NLP-Alignments
对齐
AI alignment in general
AI系统的 对齐 是确保其操作符合
人类(用户、操作员等)的预期目标和偏好
一般的伦理原则 (ethical)
基于机器学习的AI系统的行为受到其开发者的多种方式影响。最重要的是,他们选择/开发了
用于训练数据驱动模型的数据集
如果模型使用强化学习进行训练,则是奖励函数(reward)
一般来说,在训练期间通过使用的参数优化方法(例如梯度下降)最小化或最大化的损失或目标函数
不对齐(misalignment 缺乏对齐)的实例有时分为两种(不一定容易区分)的类型:
外部不对齐:开发者指定的系统目标或奖励与预期的人类目标之间的偏差
内部不对齐:显式指定的训练目标与系统实际追求的目标(所谓的涌现目标 emergent)之间的偏差
指令跟随
大型语言模型中的涌现少样本能力
Emergent few-shot abilities
正如GPT-3所展示的那样,使用标准MLE目标训练的LLM在许多任务上表现出显著的 0-shot、1-shot和少样本性能:
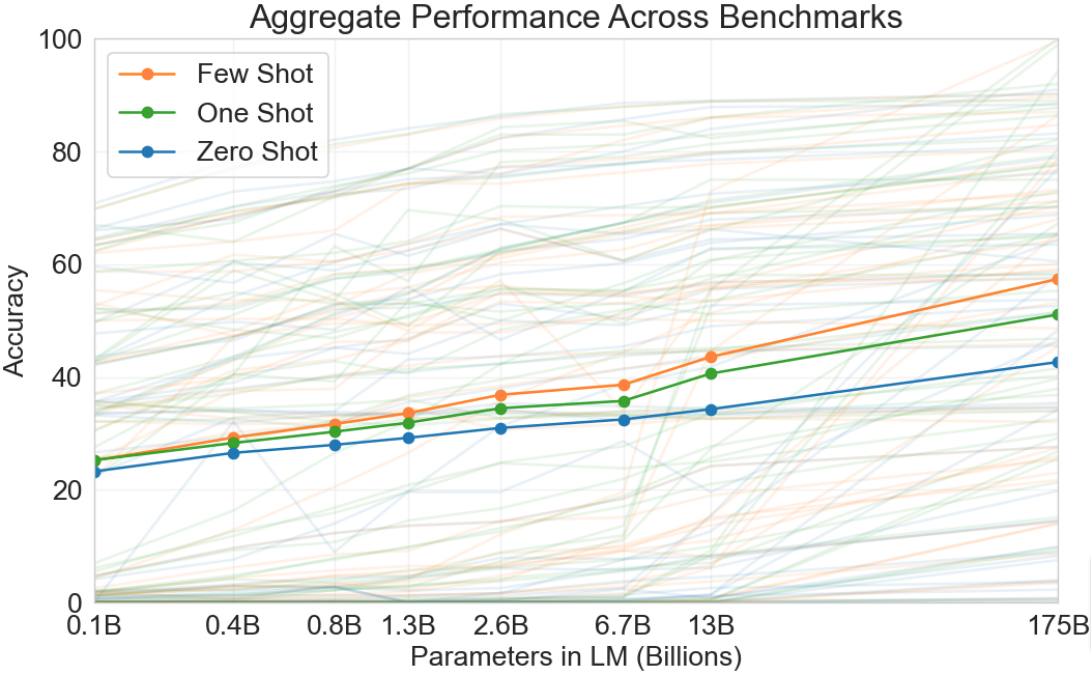
在许多情况下,MLE训练的LLM只需要一个包含任务简单描述的提示,并且可选地提供几个示例即可表现良好:

据报道,MLE训练的GPT-3在没有任务特定微调的情况下,在以下任务上表现良好:
- 翻译
- 问答
- 阅读理解
- SAT风格的类比
- 检测句子之间的逻辑关系
- 简单算术
- 单词拼写和操作(如字谜、单词反转等)
- 根据给定的标题和风格写诗
指令跟随模型
这些观察自然引出了基于LLM的通用 指令跟随助手 的想法,这些助手可以根据描述执行广泛的、开放式的任务。
从这种预期用途的角度来看,对这种模型的期望包括:
- 有帮助的:它应该真正尝试执行所描述的任务
- 诚实的:它应该提供准确的信息,包括在适当情况下表达不确定性
- 无害的:它不应该具有攻击性、歧视性,也不应该推荐或帮助危险或不道德的行为
指令跟随中的不对齐
关于这些人类目标和期望(它们应该作为 有帮助的助手)来说,GPT-3类的LLM在以下情况下训练
- (主要)在未经筛选的网络抓取数据上
- 使用基于标准MLE的语言建模目标
将会 不对齐:根据收到的提示,它们
- 可以轻易生成 有害的(危险的、歧视性的等)内容
- 产生听起来合理但不真实、误导性的陈述(“幻觉” hallucinations)
- 可能无法(尝试)真正执行所描述的任务
关于仅使用MLE训练的LLM正确执行任务的重要类型的不对齐是对小的和(对用户来说)看似无关紧要的 提示差异 过于 敏感。在任务描述、示例选择和示例顺序上的微小变化被报告为导致了巨大的性能差异。
一个说明性示例:实验提示模板对


