NLP-DeepSTT
端到端 STT
HMM-ANN 混合模型
神经网络可以在基于 HMM 的语音转文本 (STT) 模型中代替传统的发射模型。该模型的训练分为两个步骤:
- 在数据集上训练一个传统的 HMM-GMM 模型
- 训练一个神经网络分类器,根据可观察的声学特征预测 HMM-GMM 模型的隐藏状态。训练数据集是 HMM-GMM 模型在训练数据上生成的隐藏状态-声学对齐
用于这些神经发射模型的架构从简单的 MLP 到复杂的基于深度学习的模型,例如 LSTM。
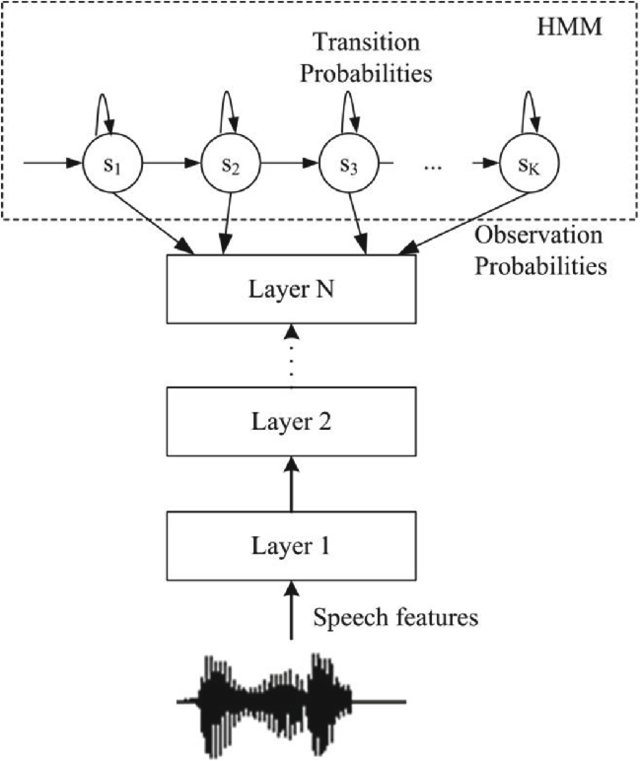
训练好的神经分类器输出 $P(hidden | acoustic)$ 概率,但对于 Viterbi 解码,使用的是发射概率
$$P( acoustic | hidden) = \frac{P(hidden | acoustic) P(acoustic)}{P(hidden)}$$
幸运的是,对于解码,只需计算缩放后的
$$ \frac{P(hidden | acoustic)}{P(hidden)} \propto P( acoustic | hidden)$$
值,因为 $acoustic$ 是固定的,并且 $P(hidden)$ 值可以从对齐数据中的隐藏状态频率估计出来。
端到端 DL-based ASR 系统
Deep Speech (Baidu, 2014)
这种类型的第一个重要模型是 Baidu 的 Deep Speech,它与传统的基于 HMM 的 ASR 解决方案相比,引入了根本性的变化:
- 声学模型是一个端到端训练的 DNN
