NLP-DialogSystems
Chatbot
介绍
对话系统
它们通过进行对话与用户交流
对话的形式可以是
- 口语
- 书面(文本)
- 混合:除了语音和/或文本对话外,还可以包含带有按钮的对话框等GUI元素
典型的环境包括
- 消息平台(例如,Slack和Facebook Messenger)
- 智能手机助手(Siri,Cortana等)
- 智能音箱(例如,Alexa)
- 汽车(例如,Google Android Auto)
对话系统的类型
通常区分 任务导向 (task-oriented)和 开放域 (open domain)对话系统(后者也称为 聊天机器人)。
任务导向对话系统:目标是在预定义的任务集中完成一个或多个任务,例如,订购某物、打电话、转账、获取路线等
开放域对话系统:
- 目标是开放式和非结构化的扩展对话
- 没有预定的任务(或任务集)作为目标
- 在许多情况下,主要结果只是“娱乐”
- 可以作为主要任务导向系统的附加组件
另一种重要的分类是根据谁发起和控制对话。对话可以是
用户发起:例如,手机助手。对话通常非常简短,例如,用户问题和系统回答使用手机助手
系统控制:变体包括
- 系统发起并控制,例如通过警告或提醒用户某事
- 用户通过请求指示发起,从那里系统指示而无需用户的基本输入
- 用户通过请求服务发起,从那里系统通过提问帮助用户“填写问卷”
混合主动性:有几个回合,系统和用户都可以主动(initiative) — 这些通常是开放域对话系统
一般对话需求
系统需要能够再现人类之间对话的重要特征,包括但不限于:
语境建立
Grounding,通过说话者不断确认理解对方所说内容,建立一个不断演变的 共同语境(common ground)。
说话者
- 引入 新的信息
- 确认 添加的信息(通过手势或口头确认)
- 如果需要,请求澄清
邻接对
Adjacency pairs,话语类型与响应期望相关联:
问题 $\Rightarrow$ 答案
提议 $\Rightarrow$ 接受
赞美 $\Rightarrow$ 降低 等
question $\Rightarrow$ answer
proposal $\Rightarrow$ acceptance
compliment $\Rightarrow$ downplayer etc.
语用推理
Pragmatic inferences,我们通过假设话语(utterances)是
- 相关的
- 信息丰富的
- 真实的
- 清晰简洁的(或者至少说话者的目标是这样)来推断说话者的意思