他们发现左边的0-shot模板在GPT-3版本上比右边的1-shot甚至10-shot实例表现更好。(在WMT’14 Fr-En数据集上的BLEU得分为1-shot的18.0,10-shot的24.1,但0-shot提示的26.5。)
对齐与不对齐是相对使用案例的
MLE训练的语言模型仍然可以(并且确实)与其他合法的使用案例 良好对齐,例如,用于 OCR 或 语音识别 的语言建模,其中任务只是评估在某种上下文中由人类产生的一段文本或语音的概率。
与指令跟随的对齐
监督微调
提高指令执行的低和/或不一致性能的最明显方法是创建一个包含大量不同任务的 监督数据集,其中包含
$$(\mathrm{task \space instruction}, \mathrm{correct \space response})$$
对,并在其上对MLE预训练的LLM进行 微调。
给定一个好的指令数据集,监督微调本身不需要特殊技术,例如,对于一个transformer-decoder类型的语言模型
$(\mathrm{instruction}, \mathrm{response})$ 对被转换为单个序列,中间有一个固定的分隔符(例如,Flan在它们之间使用一个“特殊的EOS标记”)
训练损失是通常的 交叉熵损失(使用教师强制),它可以包括指令中标记的损失,但可能权重较低
指令数据集
更严峻的挑战是创建高质量的指令数据集 (instruction)。
创建数据点的主要策略是
手动创建:正确的响应由人工注释者编写,指令要么从用户与LLM的交互中收集,要么也是手动创建
数据整合:使用手动创建的模板将现有的监督NLP任务数据集转换为自然语言的 $(\mathrm{instruction}, \mathrm{response})$ 对
基于LLM的合成生成:响应由LLM生成(但可能由人类过滤),而指令要么
- 从用户提示中收集
- 也由LLM基于手动创建的种子提示生成
数据整合:Flan
从2020年开始,发布了几个指令微调数据集,其中基于大量NLP任务数据集的Flan具有高度影响力:
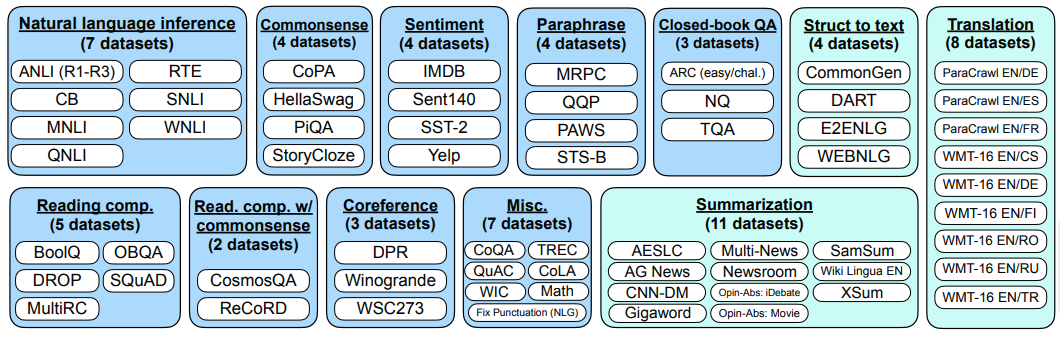
Flan为每个数据集使用10个手动创建的转换模板来转换数据点:

合成生成
像 Self-Instruct [S-I] 这样的激进合成(Synthetic)生成方法使用
- 一个小的手动创建的初始池 种子任务指令(S-I 使用 175 个)和具体示例(S-I 每个任务使用 1 个示例)
- 随机抽取池中的内容来 提示 LLM 生成更多的指令和示例
生成的新指令和示例使用启发式规则进行 过滤,高质量的内容被添加到池中。采样、生成、过滤和池扩展步骤可以 递归重复,直到达到所需的数据集大小。
