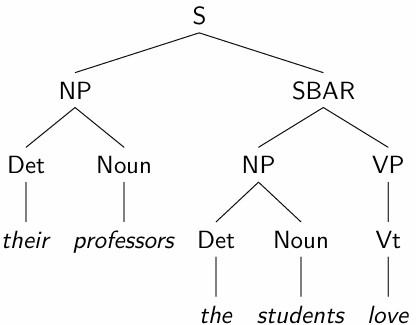
NLP-DependencyParsing
依赖关系解析
依存解析任务
句法解析
(复习)Syntactic theories 旨在描述
“支配单词如何组合成短语、形成良构单词序列的规则或原则。”
在这种情况下,最重要的“良构序列”是句子:给定语言的句法理论的核心目标是找到 characterize/delineate 该语言良构句子的结构规则或原则。
如果一个句子具有满足所讨论理论的句法约束的结构描述或句法解析,那么它就是良构的。句法上的良构性并不保证连贯性或有意义。引用乔姆斯基的著名例子:
Colorless green ideas sleep furiously.
在句法上是良构的但无意义,而
Furiously sleep ideas green colorless.
甚至不是良构的。
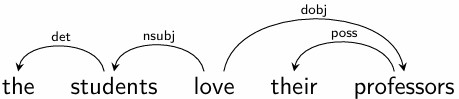
依存语法
(复习)Dependency grammars 将单词之间的依存关系视为基本关系。
具体标准因理论而异,但通常在一个句子中,如果一个 $d$ 单词依赖于一个 $h$ 单词(等价地,$h$ 支配 $d$),则
$d$ 修饰 $h$ 的意义,使其更具体,例如 eats $\Rightarrow$ eats bread, eats slowly 等
并且它们之间存在不对称的可省略关系:可以从句子中省略 $d$ 而保留 $h$,反之则不行
