线版的牛津高阶英汉双解词典 描述了这些词义,如下所示:
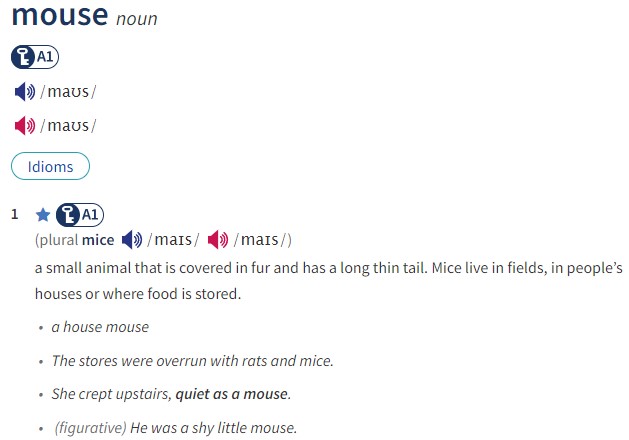

这些词义描述的显著特点是:
词义有精确的标识符:表面形式 mouse,词性标签 noun 和词义编号共同明确地标识了这些词义;
每个词义都有一个文本定义,虽然不是形式化的,但
- 使用相对较小的定义词汇
- 遵循某些惯例,例如,以一个更一般的词加上特征属性开始(小动物,小设备)
有几个例句,展示了该词义使用的典型模式。
关系语义学
词汇关系
词典可能包含有关词义之间的词汇关系的信息,特别是关于
- 同义关系:synonymy,两个词义是否(几乎)相同
- 反义关系:antonimy,两个词义是否彼此相反
其他重要的词汇关系包括分类关系(taxonomical):
- 如果词义 $s_1$ 更具体,则 $s_1$ 是 $s_2$ 的下位词(hyponym),例如,$mouse_1$ 是 $animal_1$ 的下位词
- 相反,如果 $s_2$ 比 $s_1$ 更具体,则 $s_1$ 是 $s_2$ 的上位词(hypernym)
最后,部分-整体关系,即部分关系(meronymy):例如,finger 是 hand 的部分关系。
总体而言,词义及其词汇关系构成了一个网络,其中
- 节点是同义词集,且
- 边是词汇关系。
由于下位词关系(也称为 is_a)是传递的,因此在网络中仅保留直接下位词边是有意义的,即仅当不存在节点 $s_3$ 使得 $s_1 \xrightarrow{is_a} s_3$ 且 $s_3 \xrightarrow{is_a} s_2$ 时,才有 $s_1 \xrightarrow{is_a} s_2$ 边。
WordNet
为了在 NLP 中可用,词汇语义信息必须作为具有明确查询 API 的计算资源可访问,并且从 1980 年代中期开始,许多项目开发了此类资源。
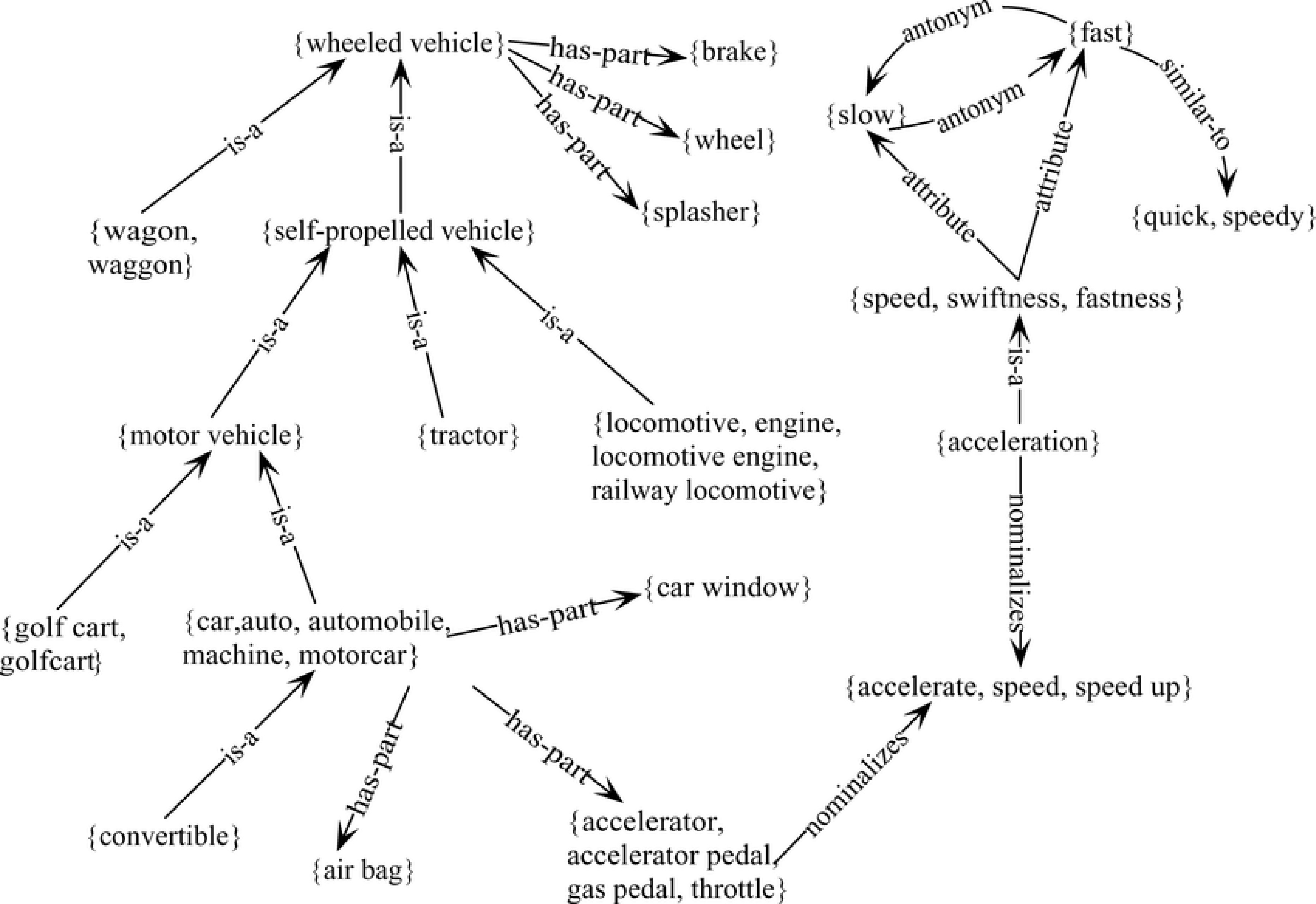
最重要的是WordNet 英语词汇数据库,它包含大量带有定义、示例和词汇关系的同义词集。在其成功之后,许多其他语言也开发了 WordNet,现在已有超过 200 个 WordNet 可用。
英语 WordNet 网络的一部分:
知识库作为词汇资源
除了专门的词汇数据库外,知识库 也可以作为有用的词汇语义资源,因为它们包含有关 实体 和 概念 的信息,这些信息可以链接到词汇中的单词。重要的例子包括:
维基,最重要的是英文维基百科,这里各种类型的链接和引用在条目之间提供了关系信息
形式本体:这些以形式逻辑语言描述概念之间的关系
注意:词典编纂者区分词汇、概念和百科知识;后者不被认为是单词语义的一部分。
词义消歧