即使生成器模型是一个普通的 MLE 训练的 LLM,Self-Instruct 风格的合成生成数据集在指令微调中也可以非常有用。报告显示,在 SuperNatural Instructions 数据集上使用 ROUGE-L 评分测量性能,
- 普通 GPT-3 在自生成的 Self-Instruct 数据集上微调后性能提高了 33%
- 它非常接近 InstructGPT 的性能(39.9 对 40.8%)
由于其多样性,它们也可以作为手动创建的指令数据集的有用补充。
基于人类反馈的强化学习
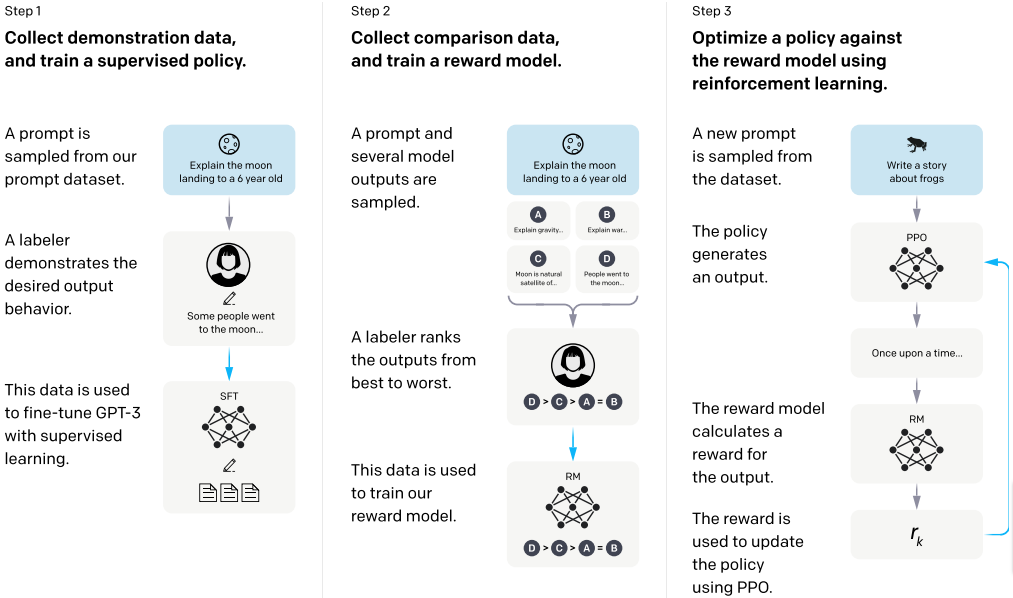
也许最有影响力的方法是 OpenAI 对 GPT-3 微调的方法:
- 起点是一个 MLE 预训练的 GPT-3 和一个 监督数据集,该数据集包含指令提示(从 API 调用中收集)和 手动创建的首选输出示例
- 预训练模型在此数据集上进行 MLE 微调
- 微调模型和标注者的监督信号用于训练一个回归 奖励模型,该模型为提示-响应对分配标量奖励
- 最后,使用奖励模型提供的信号,通过 强化学习 进一步微调模型
将文本生成视为强化学习问题
- 状态 是要继续的标记序列——可能只包含一个 $\langle start \rangle$ 标记
- 动作 是从词汇表中添加一个新标记到序列中,因此 $|\textrm{Actions}|=|\textrm{Vocabulary}|$
- 状态转换 是 确定性 的(添加一个标记确定性地产生扩展序列)
- 策略 基本上是“预测下一个”类型的语言模型,通常是随机的,因为通常有几种替代的续集
- 奖励 通常是稀疏的,即基于整个完成的序列
奖励模型
奖励模型(RM)的起点是一个相对较小的(6B)MLE预训练的GPT版本,该版本也在监督数据集上进行了指令微调
初始奖励模型只是这个语言模型,将其解嵌层替换为回归头
奖励模型在一个手动创建的质量比较数据集上进行训练,该数据集包含监督数据集中提示的替代模型输出对(由MLE微调的大型GPT-3生成)
奖励模型在 $(x, y_{better}, y_{worse})$ 三元组上的损失,其中 $x$ 是从提示数据集中采样的指令,$y_{better}, y_{worse}$ 是两个排序的替代模型输出,是
$$-\log(\sigma(RM_{\Theta}(x, y_{better})-RM_{\Theta}(x, y_{worse})))$$
引导模型为给定的指令提示提供更高的奖励给“更好”的输出。
强化学习训练
最后一步是使用奖励模型通过 强化学习 进一步微调语言模型
使用的算法通常是 近端策略优化(Proximal Policy Optimization PPO),这是一种策略梯度变体,通过将更新剪辑到一定范围来避免进行过大的策略更改
