NLP-DatasetsBenchmarks
数据集,基准测试,引导
介绍
众所周知,LLM 需要庞大的文本语料库进行(预)训练。
实际上,我们使用几种类型的数据集来训练和/或评估 LLM:
- 预训练语料库
- 微调数据集
- 指令微调数据集
- 基准测试
在本讲座中,我们将详细讨论这些类型,并了解每种类型的最流行示例。
预训练
LLM(顾名思义)总是通过某种形式的语言建模目标进行训练:
- 因果(自回归)语言建模
- 掩码语言建模(MLM)
- 等等
这种类型的预训练只能在庞大的文本语料库上进行(取决于模型大小)。LLM 需要比 人类儿童/年轻人 遇到的文本数据多得多。另一方面,
- LLM 没有多感官输入(有些在某种程度上有)
- 我们之前看到一次性标签会减慢收敛速度
预训练语料库大小
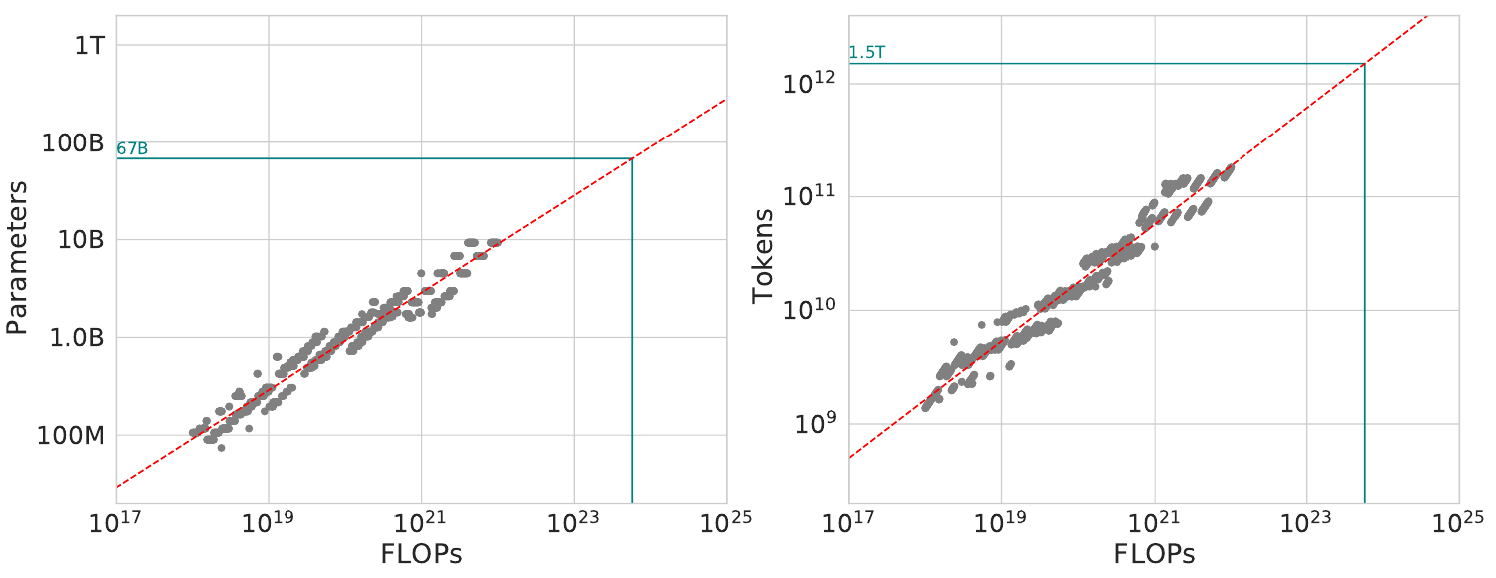
来源
预训练语料库通常来自多种来源的混合:
- 网络文本
- 书籍和娱乐
- 学术存储库
- 程序代码
- 对话数据
- 杂项
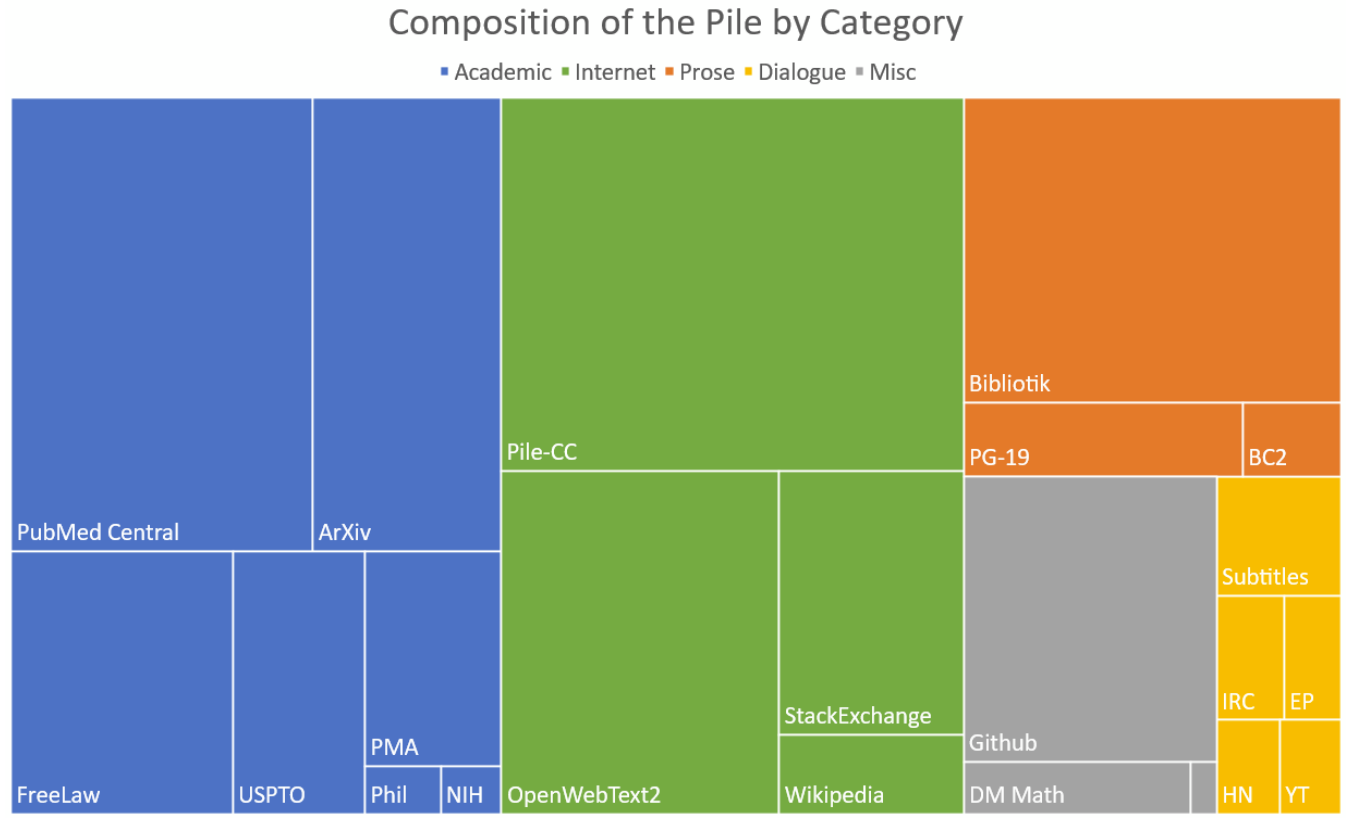
the Pile 的组成:一个 800GB 的英语语料库用于 LLM 预训练。它由 22 个数据集创建,组成如下:
网络文本
通常是任何预训练语料库中最大的组成部分。
优点:
- 易于获取,通常以网络抓取格式存在
- 数据量大
缺点:
- 质量参差不齐,通常低于其他来源
- 即使是好的页面也包含非内容元素(例如广告)
- 文本重复
- 偏见、有害、极端内容
- AI 生成/自动翻译的内容
网络文本语料库
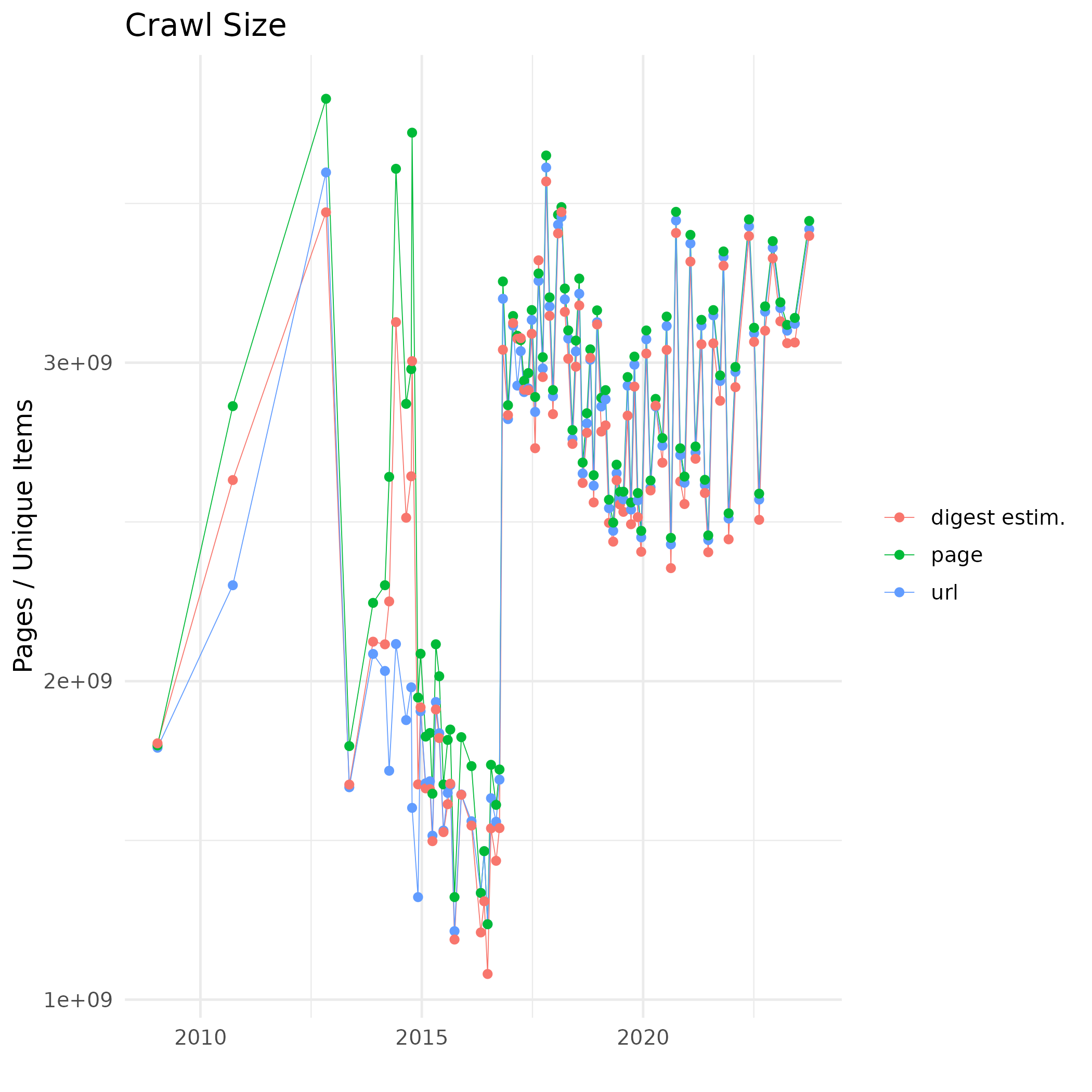
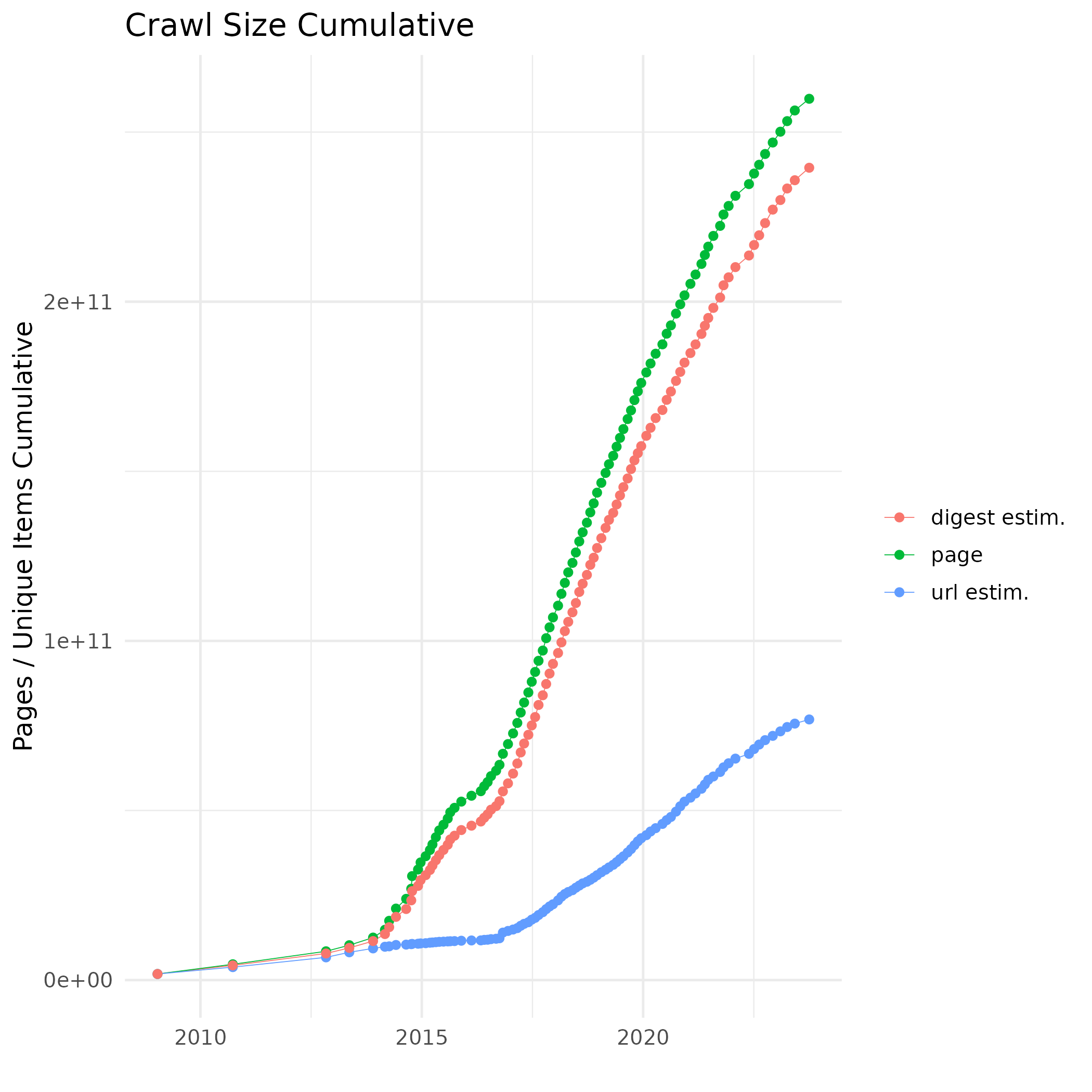
Corpora
- 一个免费的、开放的网络抓取数据存储库,以 WARC 格式提供
- 大约每月一次新的抓取
- 数据量达到 PB 级;2023 年 9/10 月的抓取数据为 100TB
- 构成了大多数用于预训练的网络文本语料库的基础
English
C4:
- 从 2019 年 4 月的 CC 转储创建;750GB
- 用于预训练 T5
- 过滤包含不良词汇的文档(减少 $3\times$)
WebText:
- GPT-2 的预训练语料库
- 800 万文档,40GB