依存语法对一个良构句子中的依存关系施加了重要的全局约束,例如,
恰好有一个独立的单词(句子的根)。
所有其他单词直接依赖于一个单词。
由于这些约束的结果,句子的直接依存图是一个树。
大多数依存语法使用typed direct dependencies:存在有限的直接依存类型列表,并对它们何时可以成立施加特定约束。
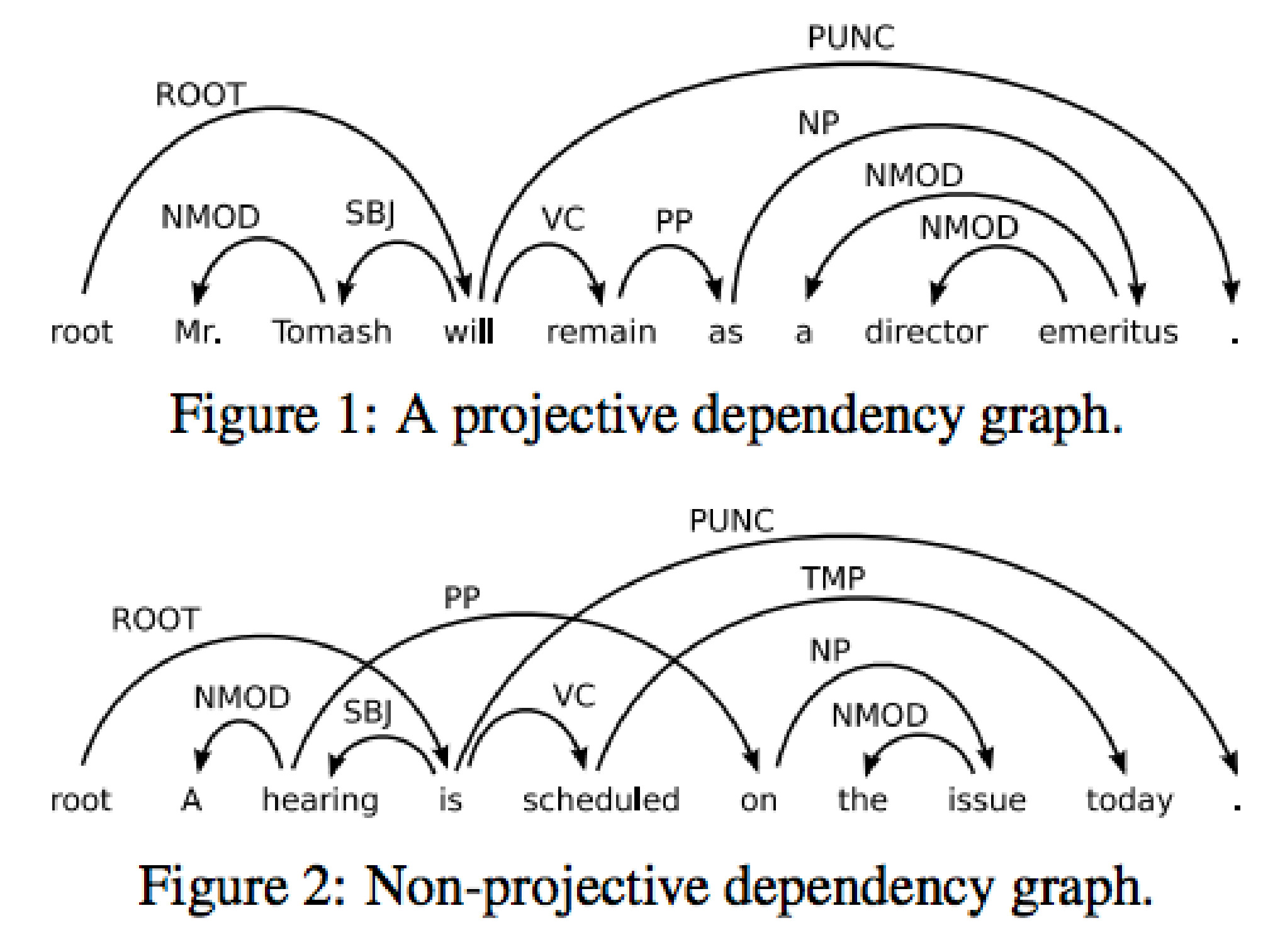
投射性
依存解析树的一个重要(但并非总是满足)要求是projectivity:
如果一个 $w$ 单词直接依赖于 $h$,并且一个 $w’$ 单词在句子的词序中位于它们之间,那么这个 $w’$ 的支配词要么是 $w$,要么是 $h$,或者是位于它们之间的另一个单词。
更不正式地说,投射性条件表明依存关系是嵌套的,单词之间不能有交叉依存关系。
依存语法的优势
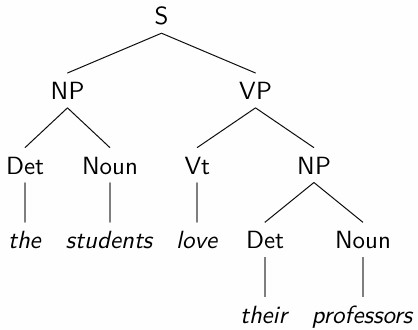
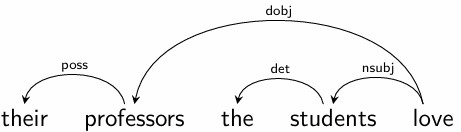
依存语法已成为 NLP 中使用的主要句法理论,因为
依存树在许多方面比短语结构解析树更简单的结构(例如,每个单词只有一个节点);
依存图提供的句子谓词-论元分析是事件或框架导向语义分析的一个很好的起点。
Universal Dependencies (UD) 框架已被创建,以促进不同语言之间的一致 annotation。
语义表示的可用性
比较事件语义方面
依存解析