强化学习训练的目标是 最大化 奖励模型对(指令,模型响应)对的预期奖励,但也要 最小化(缩放版本的)策略预测的条件分布与用于初始化的指令语言模型之间的 KL散度
直接偏好优化
(Direct Preference Optimization DPO)
RLHF需要训练一个单独的奖励模型和一个人类反馈循环,这两者都很昂贵。
直接偏好优化 将RL优化问题转化为监督(机器学习)任务。
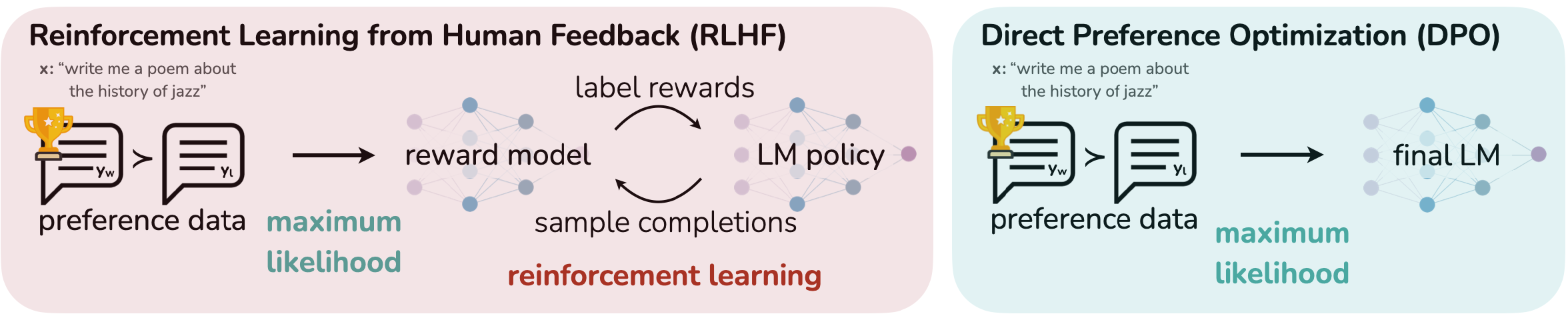
- 重新参数化RL优化问题,以__策略__而不是奖励模型$RM$为基础
- 为策略 $\pi_\theta$ 制定最大似然目标
- 在原始用户判断上通过监督学习优化策略
DPO…
- 表现类似于PPO,有时甚至更好
- 需要的计算量比PPO少5-8倍,内存需求减半
- 对采样温度不太敏感
助手聊天机器人
作为对话系统的指令微调语言模型
近年来,指令数据集生成和微调方法的成功导致了一系列指令微调的大型语言模型的发展:Google的FLAN、OpenAI的InstructGPT、Stanford的Alpaca等。
作为对话系统,这些模型支持的对话具有以下特点:
- 用户发起
- 由正好 两轮 组成
- 其 目标 是 执行描述的任务
- 与传统的任务导向系统相比,没有预定义的领域和任务列表,范围是真正 开放的
Assistant chatbots
指令微调模型最明显的限制是它们不支持 多轮对话,而对齐的大型语言模型的下一个开发周期的主要目标是消除这一限制。
主要解决方案是保持用于指令微调的框架:
- 从一个 MLE预训练的大型语言模型 开始
- 收集一个$D$ 条件文本生成数据集,包含$(x, y)$输入-输出对
- 在$D$上对预训练的大型语言模型进行 微调,使用监督训练和可选的基于RLHF的训练(后者需要额外的数据和奖励模型的训练)
主要区别在于,条件文本生成的输入不是单个指令,而是一个复杂的 助手对话上下文的表示,包括其 历史:
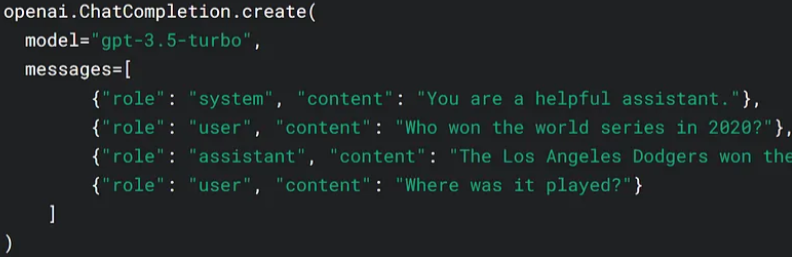
表示对话历史
最简单的表示当然是完整的
$$[u_1, s_1, u_2, \dots, s_{N-1}, u_N]$$
从开始到结束交替出现的用户和系统话语列表,但在非常长的对话情况下,这可能会超过模型的最大输入大小,因此通常会被 截断。
更复杂的解决方案不仅仅是简单地删除对话的早期部分,而是用某种压缩表示来替换它,例如 摘要。
挑战
尽管取得了不可否认的进展,当前基于LLM的开放域辅助聊天机器人仍然可能
- 提供不准确或误导的信息(“幻觉”)
- 产生__冒犯或危险__的输出
- 未能真正尝试执行任务
因此,在 诚实、无害 和 有帮助 方面的进一步对齐仍然是一个活跃的研究领域。
NLP-Alignments