为了使用这些词汇资源提供的词义信息,NLP 应用程序必须能够确定输入中使用的单词的意义,即执行 词义消歧 (word sense disambiguation)。WSD 任务的细节取决于它基于哪个词汇资源以及如何使用该资源。给定一个包含词义的资源,
监督 WSD 使用在标注了正确词义的训练数据上的机器学习方法;而
基于知识的 WSD 利用词汇资源中的信息,例如 WordNet 中的词汇关系和定义
潜在语义分析
Latent Semantic Analysis
基于向量的词汇语义学
我们迄今为止看到的词汇语义学方法具有某些特征,使得它难以实现大范围覆盖并适应新的语言或领域:
- 词汇数据库是由高素质专家手工组装的
- 高性能的词义消歧模块的开发通常需要大量专家标注的训练数据
这些问题导致了对替代方法的研究,这些方法以无监督的方式分配有用的词义表示,简单地从文本语料库中学习它们。
尽管曾尝试从文本语料库中学习语义网络,但第一个成功的无监督词汇语义方法是从文本语料库中学习词向量,即形式为
$$E: V \rightarrow \mathbb{R}^d$$
的嵌入函数,它将 $V$ 词汇表中的每个词分配到 $d$ 维($d\in \mathbb N$)向量。当然,并非任何这样的函数都可以:显而易见的要求是,学习到的向量必须传达关于它们所分配词的意义的有用信息。
确保这种联系的一种方法是利用分布假设(distributional hypothesis):
- “通过一个词的同伴,你将了解这个词。”
- “具有相似分布的语言项目具有相似的意义。”
这表明,如果词向量反映了它们所分配词的分布,那么它们也将反映这些词的意义。
共现矩阵
获取反映语料库中单词分布的词向量的最直接方法是考虑共现(Co-occurrence)矩阵。如果语料库中有 $D$ 个文档,$V$ 是语料库词汇表,那么
term-document 矩阵是 $|V|\times D$ 维矩阵,其中每一行是一个词向量,其第 $i$ 个元素是该词在第 $i$ 个文档中的出现次数,而
词-词 矩阵是 $|V|\times |V|$ 维矩阵,其中每一行是一个词向量,其第 $i$ 个元素是该词与第 $i$ 个其他词的共现次数。
直接使用这些向量的一个重要问题是它们的巨大维度和稀疏性。为了解决这个问题,潜在语义分析 方法应用降维矩阵分解方法,通常是截断奇异值分解(truncated singular value decomposition),以找到原始 $C$ 共现矩阵的低秩近似(low-rank approximation)。使用 SVD 的分解是
$$C \approx USV^\intercal$$
其中 $U,V$ 是正交矩阵(orthonormal),$S$ 是对角矩阵(diagonal)。在截断 SVD 的情况下,$U$ 矩阵的行可以用作基于共现的原始词向量的低维近似表示。
NLP-LexicalSemantics