给定一个句法理论(syntactic theory),解析任务是为输入句子分配满足该理论 constraints/conditions 的句法结构。对于依存语法,这意味着分配一个依存结构:
识别句子中单词之间的直接依存关系
以这样的方式使它们共同构成一个满足所有理论约束的依存树
在现代 NLP 实践中,解析任务所依据的依存语法通常是隐式指定的,使用所谓的树库,即由带有解析树注释的句子组成的数据集。
这使得解析成为一个结构化的监督学习任务:给定一个由大量 $\langle \mathrm{sentence}, \mathrm{parse} \space \mathrm{tree} \rangle$ 对组成的训练集,学习预测未见句子的解析树。
性能指标
对于依存语法解析器,最常用的评估指标是
UAS:Unlabeled Attachment Score(无标签依存准确率)正确依附于正确支配词的单词百分比
LAS:Labeled Attachment Score(有标签依存准确率)正确依附于正确支配词并具有正确依存标签的单词百分比
解析算法
像大多数序列标注方法一样,依存解析算法使用将预测任务分解为结构元素的单个决策的策略。在这种情况下,
单个决策是关于单词之间的个体依存关系
主要问题是确保这些单个决策能形成一个连贯的依存树
依存解析器通常使用
transition-based,或
graph-based的方法
基于转换的解析
该算法基于一个解析过程的形式模型,该模型从左到右移动要解析的句子,并在每一步选择以下操作之一:
将当前单词分配为某个先前看到的单词的中心词(head)