- 从“策划”的文档中创建:Reddit 上至少有 3 个 karma 的外部链接
- 不包括 Wikipedia,以避免 GPT-2 的测试集与训练集重叠
- 专有
OpenWebText:
- WebText 的开源重新实现
Multilingual
OSCAR:
- 一个巨大的多语言语料库,由单个每月 CC 抓取创建
- Ungoliant 数据管道
- 标记数量:
- 英语:3770 亿
- 匈牙利语:46 亿
- 约鲁巴语:1 千
ROOTS:
- 一个 1.6TB 的语料库
- 由 BigScience 编译
- 国际研究人员合作
- Hugging Face 支持
- 用于预训练 BLOOM
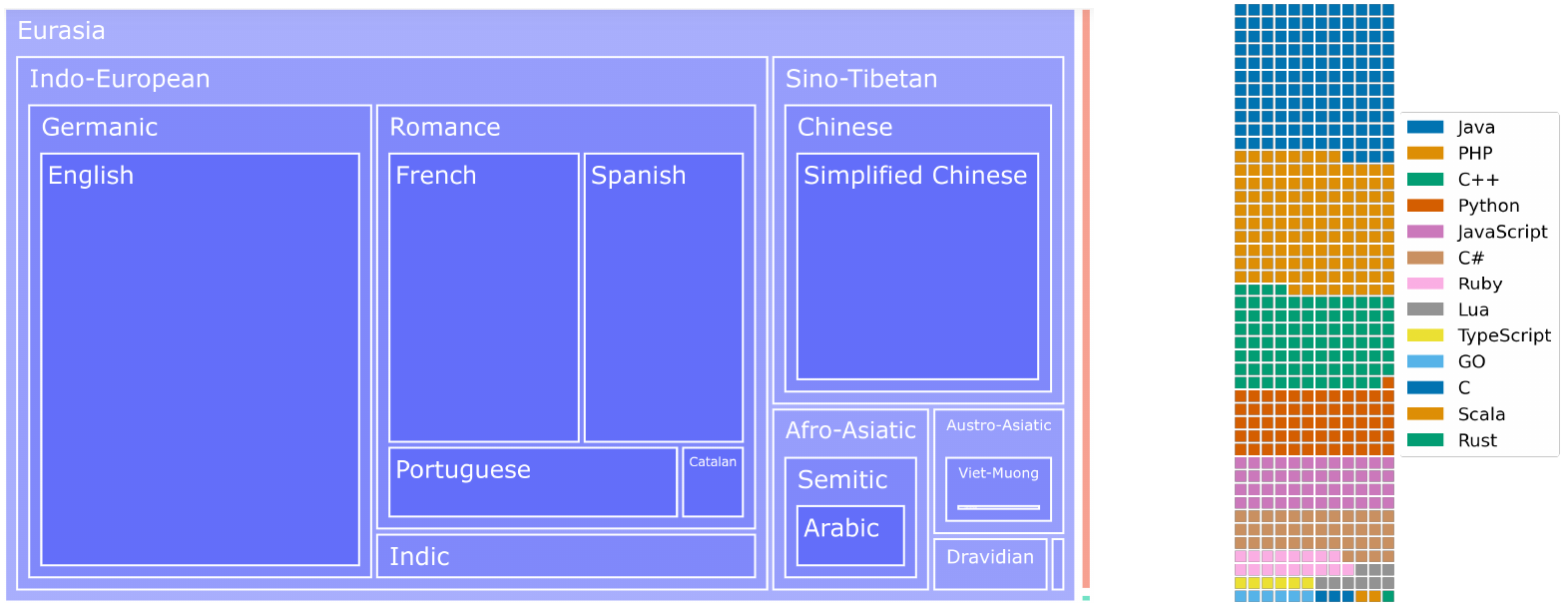
ROOTS 中的语言
ROOTS 的语言分布。此外,与其他语料库(例如 OSCAR)相比,英语被高度下采样。
mC4:
- C4 的多语言版本 (Hugging Face HUB)
- 基于整个 CC 语料库(截至 2021 年),因此有足够的数据用于中等规模的语言,如匈牙利语(390 亿标记)
- 并未真正清理过,因此标记数量有些乐观
llm-datasets
- 数据集和脚本的 GitHub 仓库
- 包含 Common Crawl 以外的语料库
如何预处理 Common Crawl
基于 Common Crawl 创建特定语言的网络文本语料库看似简单,但实际上是一个多步骤的过程,存在许多陷阱。这里我们回顾一下 cc_corpus 所采取的步骤,这是用于创建 Webcorpus 2 的管道。
要求:下载所有(多个)每月转储,因为只有英语在一个转储中有足够的标记。
下载索引
- CC 索引是按域名而不是按语言划分的
- 例如,对于匈牙利语,我们下载
.hu顶级域名- 根据 OSCAR 统计,包含许多匈牙利语页面的其他域名
- 在每月索引转储之间去重 URL
下载数据
- CC 不应被 DDoS
- WARC 文件需要大量空间
去除样板
- 去除网页的非内容部分(导航、广告、图片、表格等)
- 我们使用 jusText 和自定义代码去除 JS / cookie 警告
- 需要处理各种文件类型(HTML、RSS、文本等)
过滤
- 语言过滤
- 基于质量的过滤:
- 文档长度
- 还可以使用例如样板比例、某些 HTML 标签的长度等
去重
- 文档级去重以保持文本完整性