- 音素级表示被完全消除:系统仅根据书面转录进行训练,没有任何语音信息
- DNN 的输入仅由音频信号的频谱表示组成(没有 MFCC 等)
- 系统的输出不是单词,而是输入的字符级转录
- 网络使用 CTC(连接时序分类)损失进行训练,并使用 CTC 解码生成最终输出
这个出乎意料的简单架构仅包含 5 个隐藏层,其中只有一个是简单的(双向,但不是 LSTM)RNN。输入是一个窗口,在每个时间步包含帧的移动窗口的频谱。
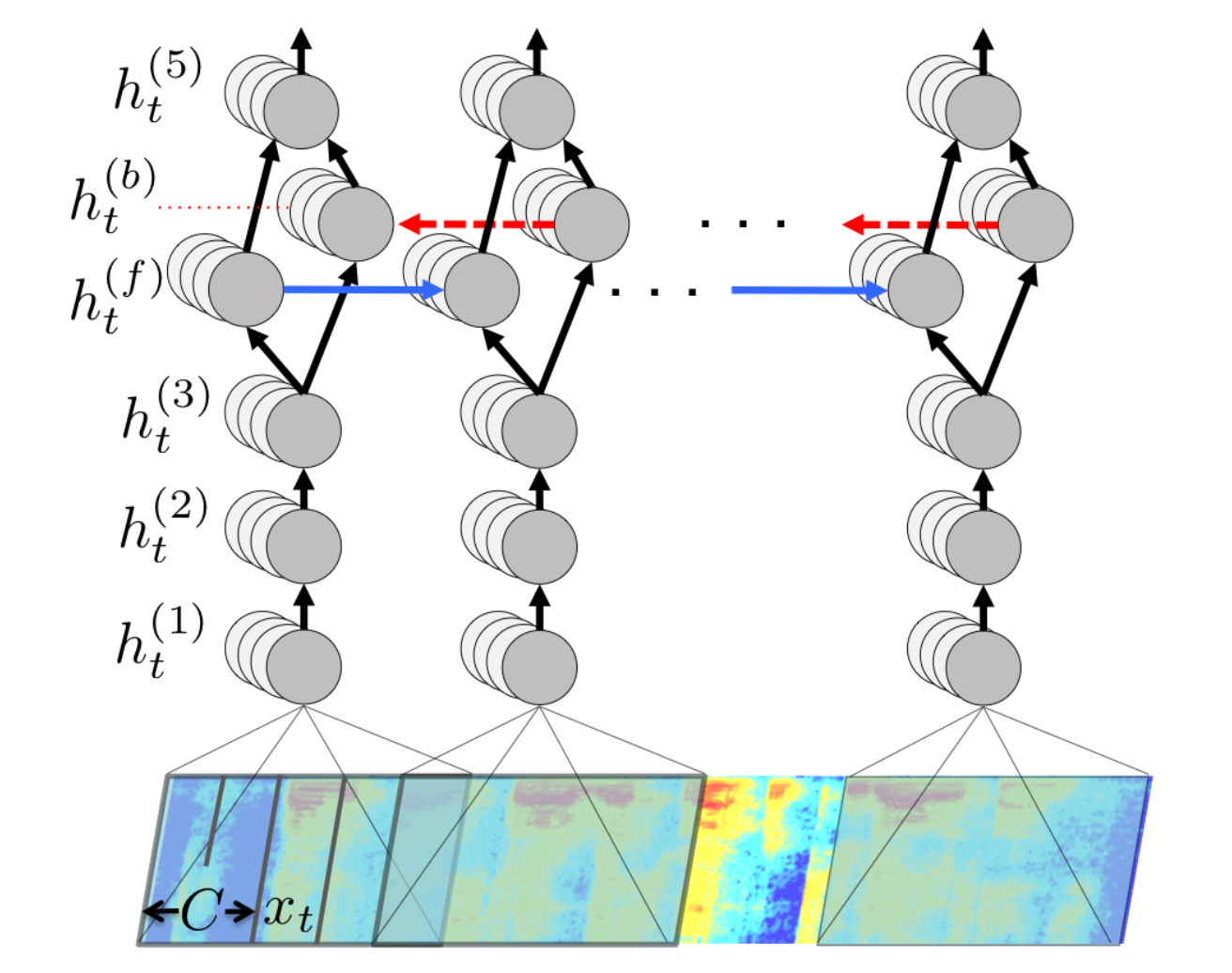
- 即使没有专用语言模型,性能也可以接受,但完整系统使用了一个 N-gram LM
- 尽管 Deep Speech 在当时改进了最先进的技术(Switchboard 语料库上的 WER 从 18.4% 降至 16%),并且使用了一个出乎意料的简单和干净的架构
- 它是在比通常用于基于 HMM 的训练的数据集大得多的数据集上训练的:虽然 200 小时长的数据集被认为对基于 HMM 的系统来说已经足够,但 Deep Speech 的最大模型是在“9600 名说话者的 5000 小时朗读语音”上训练的。
连接时序分类损失
HMM 基于 ASR 模型的最大似然估计 (MLE) 要么基于
- 一个完全对齐和注释的语料库,其中隐藏状态是已知的,在这种情况下,估计可以基于频率,或者使用
- 前向后向算法,这是 EM 算法在 HMM 上的应用
对于 Deep Speech 类模型,应使用哪种类型的损失,这些模型
- 为每个语音时间步预测一个字符,并且
- 关键是,真实值是由正常书写的单词组成的转录字符序列?