将某个先前看到的单词分配为当前单词的中心词
或者推迟对当前单词的任何处理,将其添加到存储中以供以后处理
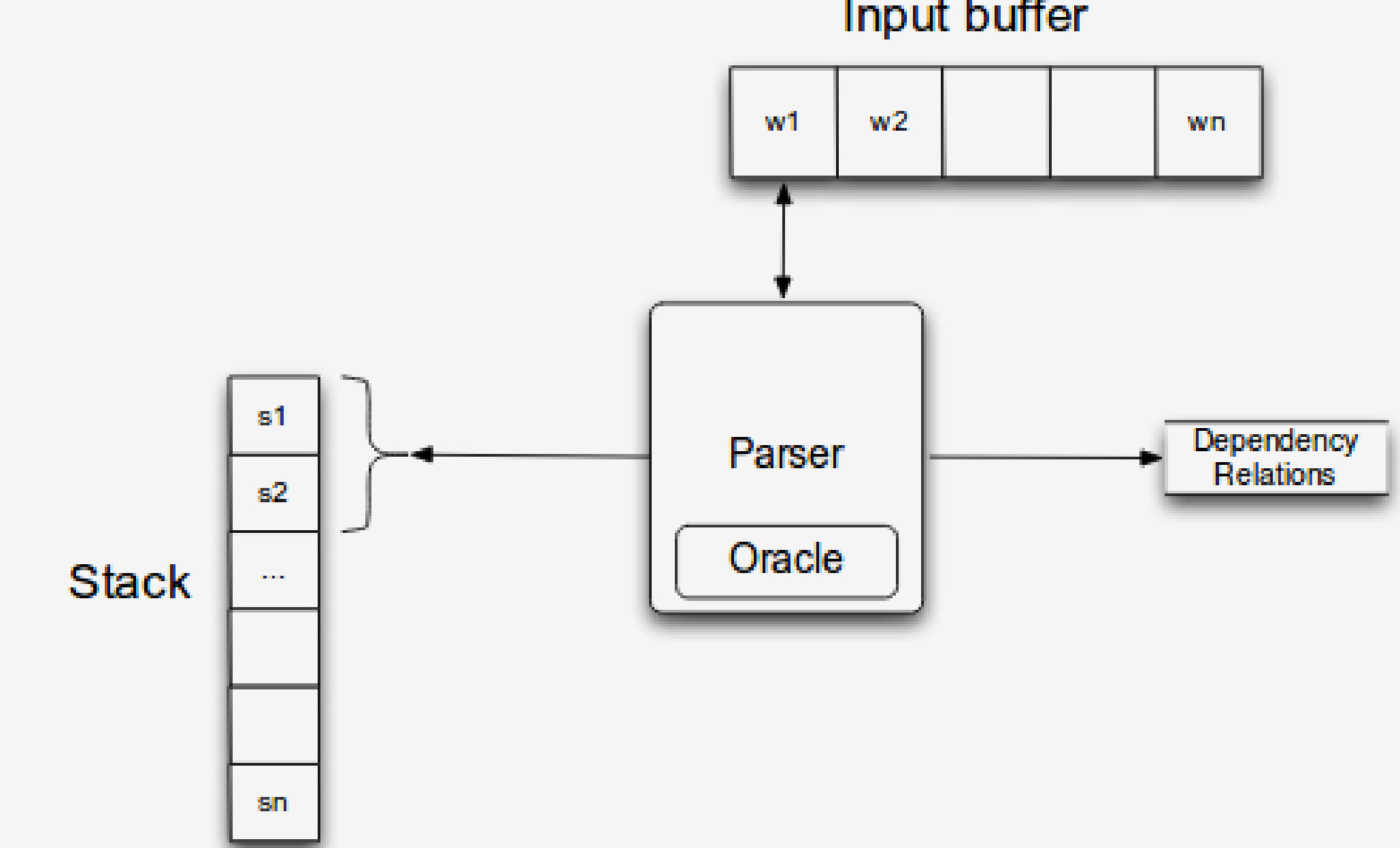
该过程的形式模型由以下组件组成:
一个缓冲区,其中包含未处理的输入标记
一个堆栈,包含当前操作的标记并存储推迟的元素
一个依存图,用于为输入句子构建
模型配置
在过程的每一步,模型处于某种配置中:
初始配置
解析过程从特殊的初始配置开始,其中
缓冲区包含输入的所有单词
堆栈包含依存图的单个根节点
并且依存图是空的(不包含任何依存边)
解析过程
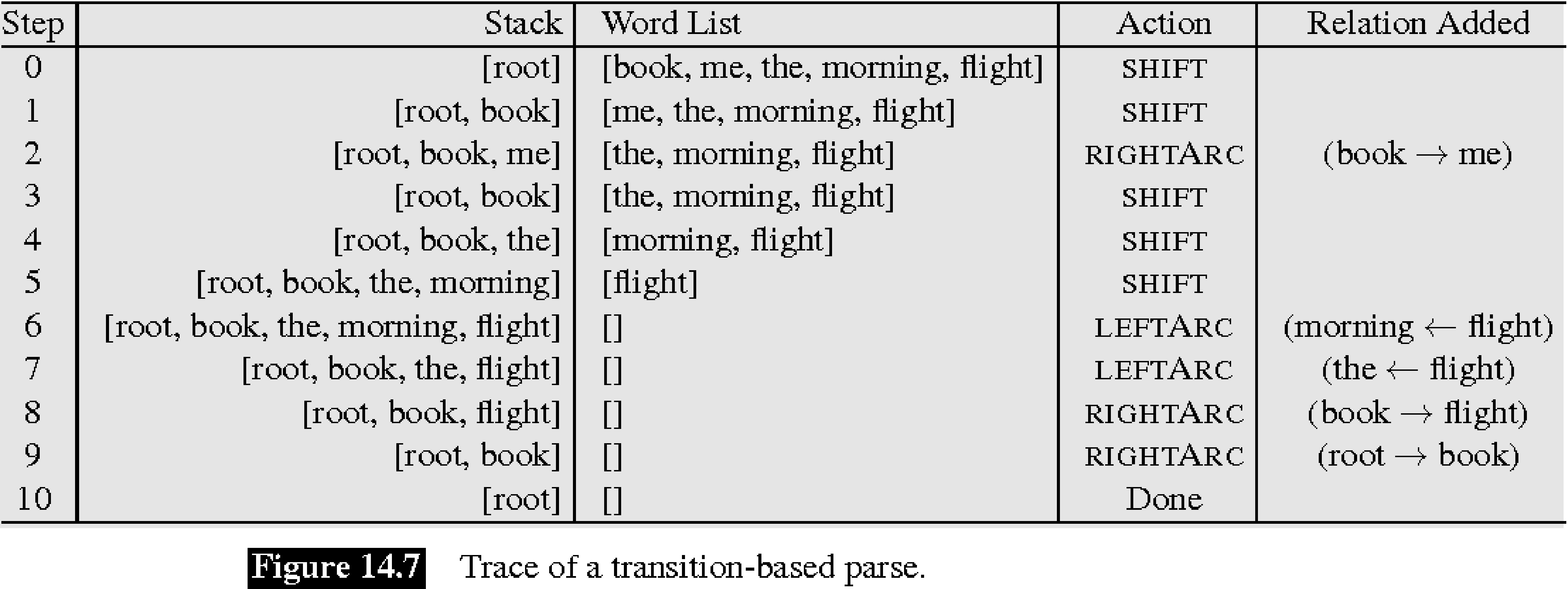
在每一步,都会执行一个允许的配置操作(配置转换)。允许的操作有所不同;在所谓的 arc standard 方法中使用了一组非常简单的操作:
带标签 $l$ 的左弧:将边 $s_2\xleftarrow{l} s_1$ 添加到图中并移除 $s_2$($s_2$ 不能是根元素)
带标签 $l$ 的右弧:将边 $s_2\xrightarrow{l} s_1$ 添加到图中并移除 $s_1$($s_1$ 不能是根元素)
移位:从缓冲区中移除第一个单词 $w_1$ 并将其放在堆栈顶部
当达到一个无法执行任何操作的配置时,过程结束。
该过程保证在有限步数后结束,在此配置中,缓冲区为空,并且创建的依存图是整个输入的良构依存树:
- 它会结束,因为在每一步中我们都会减少依存图的 “collective token distance”