- MinHash–LSH 设置
- 需要大量内存,否则会非常慢
- 可选:按域名去重频繁段落(基于内容的样板去除)
- 文档级去重以保持文本完整性
硬件设置:
- 在单个服务器上运行;多服务器通信正在进行中
- 所有类似映射的步骤都是高度并行的,以充分利用 多核/CPU 服务器
- 一台具有 768GB 内存的服务器用于去重
特殊网络文本数据集
Wikipedia:
- 非常优质的编辑资源,大多真实
- 大小取决于语言,例如英语是匈牙利语的 10 倍
- 预处理并不简单,因为标记格式:
- wikiextractor 尝试解决这个问题
- zim_to_corpus 从 Kiwix 的预处理 .zim 存档中提取文本
Stack Overflow, Reddit:
- 策划的数据集(points / karma)
- 可用于问答、编程等
编辑文本
编辑文本是高质量文本的重要来源。不幸的是,与网络文本相比,数量上要难得多。
编辑文本通常有两种格式:
数字原生:从一开始就为数字消费准备的文本。通常可以直接使用,但
- 可能需要去除样板:表格、图形、页眉/页脚
- 编码问题确实会发生,尤其是 PDF
扫描:原本在纸上的数字化文档。版面分析 和 光学字符识别 (OCR) 的质量可能从可接受到非常糟糕不等。
编辑文本 / Prose
自 BERT 以来,常规散文(如书籍)一直是 LLM 训练方案的一部分。文本的水平因体裁而异,导致训练语料库多样化。
BookCorpus
- 一个由 7,185 本自出版书籍创建的 985M 字语料库
- 用于训练 GPT 和 BERT,但后来被撤回,不公开提供
- BookCorpus2 (the Pile):BookCorpus 的扩展,大约 17k 本书
已出版书籍语料库:
- Books1-2 (GPT-3):67B 标记
- Books3,Project Gutenberg (the Pile):分别约 187k 和 27k 本书
- 匈牙利电子图书馆 (MEK):32,830 本书,800M 标记
OpenSubtitles:
- 从电影和电视字幕创建了 1689 个双语文本
- 可以从中提取大约 300M 字的语料库
- 语料库主要由对话组成
书籍等是预训练语料库的重要且非常有用的部分。然而,它们并非完全安全:
- 可能存在有问题的内容(色情、有害等)
- 在模型中使用它们可能导致 版权侵犯