开放域对话系统
方法
基于规则
传统上,基于规则的“模式匹配和替换”类型系统被使用,著名的有
- Eliza (1966),模拟罗杰斯心理学家
- PARRY (1971),用于研究精神分裂症
基于语料库
更现代的替代方法当然是构建一个基于语料库(Corpus)的系统,该系统在包含大量对话的数据集上进行训练。
基于语料库的方法
检索(retrieval)响应:使用数据集中
- 与最后一轮最相似的发言
- 是与最后一轮最相似的发言的响应的发言
- 相似性可以是完全预训练的,或基于 训练/微调 的嵌入
生成响应:在数据集上训练一个生成模型,典型的架构包括:
- 基于RNN或Transformer的编码器-解码器
- 一个微调的“预测下一个”语言模型,例如GPT类架构。我们将在下一讲中讨论这种替代方法
任务导向对话系统
Task-oriented dialog systems
框架
大多数任务导向对话系统(TODs)基于(某种变体的)框架,即用户意图的结构化表示,包含可以用 值 填充的 slots。槽值可以是另一个框架。


基于框架的TOD系统会提出问题,帮助填充框架槽,直到填满当前目标任务所需的所有槽,然后执行任务。

早期基于框架的架构
早期基于框架的任务导向对话系统(TODs)具有以下组件:
控制结构:一个生产规则系统,控制如何操作槽值以及根据实际状态和用户输入提出哪些问题
自然语言理解(NLU):一个基于规则的NLP模块,确定话语的domain(一般主题)、意图(intent,具体目标)和槽 和 填充值
自然语言生成(NLG)模块:一个基于模板的系统,用于生成适当的系统问题给用户
可选的自动语音识别(ASR)模块,通常基于任务特定的词汇和 语法/语言 模型
Natural language generation
Natural language understanding
NLU 任务是确定每个用户话语的领域、意图和槽填充。例如,对于
Show me morning flights from Boston to San Francisco on Tuesday
我们希望得到如下分析:
| DOMAIN | AIR-TRAVEL |
|---|---|
| INTENT | SHOW-FLIGHTS |
| ORIGIN-CITY | Boston |
| ORIGIN-DATE | Tuesday |
| ORIGIN-TIME | morning |
| DEST-CITY | San Francisco |
对话状态系统