缓冲区必须为空,因为否则移位操作将可用,并且堆栈只能包含根元素,原因类似
每个输入标记在图中恰好有一个中心词
图中不能有circle
选择正确的操作
解析器如何决定选择哪个操作?模型必须充当一个 可能配置的分类器:如果有 $n$ 个标签,那么将会有 $2n+1$ 个 actions/classes。
为了为这个分类器提供训练数据,依存树库注释必须转换为包含
对的监督数据集,即,treebanks 必须转换为关于“parsing oracle”动作的数据集,解析神谕总是选择正确的操作。
将解析树“转换为神谕操作”
给定正确的解析树,可以使用一个简单的算法重建oracle的配置和操作:
(显然)从堆栈中仅包含根和包含完整输入的缓冲区开始
如果选择左弧操作会导致正确的边,则选择该操作并附上正确的标签
否则,如果选择右弧操作会(i)导致正确的边(ii)所有以 $s_1$ 为中心词的依存关系已经添加到依存图中,则选择该操作并附上正确的标签
否则选择移位操作
替代操作/转换集
Arc-standard 并不是基于转换的解析器所使用的唯一转换系统 — 一个重要的替代方案是 arc-eager,它可以显著简化某些推导。Arc-eager 有以下操作:
右弧: 添加边 $s_1\xrightarrow{l} w_1$ 并将 $w_1$ 移动到堆栈顶部
左弧: 添加边 $s_1\xleftarrow{l} w_1$ 并从缓冲区中移除 $w_1$。前提条件:$s_1$ 尚未有中心词
Shift: 将 $w_1$ 移动到堆栈顶部