编辑文本 / Professional
通常是非常高质量的专业文本,具有自己的术语。
学术存储库:
- 非常高水平的文本
- 许多表格、图形等,打断文本流
- 通常需要大学访问权限(和爬虫)来下载论文
议会记录:
- 国家 / 欧盟 / 等等
- 有些可能提供 REST API,有些需要爬取
法律、裁决、法规等
新闻:
- 大量且重要的来源,但也可能有偏见和有害内容
- 极端重复
- 通常在付费墙后面
私人数据:
- 公司规则和公司内部通信
- 知识等
杂项数据
对话
- 对于聊天机器人非常重要
- 对于通用对话:电影、书籍等
- 最重要的来源:互联网论坛、实际客户服务互动
编程
- 来自 CVS 服务(GitHub、SourceForge 等)的开源项目
- 版权和许可证违规是一个可能带来法律后果的问题
指令
指令获取
我们在前一讲中讨论了指令微调数据集的编译方式:
- 手动 / 众包努力
- 从用户收集数据
- 将 NLP 任务转换为指令
- 自我指令
我们已经看到 FLAN 如何将 NLP 任务转换为指令,但我们跳过了第一类。
Manual Instructions
手动创建指令数据集需要众包(crowdsourcing)。两个例子:
Databricks 的 Dolly:
- 包含 15,000 对提示/响应对
- 由 5,000 多名 Databricks 员工创建
-
- 用户分享他们与 ChatGPT 的对话
- 质量非常好,但由于 OpenAI 的许可证存在问题
- 被用于训练 Vicuna
LAION 的 Open-Assistant
- 由志愿者编译
- 英语和西班牙语代表性很好,但其他语言代表性不足
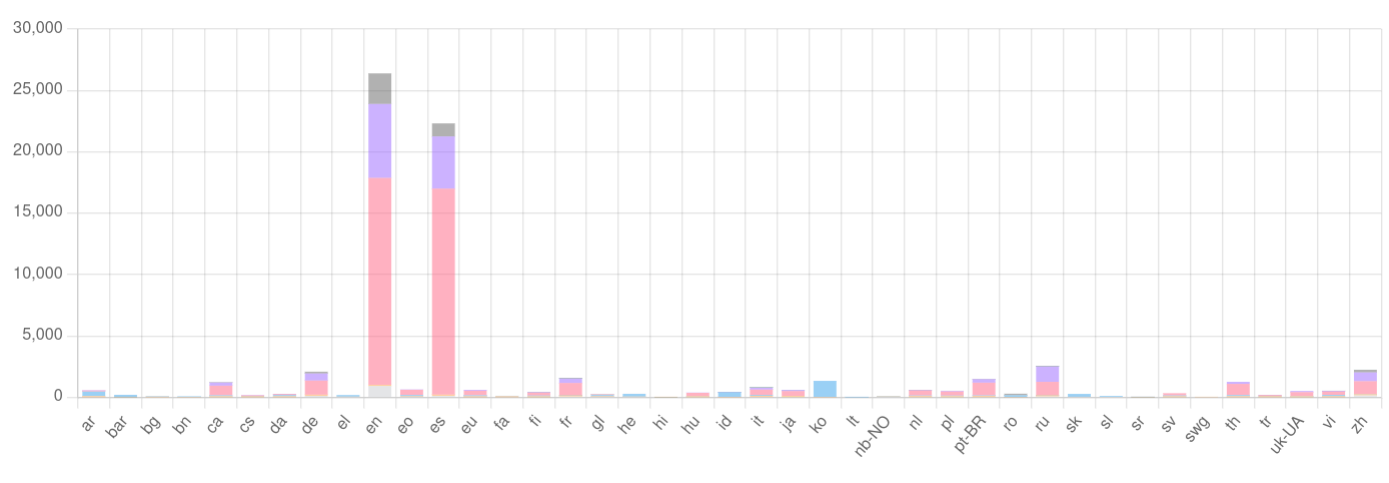
Self-instruct
两个自我指令数据集的例子:
-
- 使用 OpenAI 的
text-davinci-003创建的最著名的自我指令数据集 - 页面包含有关如何使用 GPT3 进行指令生成的良好建议
- 由于 GPT3 许可证,不能用于商业目的
- 使用 OpenAI 的
-
- 使用 Evol-Instruct 从 Alpaca 创建
微调
微调数据集
已经证明,具有分类器头的 LLM 可以在 NLP 数据集上进行微调,以达到最先进的结果。这包括
- 传统的 NLP 任务(NP 分块、NER、依存解析等)
- NLU 任务(问答、自然语言推理等)