现代、更复杂的基于框架的TODs方法的化身是 Dialog-state systems 架构。
与早期系统相比,主要区别在于
将 控制 分解为两个独立的模块:
对话状态跟踪器(也称为 belief state tracker),根据对话历史计算当前更新的对话状态(用户目标,即填充的槽值等)
对话策略,根据实际状态确定下一个系统动作
在所有模块中广泛使用 机器学习方法,而不是早期系统的基于规则的方法
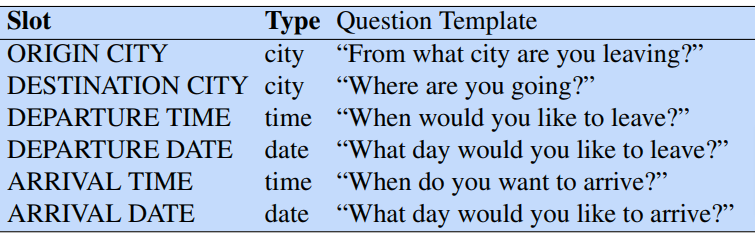
基于语音的系统的完整架构:
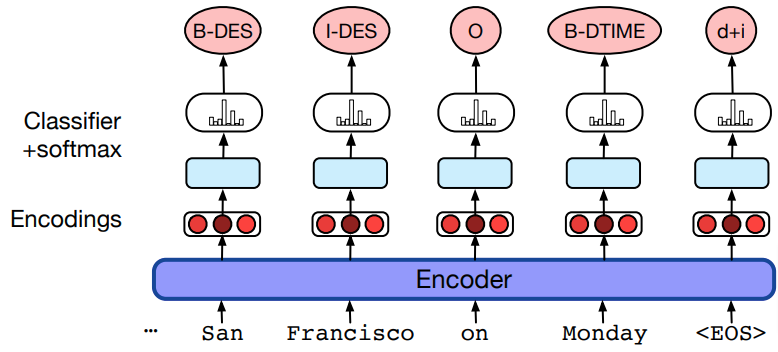
实现NLU组件
识别用户话语中的领域、意图和槽值/实体可以通过分类器和序列标注模型来实现:
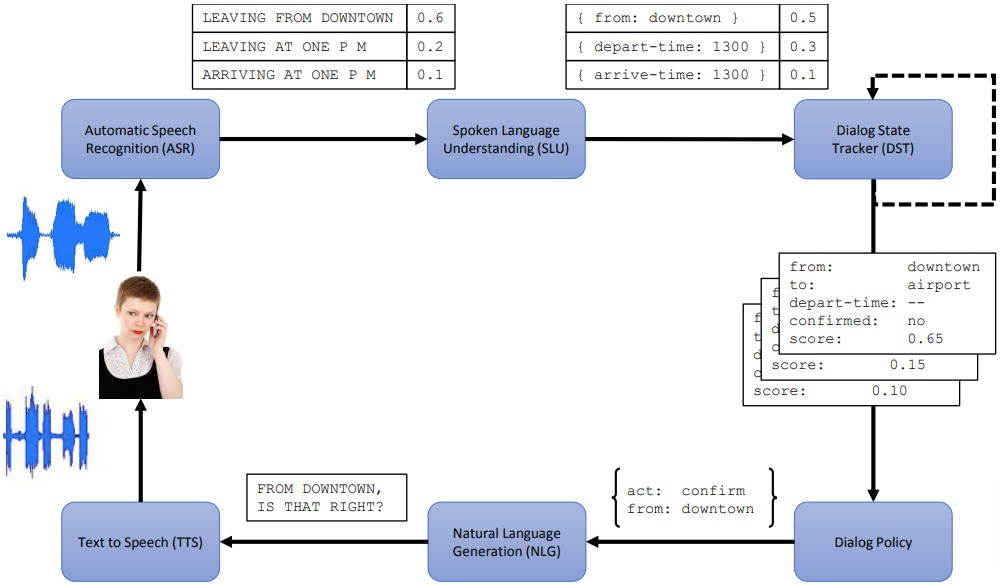
对话状态跟踪
基于NLU的(N-best)输出 和/或 对话历史,跟踪器确定发生的对话行为,以及当前(更新的)对话状态。这可以通过生成一组候选状态并对其进行评分来实现:
![]()
评分器可以基于像BERT这样的预训练编码器:
![]()
除了对完整的对话状态进行评分,还可以单独对(槽,值)对进行评分:
![]()
NLU
如前两个示例中所示,现代对话状态跟踪器经常直接使用用户话语作为输入,而不需要在对话架构中独立的NLU组件
基于机器学习的NLU和对话状态跟踪模块的对话系统通常通过首先开发一个基于规则的系统来启动,并使用它来生成一个“银”标注的数据集(当然,验证数据集仍然是完全手动标注的。)
对话策略
Dialog policy 决定系统接下来应该采取的行动,基于对话状态和可能的对话历史的其他元素。最重要的行动类型是 系统对话行为(例如,提问、确认请求等)、查询数据库 和外部 API 调用。
对话策略通常可以实现为一个分类器,因为通常有一个有限(且通常较小)的可能行动集合可供选择。策略模块可以实现为
- 基于规则 的系统
- 使用 监督学习 的机器学习模型
- 使用 强化学习 优化的机器学习模型(可能在监督预训练之后)
NLG
最后,当所需的行动是一种系统话语时,NLG 组件根据具体的行动、对话状态和(可选的)对话历史生成实际的句子。
NLG 任务通常分解为
话语规划:规划话语的内容(应提到哪些槽/值,可能还有它们的顺序和分组)
话语实现:实际生成计划内容的自然语言表达

简化生成任务和缓解数据稀疏性的一种广泛使用的策略是生成 去词化模板,其中包含槽值的占位符,然后用所需的槽值替换它们。