Reduce: 从堆栈中移除 $s_1$。前提条件:$s_1$ 已经有中心词
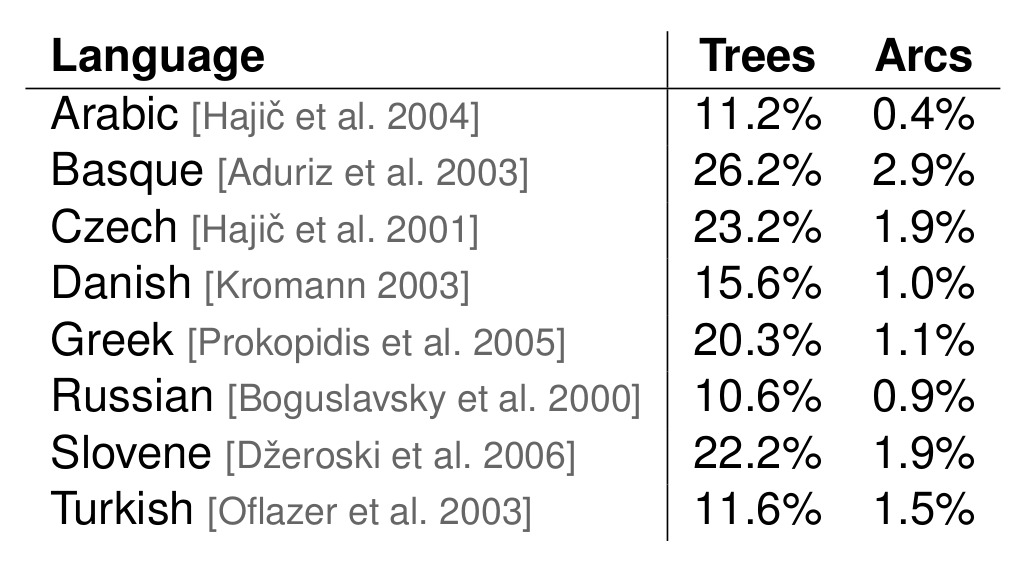
非投射性问题
Arc-standard 和 arc-eager 转换只能生成投射树,但大多数树库包含相当数量的非投射句子:
非投射性:解决方案
使用可以创建(一定数量的)非投射边的转换系统
伪投射解析:
找到一个 $\varphi$ 映射,将所有相关的(投射和非投射)树映射到投射树
对于训练,使用 $\varphi$ 对训练集进行“投射化”,并在转换后的数据集上训练解析器
对于预测/推理,应用 $\varphi^{-1}$ 到解析器的输出,以获得最终的(可能是非投射的)结果
分类器特征
从配置中提取适当的特征对于性能至关重要。传统的(例如基于感知器的)解决方案使用复杂的、专家设计的特征模板,例如,

与其他领域一样,手动特征工程和数据稀疏性的问题导致了深度学习解决方案的发展,这些解决方案依赖于embeddings进行分类。Stanford 神经依存解析器是一个简单但具有代表性的例子:
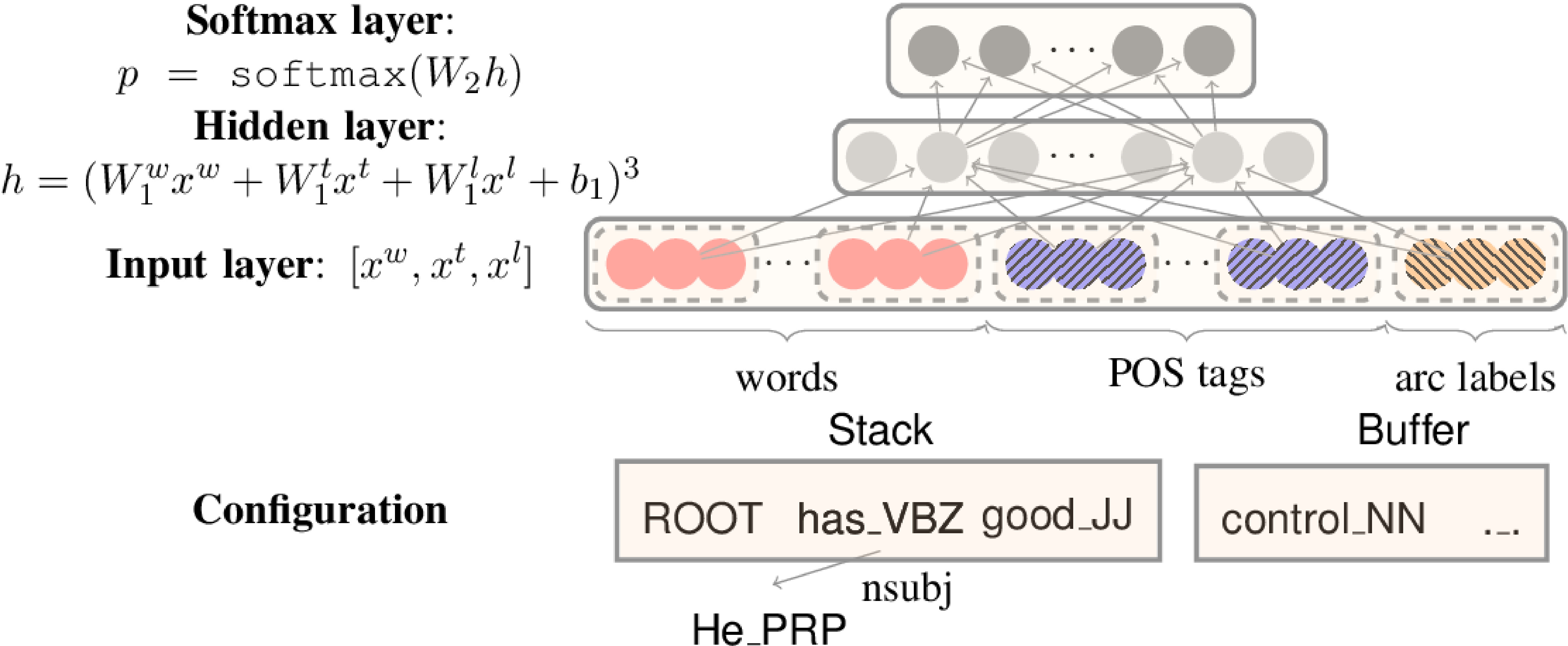
架构
所使用的模型架构是 NLP 中典型的分类架构:
在出现基于深度学习的解析器之前,主要使用线性模型(使用 weighted perceptron 或 SVM 作为学习算法),但也存在基于 k-NN 的解决方案