- 各种分类数据集(情感分析、主题分类等)
这些通常在树库上进行训练
微调数据集具有训练-开发-测试拆分,因此它们也作为基准数据集。
传统数据集
| 任务 | 英语 |
|---|---|
| 命名实体识别 | CONLL 2003 |
| 其他数据集 | |
| NP 分块 | CONLL 2003 |
| 依存关系 | Universal Dependencies |
| 解析 | Penn TreeBank |
其他资源
- 可以在 NLP-progress page 上跟踪 NLP 任务的进展
- 有各种 NLP 数据集列表:
NLU 数据集
这些数据集包括传统 NLP 可以(和不能)解决的任务,但 LLM 可以。因此,这些数据集是 LLM 的便捷基准。
- GLUE:
- 一个包含 9 个任务的 NLU 基准(句子相似性、释义、QA 等)
- 测试集不共享;在线排行榜
- SuperGLUE:
- 8 个精心策划的任务(开放、困难、宽松许可等)
- SQuAD2.0:
- 由众包工人编译
- 10 万个问题加上 5 万个对抗性、无法回答的问题
- MMLU:
- 一个仅用于测试的基准,包含 57 个主题中的 15,687 个选择题
对抗性基准测试
问题:基准测试被越来越好的模型“快速”清除。我们能否创建更难的基准,使其持续时间更长?
模型脆弱性:证据表明
- 自然语言推理(NLI)数据集由于(注释者)偏见而表现出虚假的统计模式
- 模型实际上学习了这些模式,而不是推理
- 因此,它们是脆弱的,可以被非专家注释者打破
想法:人类与模型循环启用训练(HAMLET)。
对抗性 NLI
对抗性 NLI (Adversarial) 通过在注释者和模型之间引入“军备竞赛”编译而成。
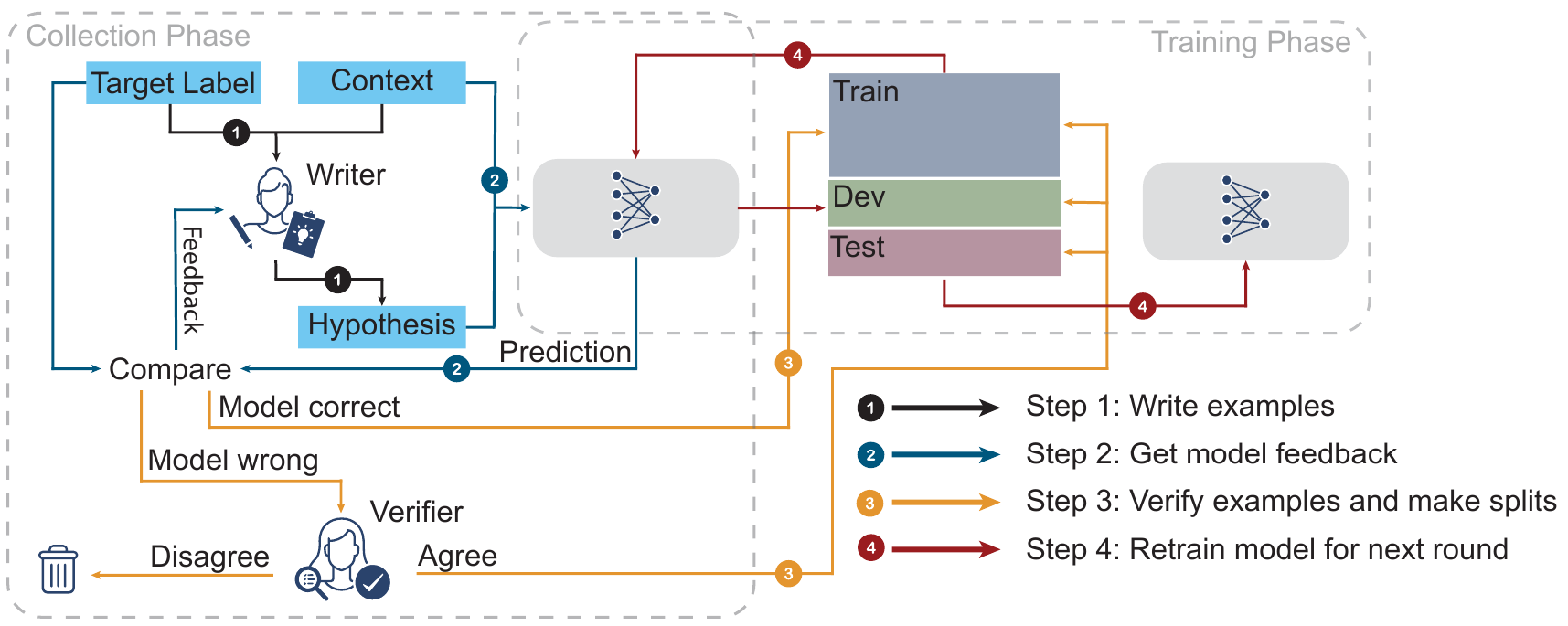
这导致
- 一个良好的训练集,可以很好地转移到其他 NLI 基准
- 一个非常难的训练集
测试工具
LLM 测试越来越多地通过 测试工具 自动化:
- Google 的 BIG-bench
- EleutherAI 的 lm-evaluation-harness
两者都包含 200 多个任务,并提供
- 新任务的轻松集成;
- 使用所有任务评估模型。
可重复的测试使得竞争成为可能,例如 Open LLM Leaderboard。
Bootstrapping
什么是引导?