话语或其模板的生成可以实现为基于规则的系统或机器学习模型;最近的实现通常使用 序列到序列模型:
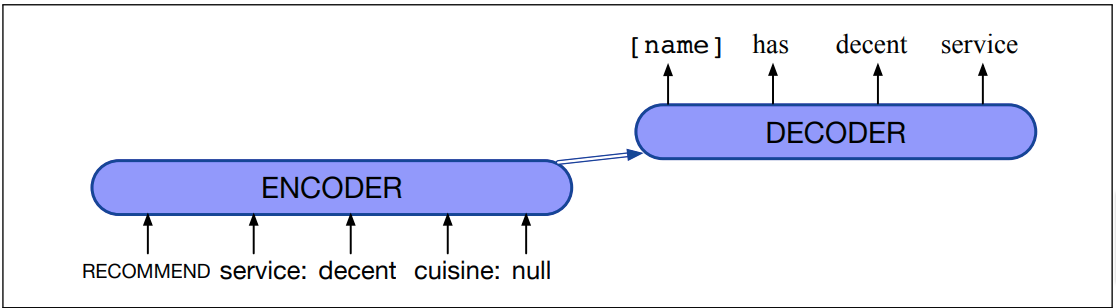
简化的架构和模型
广泛使用的seq2seq模型用于实现独立的对话状态系统模块,以及在单独训练的模块之间的错误传播,导致了提出训练一个(基于预训练语言模型的)单一多任务seq2seq模型,SimpleTOD,同时用于
- 对话(信念)状态跟踪
- 对话策略
- 自然语言生成(NLG)
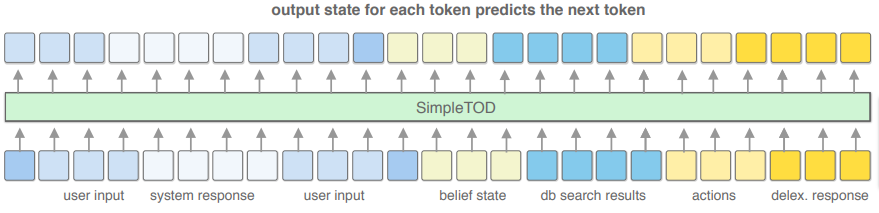
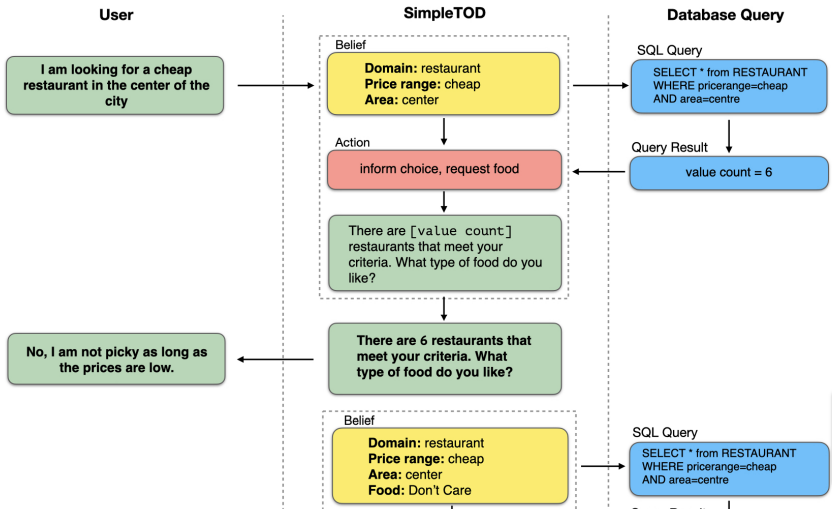
当然,类似SimpleTOD的方法仍然需要一个带有对话动作和对话状态标注的数据集进行训练,并且需要关于领域意图和 实体类型/槽 的通用信息。因此,为具体任务或任务训练的模型不能用于其他任务,除非重新训练。
一个有趣的研究领域是训练完全通用的任务导向对话模型,这些模型明确地以任务导向对话描述为条件,即所谓的 对话模式图 (dialog schema graphs)。
对话模式图
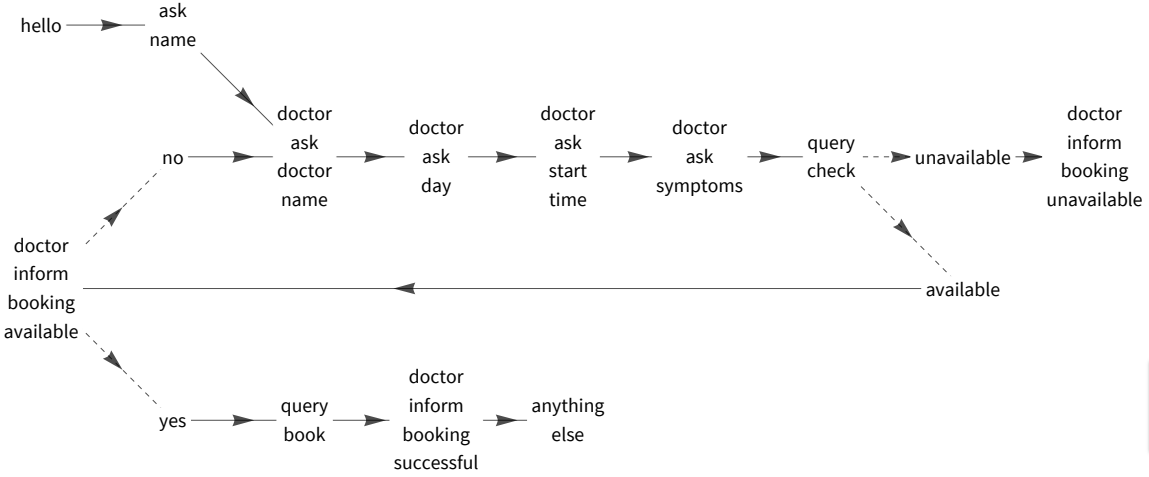
基于模式的任务导向对话数据集
有几个基于模式的任务导向对话数据集可用,这些数据集除了包含注释对话外,还包含模式图:
- STAR 数据集包含 13 个领域中的 5,820 个任务导向对话,共 127,833 个话语
- SGD Schema-Guided Dialog 数据集包含 20,000 个对话
- SGD-X 数据集“通过为每个模式扩展 5 个众包变体来扩展 SGD 数据集,这些变体在语义上相似但风格上多样”
评估
评估开放域对话系统
基于某种类型的距离与预定义的正确行为的度量不起作用,因为在任何给定回合中正确响应的集合太大。相反,人类 参与者 (participants)或 观察者 (observers)根据各种质量方面评估系统产生的对话行为,例如:
- 对话有多 吸引人
- 话语是否 像人类
- 响应在上下文中是否 有意义
- 是否 流畅
- 是否避免 重复
评估任务导向对话系统
一个核心指标是 绝对任务成功率:根据用户的意图,多少百分比的对话导致任务成功执行。
对于基于槽的系统,还可以测量 槽错误率:系统正确填充的槽的百分比。
除了这些与成功相关的指标外,用户评估中的 用户满意度 和 总体对话质量 也非常有用。(细粒度指标可以测量类似于开放域系统的方面。)
NLP-DialogSystems