在深度学习中,在出现基于 transformer 的解决方案之前,CNN 和 LSTM 模型占主导地位,这些解决方案在很大程度上依赖于预训练的上下文嵌入,如 BERT
基于图的解析
两种对解析树进行评分的对比方法:
基于转换的方法 将对依存图的评分问题转化为对一个稍微复杂的图构建过程步骤的评分
基于图的解析器,相反,直接对图本身进行评分,并尝试找到得分最高的依存图:
$$\hat g =\underset{g\in G}{\operatorname{argmax}}~S(g)$$
一种简单但表现出色的方法是:
- 创建一个由所有可能的依存边组成的完全连接、有权重、有向图(如果有 $n$ 个标记和 $l$ 个标签,则有 $n(n-1)l$ 条边)
- 单独对边进行评分,然后
- 找到总得分最高的(方向正确的)树
假设是
$$S(g) = \sum_{e\in g} S(e)$$
这种对图进行评分的方法称为edge-或arc-factored方法。
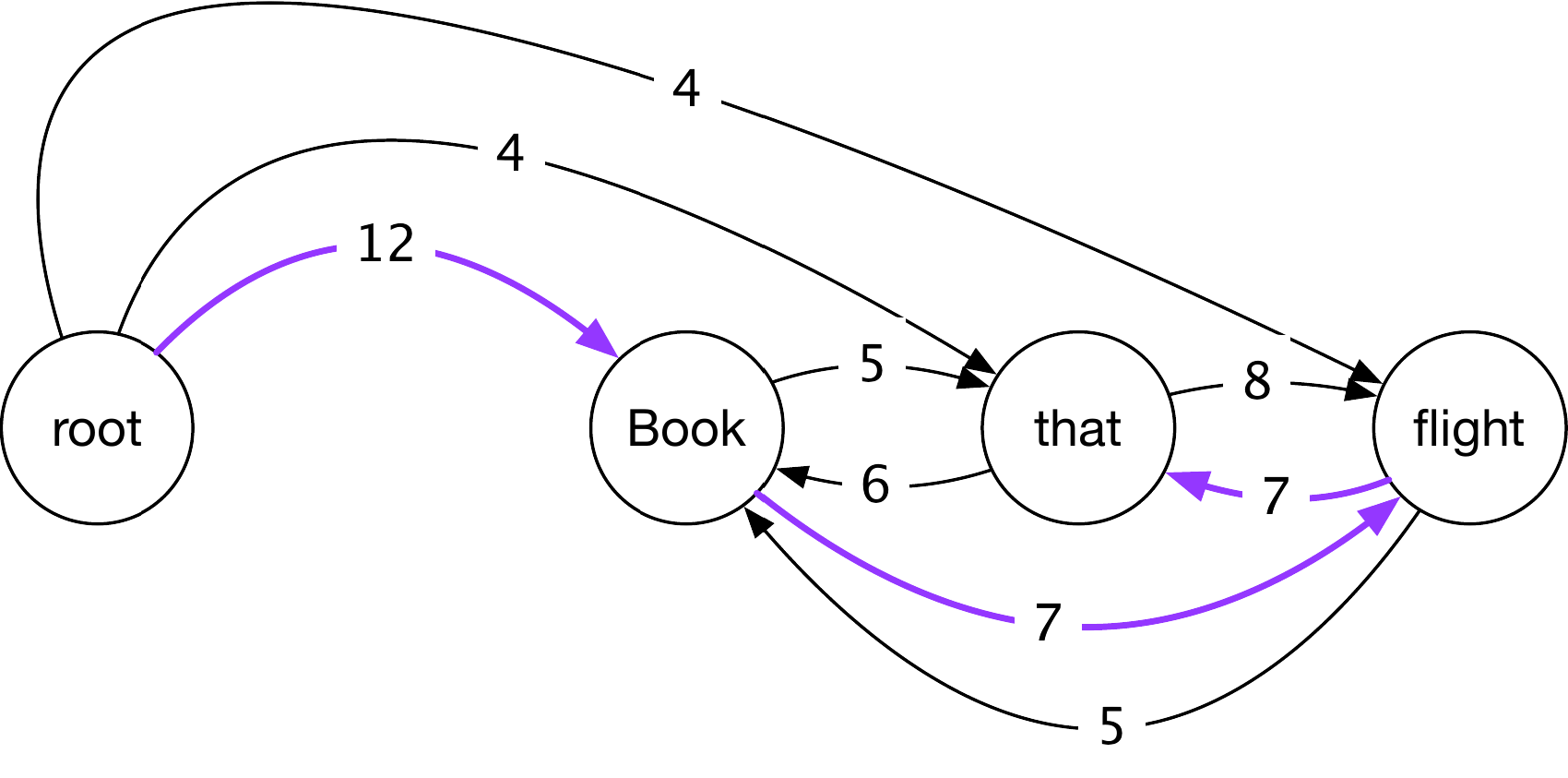
寻找得分最高的树
显然,对所有可能的图进行暴力搜索是不可行的。幸运的是,有一些相对快速的算法可以找到得分最高的树(所谓的maximum spanning tree)。
一个常用的算法是 Chu-Liu-Edmonds 算法,其时间复杂度为 $\mathcal O( n^3 l)$,其中 $n$ 是输入标记的数量,$l$ 是可能的标签数量。通过将边缘得分存储在一种特殊的数据结构中,即所谓的斐波那契堆,可以将其减少到 $\mathcal O(n^2l)$。