引导 是一种使用现有资源创建新资源的方法。
在我们的例子中,我们将使用现有的预训练模型来创建新的数据集以训练新模型。
我们通常使用现有的最大、性能最好的模型。在 2023 年底,这些模型是私有的 GPT-4 和开源的 LLaMa2-70B。
引导是:
- 成本效益高
- 快速
- 易于实施
- 能够生成高复杂度数据
- 有风险(许可证问题、质量问题)
使用现有模型生成数据
“自我”指令
在这里,我们使用现有模型为我们自己的模型生成数据。在这种情况下,另一个模型是教师,我们的模型是学生。
重要区别:与蒸馏相反,我们不使用教师在向量级别的预测,而是使用教师在数据集中的标记级别输出。这样就不需要直接访问教师模型。
斯坦福 Alpaca 声称,这种方式的指令微调具有成本效益且快速。它可以在几百美元内完成。
![]()
零样本链式思维
可靠的链式思维(chain-of-thought)提示需要一些示例才能工作。通过使用 CoT 提示,我们可以为给定主题生成大量的 CoT 完成数据集。
WizardLM 通过使用 Evol-Instruct 逐步演变给定任务的指令,采用了一种更抽象的指令生成方法。这样生成的指令将覆盖任务空间的更广范围,并具有更复杂的提示。
我们提示我们的 LLM 生成指令的修改版本,然后使用这些版本生成数据集。这些修改步骤可以链接在一起。
Evol-Instruct
任务演变的示例(对于基本任务“1+1=?”):
- 深化:在什么情况下 1+1 不等于 2?
- 增加推理:如果 x^3 + 2x + 3 = 7,x 的值是多少?
- 具体化:如果你有一个苹果,有人给你另一个香蕉,你有多少水果?
- 添加约束:如何在哥德巴赫猜想中证明 1 + 1 = 2?