这个问题非常普遍,它出现在许多序列分类应用中,其中真实值是未对齐的,例如在 OCR、视频帧的动作分类以及 STT 中:
在真实转录 $\mathbf y$ 和一系列时间步长字符分布输出 $\mathbf X$(两者的长度通常不同)的上下文中,我们希望计算
基于计算 $P(\mathbf y | \mathbf X)$ 的训练损失,以可微分的方式进行 MLE 基于 GD 的参数优化
通过高效计算
$${\mathbf{y}^*}=\underset{\mathbf y}{\operatorname{argmax}} ~ P(\mathbf y | \mathbf X)$$
进行推理。
主要思想是通过找到所有可以与 $\mathbf y$ 对齐的单个 $\mathbf x_y$ 序列并根据 $\mathbf X$ 中的分布累加它们的预测概率来计算 $P(\mathbf y | \mathbf X)$:
$$ P(\mathbf y | \mathbf X)= \sum_{\mathbf x_y}P(\mathbf x_y | \mathbf X) $$

复杂性:
- 可能有一些时间步长在最终预期输出方面没有适当的分类,例如输入中的静音
- 有时字符重复不能简单地折叠,例如在
hello的情况下
这些问题通过在输出词汇表中引入“空白” $\epsilon$ 标签/字符来处理。

在固定时间步长序列上的可能 $\mathbf x$ 字符组合的数量当然是序列长度 $T$ 的指数,并且可以对齐的 $\mathbf y$ 序列的数量也可能非常大,因此重要的是高效地计算 $\sum_{\mathbf x_y}P(\mathbf x_y | \mathbf X)$。