边缘评分特征
基于图的依存解析器是regressors:它们必须为输入标记之间的可能边缘生成得分。所使用的特征模板类似于基于转换的解析器:
- 依存词及其词缀(affixes)、词性(POS)等
- 中心词及其词缀、词性等
- 边缘标签
- 句子中中心词和依存词之间的关系,例如它们之间的距离
- 对于神经架构,节点和边缘标签的嵌入
Architectures
与基于转换的情况类似,多年来已经开发了经典的机器学习和神经网络的基于图的解析器,性能最高的解析器使用自注意力层。
一些最近架构的一个重要方面是由 @dozat2016deep 的论文引入的,即它们对同一单词的中心词和依存词表示使用不同的嵌入集。
vs
这两种方法之间存在重要的权衡。
时间复杂度: 解析 $n$ 个标记并有 $l$ 个可能的边缘标签的时间复杂度为
对于基于转换的解析器通常是 $\mathcal O (n)$,而
基于图的解析器预先计算所有可能边缘的分数,因此它们从 $\mathcal O(n^2 l)$ 操作开始,并且还要加上找到最大生成树的时间。即使我们将找到标签视为一个单独的任务,$\mathcal O(n^2)$ 的复杂性也是不可避免的
非投射性: 如我们所见,非投射性是最广泛使用的转换系统的一个严重问题,需要特殊处理。基于图的方法没有这个问题。
性能: 基于转换的系统往往在处理长距离依存关系时存在问题,而基于图的模型没有这个性能问题。因此,依存解析器的排行榜通常由基于图的系统主导。
NLP-DependencyParsing