- 复杂输入:1/(sqrt(2) + 4^2) = ?
- 广度演变(变异):真空中光速是多少?
- 增加演变推理(上述):光在真空中比声音快多少倍?
演变步骤
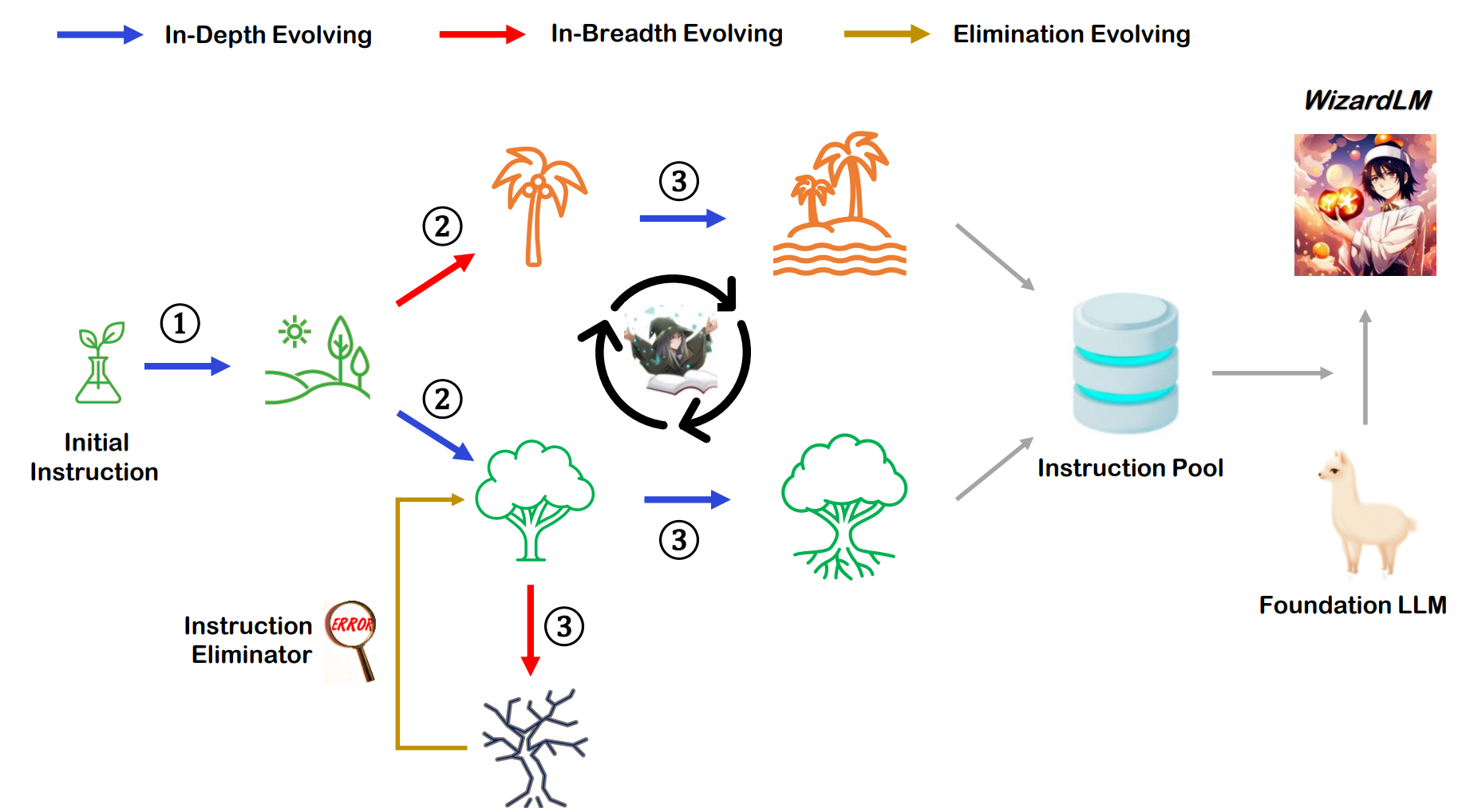
移除演变
当以下情况发生时,消除中间结果:
- 演变后的指令相比原始指令没有提供任何信息增益。使用 ChatGPT 来做出这个决定
- 演变后的指令使得 LLM 难以生成响应。如果生成的响应包含“对不起”且长度相对较短(即少于 80 个单词),通常表明 LLM 难以响应演变后的指令
- LLM 生成的响应仅包含标点符号和停用词
- 演变后的指令明显复制了一些来自演变提示的词语,例如“给定提示”、“重写提示”、“#重写提示#”等
EvolInstruct 的效果
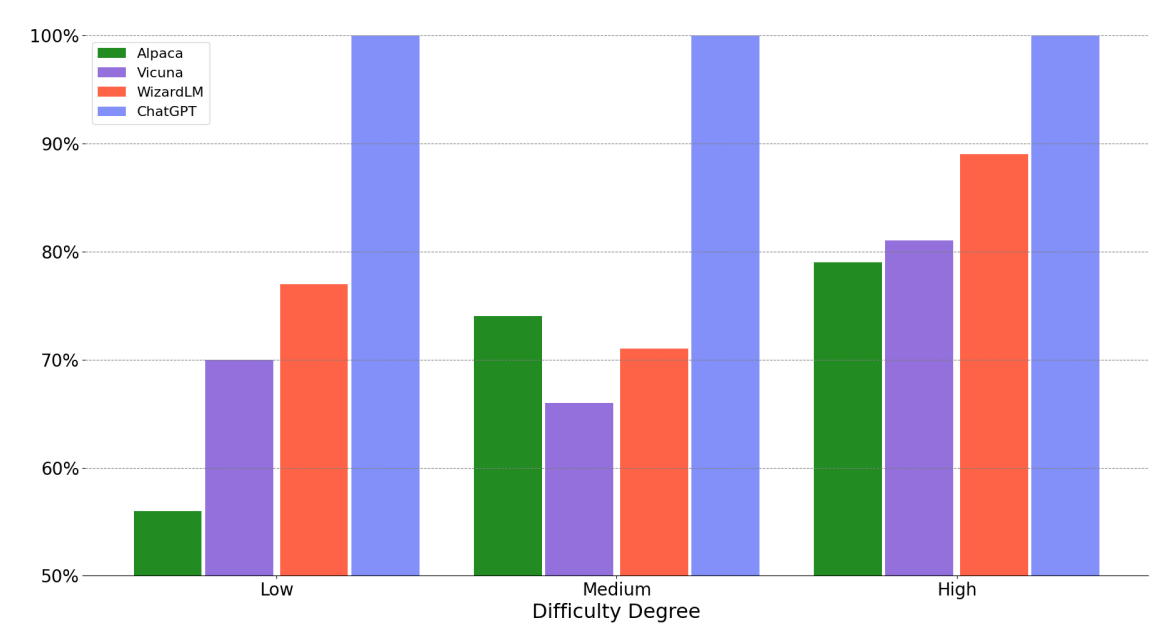
EvolInstruct 微调能够提高高复杂度任务的性能,如下图所示。
Orca
EvolInstruct 在指令生成方面引入了多样性。与此相反,Orca 深入研究了响应生成方面,特别是推理和解释生成。在原始论文中,他们为 LLM 定义了各种系统提示,以指导响应生成风格。
一些示例包括:
- 你是一个 AI 助手。提供详细的答案,使用户不需要在外部搜索来理解答案
- 你应该描述任务并解释你的答案。在回答选择题时,首先输出正确答案。然后解释为什么其他答案是错误的。想象你在回答一个五岁孩子的问题
解释调优的优势
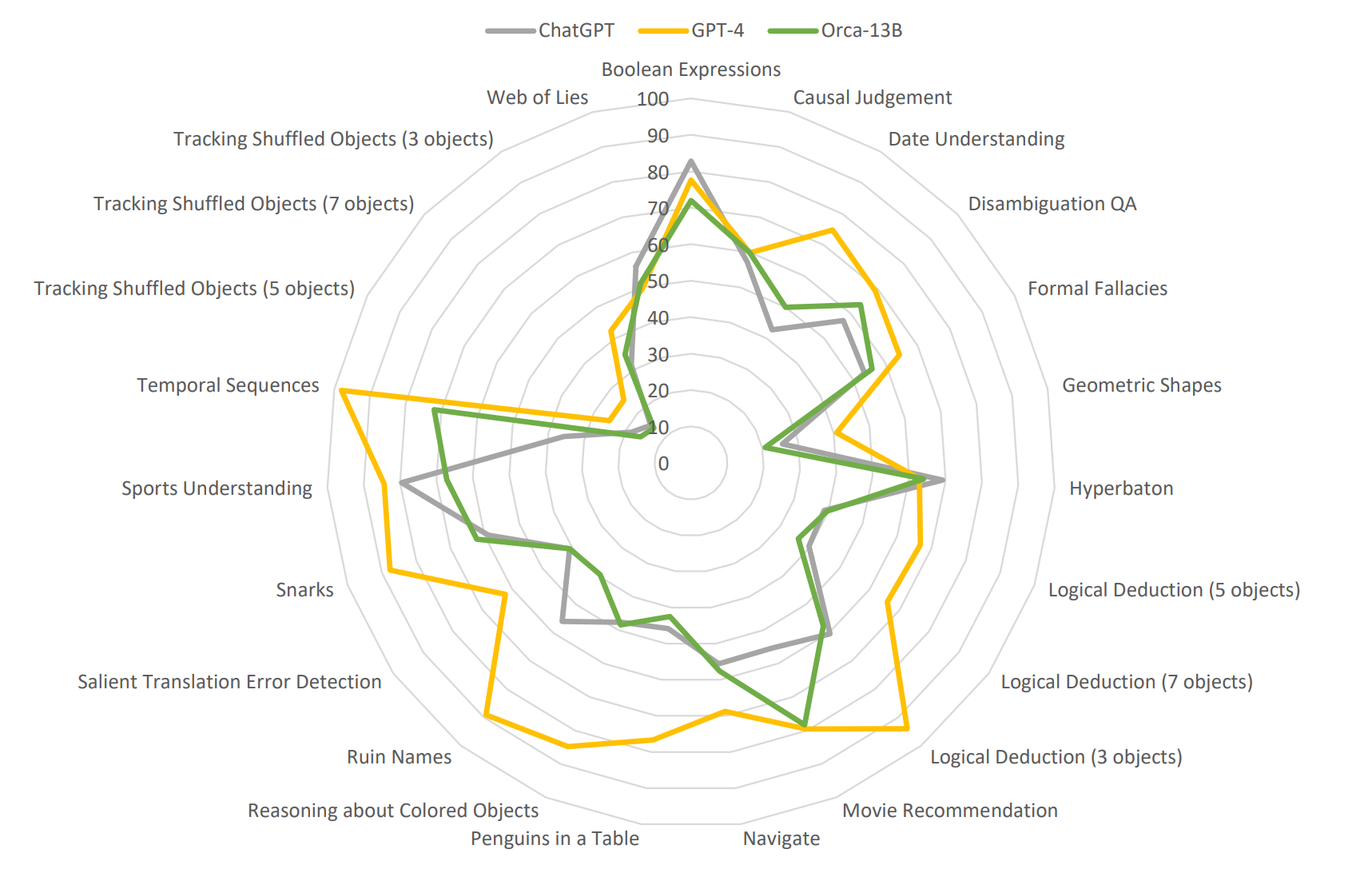
小模型通过解释调优可以轻松解决困难和专业任务。