幸运的是,与 HMM 的 Viterbi 算法类似,有一个快速的动态规划算法可以在 $\mathcal O(T)$ 时间内计算总和。
还有线性时间复杂度的解码算法,即计算最可能的最终输出序列 $\underset{\mathbf y}{\operatorname{argmax}} ~ P(\mathbf y | \mathbf X)$。
Whisper
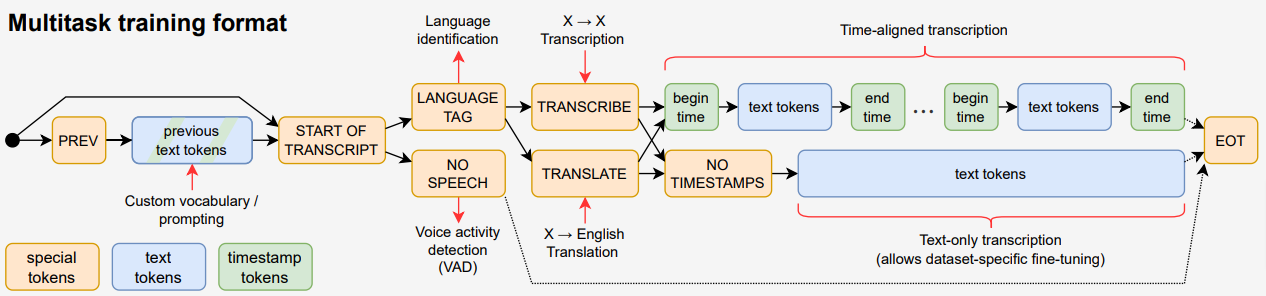
Whisper 是一个基于 transformer 编码器-解码器的模型,训练用于执行各种语音处理任务,包括:
- 多语言语音识别
- 语音翻译(任何语言到英语)
- 口语语言识别
- 语音活动检测
创新不在于架构,而在于扩大模型规模并在大量异构、弱监督数据上训练,以处理大量语音任务。
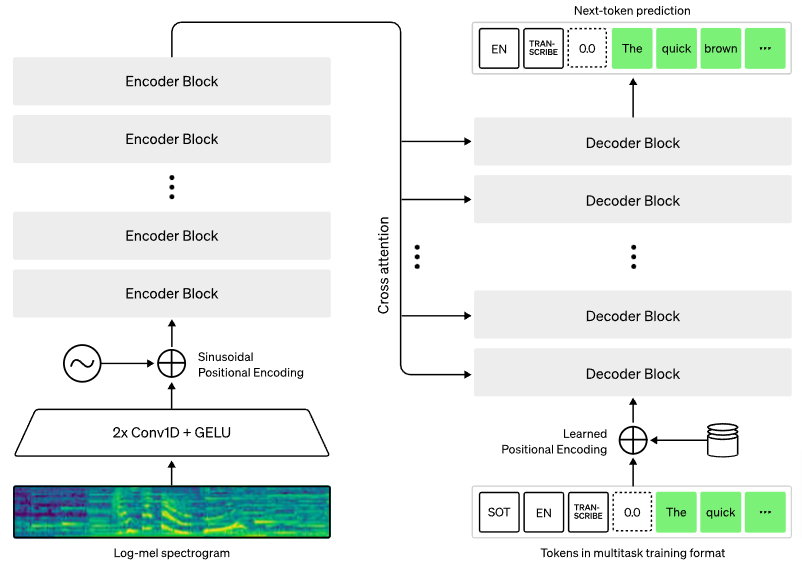
值得注意的细节:
- 预处理的音频由 80 通道 Log-Mel 频谱图表示,窗口为 25 毫秒,步幅为 10 毫秒
- transformer 编码器的“音频标记化”由两个 3 宽的 1D 卷积滤波器组成,第二个使用步幅为 2
- 模型执行的任务由任务指示符特殊标记表示
任务特定表示
训练
- 该模型在 680000 小时的(弱标记)数据上训练,包括 117000 小时的非英语语言和 125000 小时的英语语音翻译
- 数据集经过筛选,仅包含人工生成的数据
- 模型大小从 39M 到 1550M 参数不等
- 解码器的输入包含随机选择的数据点的前一段转录
结果
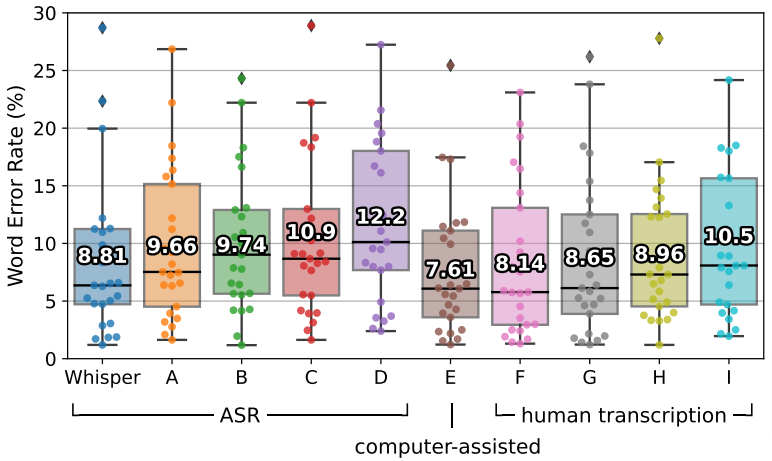
Whisper 的 ASR 性能与最先进的商业 ASR 系统竞争,并且优于所有开源系统。它的表现也非常接近人类专业人员。
NLP-DeepSTT