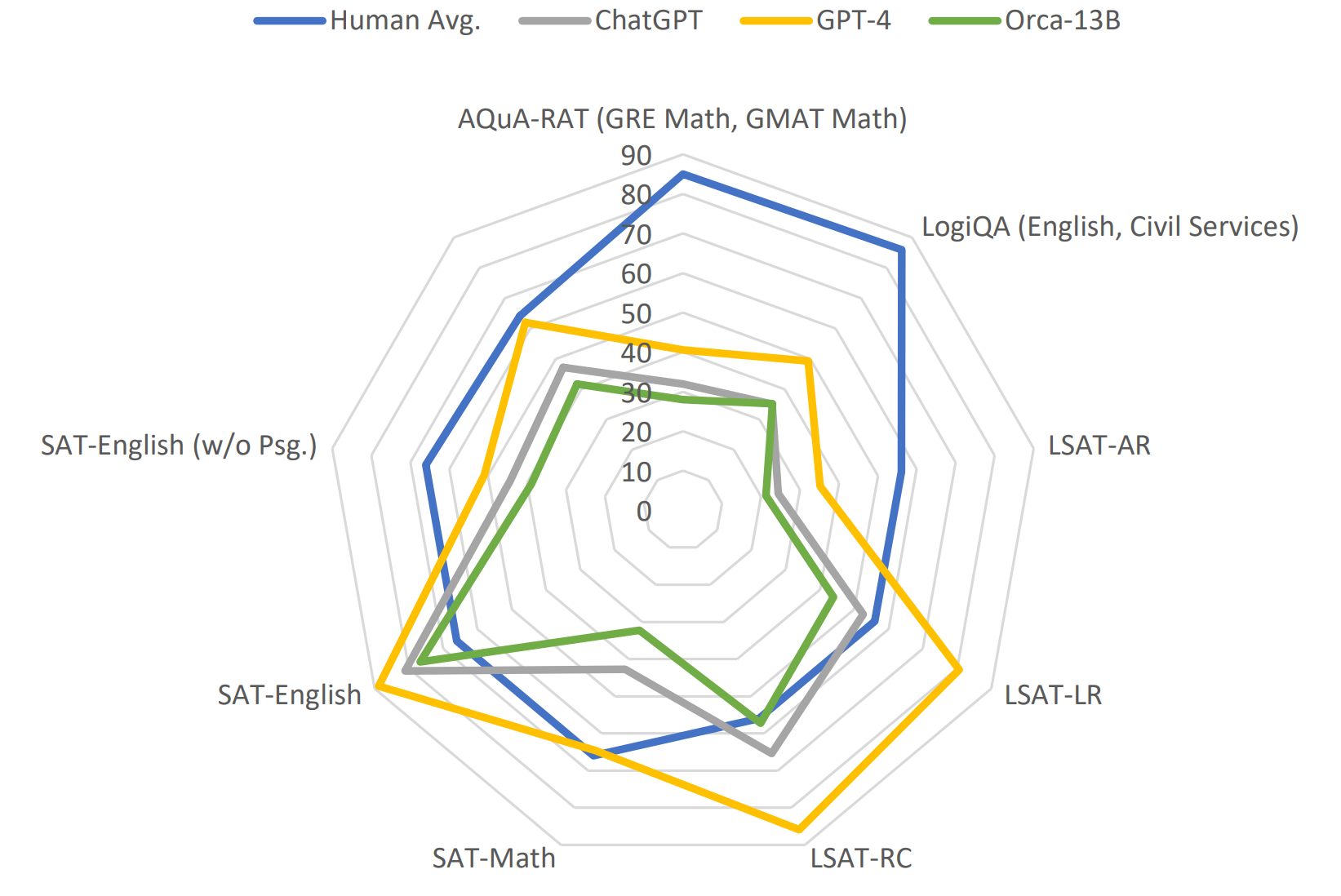
小模型通过解释调优可以轻松解决困难和专业任务。
模型评估
评估复杂模型很难,因为没有明确的方法来评估开放域性能。常见的方法包括人工和 LLM 评审。
人工评审昂贵且缓慢,但可以通过众包来加速和稳定这一过程,例如 Chatbot Arena。Chatbot Arena 是一个评估聊天机器人的平台,用户可以与多个机器人聊天并表示他们的偏好。
LLM 评审更快且更便宜,但偏见更大。利用方法包括:两个答案的成对比较、单个答案评分(分数分配)、参考引导评分(分数分配)。
模型偏见
根据 LLM 的评审,评审员倾向于第一个答案以及较长的答案。值得使用对称评估。“重命名”提示表明某些模型(如 Claude-v1)也对名称(如助手 A、助手 B 等)存在偏见。
| 评审员 | 提示 | 一致性 | 偏向第一个 | 偏向第二个 | 错误 |
|---|---|---|---|---|---|
| Claude-v1 | 默认 | 23.8% | 75.0% | 0.0% | 1.2% |
| Claude-v1 | 重命名 | 56.2% | 11.2% | 28.7% | 3.8% |
| GPT-3.5 | 默认 | 46.2% | 50.0% | 1.2% | 2.5% |
| GPT-3.5 | 重命名 | 51.2% | 38.8% | 6.2% | 3.8% |
| GPT-4 | 默认 | 65.0% | 30.0% | 5.0% | 0.0% |
| GPT-4 | 重命名 | 66.2% | 28.7% | 5.0% | 0.0% |
NLP-DatasetsBenchmarks